正则表达式知识点总结
第一部分:正则表达式 概念
一个函数: re.findall(pattern, string)
一些元字符: . * ? + [] () \ ^ $
通过 () 来改变 findall 的行为

例1: 判断一个手机号码(长度、开头数字为1、只能是数字)
import re
a=12345678901
def check_phone(phone):
str_ph=str(phone)
# 普通写法
# if str_ph.isdigit() and len(str_ph)==11 and str_ph.startswith('1'):
# 使用正则表达式写法,代码简约了很多
if re.search(r'^1\d{10}$',str_ph): # 第二个参数是个字符串,是对传进去的字符串处理,高效的处理文本
print(str_ph)
else:
print('请输入正确的手机号:')
check_phone(a) # 调用
运行截图:

如果输入a=22345678901
运行截图:

例2:search、match、finall 练习
print(re.search(r'^1\d{10}','222233442')) # r是取消/换行 None
# 从左到右匹配满足条件的
print(re.search(r'5','45455498765'))
# <_sre.SRE_Match object; span=(1, 2), match='5'>
# 从左到右匹配的,匹配第一个55(通过下标从3-5)
print(re.search(r'55','45455498765'))
# <_sre.SRE_Match object; span=(3, 5), match='55'>
# 匹配所有的5
print(re.findall(r'5','45455498765'))
# ['5', '5', '5', '5']
# 匹配开头
print(re.match(r'45','45455498765'))
# <_sre.SRE_Match object; span=(0, 2), match='45'>
print("================================================")
r=re.match(r'45','454554598765')
print(r) # 所匹配的对象
print(r.start()) # 匹配的开始位置
print(r.end()) # 匹配的结束位置
print(r.span()) # 开始和结束位置
print(r.group()) # 所匹配到的字符
print("================================================")
# 43455498765
s='45455498765'
print(s[0:2]) # 用切片切45
print(re.match(r'45','43455498765')) # None
运行截图:

第二部分:元字符
思考:
什么是元字符?
本身具有特殊含义的字符
常用的元字符:. ^ $ {} * + ? | []

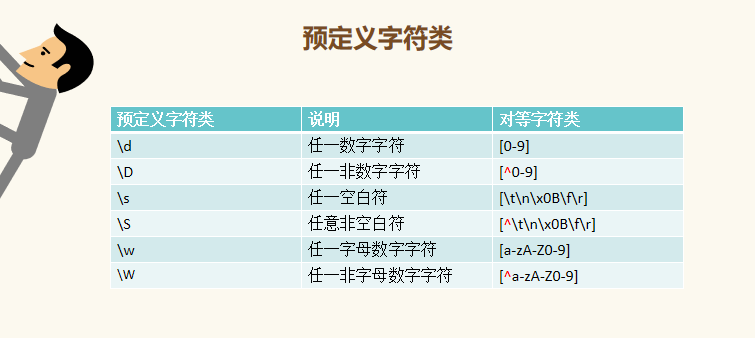
import re
print(re.search(r'.','小平32sswomnm2344553')) # 匹配任意一个字符
# <_sre.SRE_Match object; span=(0, 1), match='小'>
print(re.search(r'\d','小平32sswomnm2344553')) # 匹配数字
# <_sre.SRE_Match object; span=(2, 3), match='3'>
print(re.search(r'\D','小平32sswomnm2344553')) # 匹配非数字
# <_sre.SRE_Match object; span=(0, 1), match='小'>
print(re.search(r'\s','小平\t32sswomnm\n234 4553')) # 匹配空白符
# <_sre.SRE_Match object; span=(2, 3), match='\t'>
print(re.search(r'\s','小 平\t32sswomnm\n234 4553')) # 匹配空白符
# <_sre.SRE_Match object; span=(1, 2), match=' '>
print(re.search(r'\S','小平32sswomnm2344553')) # 匹配非空白符
# <_sre.SRE_Match object; span=(0, 1), match='小'>
print(re.search(r'\w','@_小平32sswomnm2344553')) # 匹配所有除特殊字符以外(@ 为特殊字符)
# <_sre.SRE_Match object; span=(1, 2), match='_'>
print(re.search(r'\W','@_小平32sswomnm2344553')) # 匹配特殊字符
# <_sre.SRE_Match object; span=(0, 1), match='@'>
print(re.search(r'\W','%_小平32sswomnm2344553')) # 匹配特殊字符
print(re.search(r'[0-9]','@_小平32sswomnm2344553')) # 匹配一段范围
# <_sre.SRE_Match object; span=(4, 5), match='3'>
print(re.findall(r'[0-9]','@_小平32sswomnm2344553')) # 匹配一段范围
# ['3', '2', '2', '3', '4', '4', '5', '5', '3']
print(re.search(r'[a-z]','@_小平32sswomnm2344553')) # 匹配一段范围
# <_sre.SRE_Match object; span=(6, 7), match='s'>
print(re.findall(r'[a-z]','@_小平32JLsswomnm2344553')) # 匹配一段范围(小写)
# ['s', 's', 'w', 'o', 'm', 'n', 'm']
print(re.findall(r'[A-z]','@_小平32JLsswomnm2344553')) # 匹配一段范围(大小写)
# ['_', 'J', 'L', 's', 's', 'w', 'o', 'm', 'n', 'm']
print(re.findall(r'[a-z0-9]','@_小平32JLsswomnm2344553'))
# ['3', '2', 's', 's', 'w', 'o', 'mddddddddd', 'n', 'm', '2', '3', '4', '4', '5', '5', '3']
print(re.findall(r'[0-5a-z]','@_小平32JLsswomnm2344553'))
print('=============================================================================')
print(re.findall(r'[*]','@_小平32JL*ss*womnm234*4553')) # 匹配所有*
# ['*', '*']
print(re.findall(r'\.','@_小平32.JL*ss*womnm234*455.3')) # 匹配所有点
# ['.', '.']
print(re.findall(r'4|5','@_小平32JLsswomnm2344553')) # 或
# ['4', '4', '5', '5']
print(re.findall(r'^2','@_小平32JLsswomnm2344553')) # 匹配开头
# []
print(re.findall(r'^2','2@_小平32JLsswomnm2344553')) # 匹配开头
# ['2']
# print(re.findall(r'$2','2@_小平32JLsswomnm2344553')) # 结尾(从左到右查看2应该在$之前)
print(re.findall(r'2$','2@_小平32JLsswomnm23445532'))
# ['2']
print(re.findall(r'\b32','2@_小平,32,JLsswomnm,23445532')) # 单词边界
# ['32']
print('---------------------------------------------------------------------')
print(re.search(r'\b32','2@_小平,32,JLsswomnm,23445532'))
# <_sre.SRE_Match object; span=(6, 8), match='32'>
print(re.search(r'32\b','2@x_小平,32,JLsswomnm,23445532')) # 边界
# <_sre.SRE_Match object; span=(6, 8), match='32'>
print(re.search(r'(234)','2@x_小平,32,JLsswomnm,23445234532'))
# <_sre.SRE_Match object; span=(20, 23), match='234'>
print(re.search(r'234','2@x_小平,32,JLsswomnm,23445234532')) # 可以不写括号
print(re.findall(r'234','2@x_小平,32,JLsswomnm,23445234532')) # ['234', '234']
print(re.findall(r'f(234)','2@x_小平,32,JLsswomnm,23445f234532'))
# ['234'] 匹配f后面的'234' 称为分组匹配(精确匹配)
print('=================================================================================')
print(re.findall(r'2','2@x_小平,32,JLsswomnm,23445f2234532'))
print(re.findall(r'22','2@x_小平,32,JLsswomnm,23445f2234532'))
print(re.findall(r'2{2}','2@x_小平,32,JLsswomnm,23445f2234532')) # {2} 表示个数
# ['22']
print(re.findall(r'2{1,}','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小个数,无穷大(最大不写的情况下)
# ['2', '2', '2', '22222', '222']
print(re.findall(r'2{1,2}','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小个数为一个2,最大个数为两个2
# ['2', '2', '2', '22', '22', '2', '22', '2']
print(re.findall(r'2{0,2}','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小个数为空,最大个数为两个2
# ['2', '', '', '', '', '', '', '', '2', '', '', '', '', '', '', '', '', '', '', '', '2', '', '',
# '', '', '', '22', '22', '2', '', '', '', '', '22', '2', '']
print(re.findall(r'2*','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小0 ,最大无穷大
print(re.findall(r'2+','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小个数为一个 ,最大无穷大
# ['2', '2', '2', '22222', '222']
print(re.findall(r'2?','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小0 ,最大1个
# ['2', '', '', '', '', '', '', '', '2', '', '', '', '', '', '', '', '', '', '', '', '2', '',
# '', '', '', '', '2', '2', '2', '2', '2', '', '', '', '', '2', '2', '2', '']
print(re.findall(r'2{0,1}','2@x_小平,32,JLsswomnm,23445f222223453222')) # 最小0 ,最大1个
# ['2', '', '', '', '', '', '', '', '2', '', '', '', '', '', '', '', '', '', '', '', '2',
# '', '', '', '', '', '2', '2', '2', '2', '2', '', '', '', '', '2', '2', '2', '']
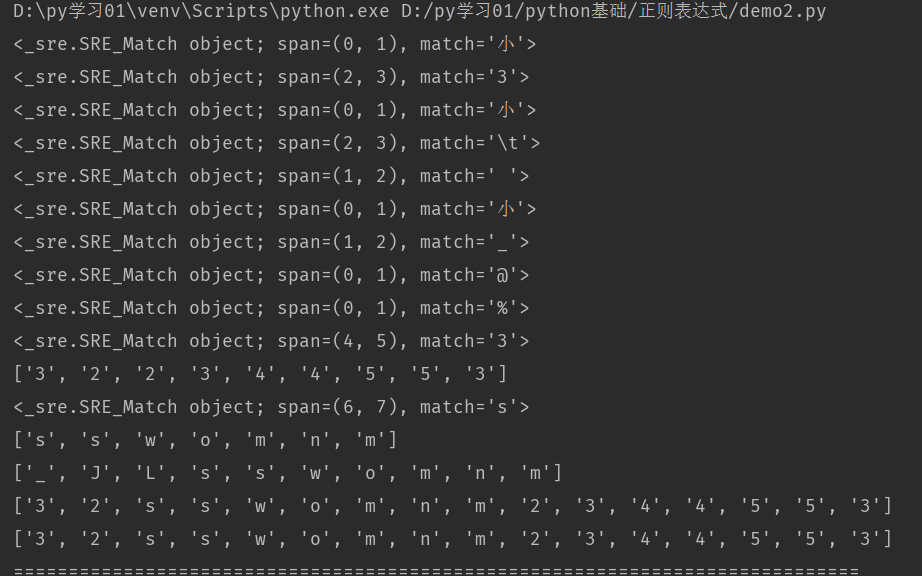
运行截图(部分):

贪婪模式:(匹配满足表达式的最大内容)
import re
print(re.findall(r'<.*>','<div><p><p><div>')) # .代表任意字符,* 所有 匹配到所有
# ['<div><p><p><div>']
print(re.findall(r'<.*>','<div><p><p><div><span>'))# 查找的过去又回来
# ['<div><p><p><div><span>']
# 非贪婪模式:匹配满足表达式的最小内容
print(re.findall(r'<.*?>','<div><p><p><div><span>'))
# ['<div>', '<p>', '<p>', '<div>', '<span>']
运行截图:

========每天最大的兴趣就是赚钱、写代码、学知识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号