
面向对象阶段总结之总结 | 爬着玩
第二次博客作业已经截止提交了,同学们用各有特色的口吻对前面的三次代码作业进行了详尽地总结,饶有趣味。这些博客文章之间有什么有意思的共同点吗?我决定派出一只小蜘蛛一探究竟。我对所有的同学的第二次博客作业进行了爬取,依据文本分析切分出了词汇,并进行了词频统计,最终依据统计结果画出了一幅云图。看起来博客园对于爬虫还是很友好的,作为一只新手蜘蛛,笨手笨脚地爬来爬去试了很多遍,没有使用代理,一路竟然没有遇到任何阻碍。
效果展示
班级作业
依据词频为大家的作业绘制的云图如下:

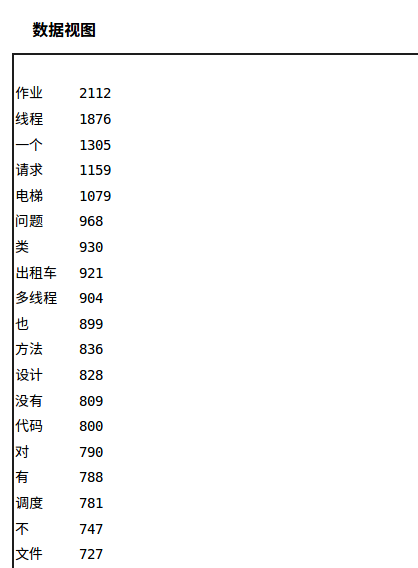
可以看到出现最多的词汇是“作业”,在200多份博客中足足出现了2112次。仅随其后的是“线程”,出现了1876次,同类词汇“多线程”出现了904次。三次作业的主体,“电梯”出现了1079次,“出租车”出现了921次,“文件”出现了727次,也可见大家最喜欢讨论的是第五次作业多线程电梯。
此外,出现次数较少的词汇是大家使用的比较个性的词汇(由于是直接按照博客目录逐页爬取的,有些明显和作业无关的词语来自非本次作业但是在班级博客目录中的文章),在此截取一小部分,有兴趣的话可以点击数据视图查看。(猜不透“吃”字为什么会出现5次之多……)

个人作业
我顺手单独为自己的博客做了一下分析:

结果惊人,我使用次数最多的词汇不是“线程”也不是“多线程”,而是“一个”,足足有26次,这可能是我的一个比较冗余的说话习惯,今后应当多加注意。除此之外我使用比较多的词有“文件”(21),作业(19),调度(16),对象(15),可能是我对第六次作业不太满意,因此大篇幅讨论了‘IFTTT’,“文件”出现频率较高,“电梯”和“出租车”出现的频率反而比较低。
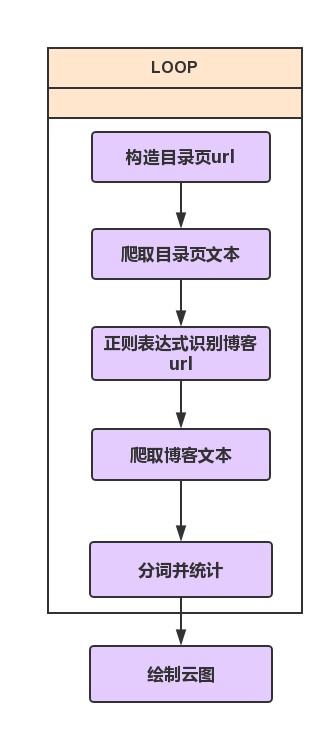
实现思路
整个流程如下图所示:
参考代码
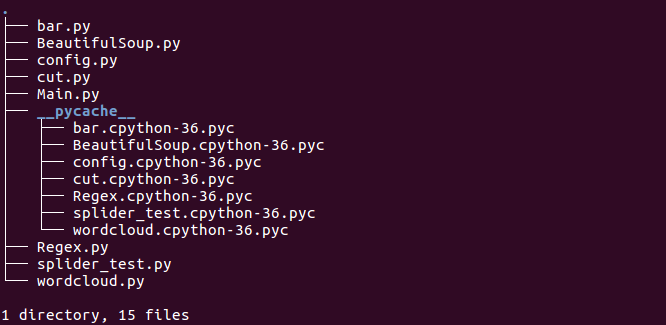
目录结构
程序的完整目录结构如下:
Main
主函数代码如下:
# -*- coding:utf-8 -*-
import splider_test
import BeautifulSoup
import config
import Regex
import wordcloud
def home_handle(home_url,dic):
list_blog = BeautifulSoup.home_parse(home_url)
for url in list_blog:
if (Regex.url_judge(url)):
print("Begin handling:\t", url)
str_html = splider_test.splider(url)
BeautifulSoup.parse(str_html,dic)
home_base = 'https://edu.cnblogs.com/campus/buaa/OO2018'
dic = {}
for i in range(1,24):
home_url = ''
if(i==1):
home_url = home_base
else:
home_url = home_base+"?page="+str(i)
home_handle(home_url,dic)
list_sort = sorted(dic.items(), key=lambda e: e[1], reverse=True)
list_word = []
list_count = []
config.trans(list_word,list_count,list_sort)
wordcloud.draw(list_word,list_count)
其中获取大家博客url的目录页使用的就是班级页面的“最新博文”,我发现每一页的url前面是不变的,只是后面的page参数发生了变化,因此使用一个for循环就可以很轻易的构造出所有目录页的url了。
BeautifulSoup
在我写正则表达式写得即将放弃的时候我发现了这碗BeautifulSoup,它是一个HTML的解析库,可以用它来方便地从网页中提取数据,功能强大到让人感动。由于我也是昨天刚会用就不在这里瞎介绍了,感兴趣的同学可以自行搜索一下。
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import cut
import re
import splider_test
import Regex
def parse(str_html,dic):
soup = BeautifulSoup(str_html, "lxml")
for p in soup.find_all(name="p"):
if(p.string!=None):
string = re.sub('[\s+\.\!\/_,$%^*(+\"\'):-;|]+|[+——!,。?、~@#¥%……&*():;]+','',p.string)
string = re.sub(u'的|我|在|了|是|和|就|中','',string)
count(dic,string)
def count(dic,string):
str_list = cut.cut_str(string)
for item in str_list:
if item in dic:
dic[item]+=1
else:
dic[item]=1
def home_parse(url):
list_url = []
str_html = splider_test.splider(url)
soup = BeautifulSoup(str_html,'lxml')
list_h3 = soup.find_all(attrs={'class':'am-list-item-hd'})
for item in list_h3:
list_url.append(Regex.url_match(str(item)))
return list_url
在解析文本的时候过滤了一些出现频率比较高的标点符号和中文虚词。
cut
中文分词我使用的是一个叫做“结巴”的中文分词组件,不得不再次感慨python的强大,切分中文单词这么复杂的工作我只写了两行代码,短得我都有点不好意思了哈哈哈。
# -*- coding:utf-8 -*-
import jieba
def cut_str(string):
return jieba.lcut(string)
Regex
正则表达式用来辅助BeautifulSoup识别url.
# -*- coding:utf-8 -*-
import re
def url_match(string):
REGEX = 'http:.*?html'
result = re.search(REGEX,string,re.U)
return result.group()
def url_judge(string):
REGEX = 'http:.*?html'
if(re.match(REGEX,string,re.U)):
return True
else:
return False
wordcloud
绘制云图使用的是pyecharts,pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化。
# -*- coding:utf-8 -*-
from pyecharts import WordCloud
def draw(list_word,list_count):
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", list_word, list_count, word_size_range=[20, 100])
print("wordcloud succeed!")
wordcloud.render("WordCloud.html")
改进方向
- 由于是写着玩,因此写得比较粗糙,例如爬虫是很容易失败的,但是代码并没有进行任何异常处理,如果遇到不太友好的网站,可能就不太顺利了。
- 手工过滤了一部分出现频率最高的中文虚词和标点,但是仍旧残留了一些虚词(“也”,“但”,“还”等等),如何识别虚词和实词是一个问题。
- 可以看到大部分同学的博客阅读量分布在[10,20]区间内,但是存在一些阅读量相当高的博客,此外点赞人数占阅读量的比例也可以作为一个参数,下一步希望能通过爬取阅读量和点赞量找到比较受欢迎的博客,然后再对这些博客进行词频分析。

