python爬虫
Urllib
2021年12月9日
20:21
Python urllib
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
本文主要介绍 Python3 的 urllib。
urllib 包 包含以下几个模块:
- urllib.request - 打开和读取 URL。
- urllib.error - 包含 urllib.request 抛出的异常。
- urllib.parse - 解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。

urllib.request - 打开和读取 URL。
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
Response = urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
-
url:url 地址。
-
data:发送到服务器的其他数据对象,默认为 None。当data有传数据是就是用的post请求 data=bytes(urllib.parse.urlencode({'zoom':'12'}),encoding='utf8')
-
timeout:设置访问超时时间。
-
cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
-
context:ssl.SSLContext类型,用来指定 SSL 设置。
读取数据:
Response .read() 是读取整个网页内容,我们可以指定读取的长度:
Response .readline() - 读取文件的一行内容
Response .readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
设置编码
Response .read().decode('utf8')
请求头和编码:
Response.status 获取状态码:
Response.getheaders() 获取全部请求头:
Response.getheader(key) 获取指定请求头参数:
模拟头部信息
我们抓取网页一般需要对 headers(网页头信息)进行模拟,这时候需要使用到 urllib.request.Request 类:
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- headers:HTTP 请求的头部信息,字典格式。
- origin_req_host:请求的主机地址,IP 或域名。
- unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是False。。
- method:请求方法, 如 GET、POST、DELETE、PUT等。
import`` ``urllib.request
import`` ``urllib.parse
url`` ``=`` ``'`https://www.runoob.com/?s=`'`` ``# ``菜鸟教程搜索页面
keyword`` ``=`` ``'Python ``教程``'
key_code`` ``=`` ``urllib.request.quote(keyword)`` ``# ``对请求进行编码
url_all`` ``=`` ``url+key_code
header`` ``=`` ``{
``'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}`` ``#``头部信息
request`` ``=`` ``urllib.request.Request(url_all,headers=header)
reponse`` ``=`` ``urllib.request.urlopen(request).read()
fh`` ``=`` ``open("./urllib_test_runoob_search.html","wb")`` ``# ``将文件写入到当前目录中
fh.write(reponse)
fh.close()
可以用于下载urlretrieve
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
函数说明
将``URL``表示的网络对象复制到本地文件。如果``URL``指向本地文件,则对象将不会被复制,除非提供文件名。返回一个元组``()(filename``,``header)``,其中``filename``是可以找到对象的本地文件名,``header``是``urlopen()``返回的对象的``info()``方法``(``用于远程对象``)``。
第二个参数``(``如果存在``)``指定要复制到的文件位置``(``如果没有,该位置将是一个生成名称的``tempfile)``。第三个参数,如果存在,则是一个回调函数,它将在建立网络连接时调用一次,并且在此后每个块读取后调用一次。这个回调函数将传递三个参数``;``到目前为止传输的块计数,以字节为单位的块大小,以及文件的总大小。第三个参数可能是``-1``,在旧的``FTP``服务器上,它不返回文件大小以响应检索请求。
参数说明
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
urllib.error - 包含 urllib.request 抛出的异常。
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
对不存在的网页抓取并处理异常:
urllib.parse - 解析 URL。
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme=' ', allow_fragments=True)
urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
| scheme | 0 | URL协议 | scheme 参数 |
| netloc | 1 | 网络位置部分 | 空字符串 |
| path | 2 | 分层路径 | 空字符串 |
| params | 3 | 最后路径元素的参数 | 空字符串 |
| query | 4 | 查询组件 | 空字符串 |
| fragment | 5 | 片段识别 | 空字符串 |
| username | 用户名 | None | |
| password | 密码 | None | |
| hostname | 主机名(小写) | None | |
| port | 端口号为整数(如果存在) | None |
urllib.robotparser`` ``- ``解析`` robots.txt ``文件。
urllib.robotparser ``用于解析`` robots.txt ``文件。
robots.txt``(统一小写)是一种存放于网站根目录下的`` robots ``协议,它通常用于告诉搜索引擎对网站的抓取规则。
urllib.robotparser ``提供了`` RobotFileParser ``类,语法如下:
class urllib.robotparser.RobotFileParser(url='')
url编码
from urllib import parse
\#数据对象
data = {
"a":"1",
"b":"3",
"x":"张三",
"y":"李四"
}
\#进行url_encode编码,编码结果为查询字符串形式,即进行url编码,然后用a=1&b=2形式拼接键值对
text = parse.urlencode(data)
print(text)
\#进行url解码,但是不会将拼接形式转换为字典形式
text1 = parse.unquote(text)
print(text1)
\#进行url编码,但是这步会将&与=一起转码
text2 = parse.quote(text1)
print(text2)
a = "我是大侦探"
\#url编码
b = parse.quote(a)
print(b)
\#url解码
c = parse.unquote(b)
print(c)
Urllib3
2021年12月9日
20:52
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
1、 线程安全
2、 连接池
3、 客户端SSL/TLS验证
4、 文件分部编码上传
5、 协助处理重复请求和HTTP重定位
6、 支持压缩编码
7、 支持HTTP和SOCKS代理
8、 100%测试覆盖率
安装:
Urllib3 能通过pip来安装:
pip`` ``install`` ``urllib3
请求:
您需要一个PoolManager实例来发出请求。此对象处理连接池和线程安全的所有详细信息,http=urllib3.PoolManager()
要进行请求使用:
Aaa =http。request(‘请求方式’,url,fields,headers,timeout,retries)
请求方式:GET,POST,等
Url :网站地址,
fields:表单参数,用于向表单项提交,
Headers : 请求头参数:是一个字典存储的
timeout:请求超时时几秒以后不在请求了
retries:请求重试的次数,当超过最大请求时间时如果设置了就会去重新请求要禁用所有重试和重定向逻辑,请指定:retries=False
响应:
获取二进制数据:``aaa``。``Data
获取响应状态:``aaa``。``status
获取响应请求头:`` aaa``。``Headers
info()``:``方法``获取响应头信息。
数据转格式,编码:
data.decode('utf-8')
get
使用``urllib3``发送网络请求时,需要首先创建``PoolManager``对象,再通过该对象调用`` request() ``方法发送请求。
request(method,url,fields=None,headers=None)
method ``必选参数,用于指定请求方式,如``GET``,``POST``,``PUT``等。
url ``必须按参数,要访问的``url
fields ``可选参数,设置请求的参数
headers ``可选参数,请求头
import urllib3 # ``导入``urllib3``模块
url = '`https://www.python.org/`'
http = urllib3.PoolManager() # ``创建连接池管理对象
r = http.request('GET', url) # ``发送``GET``请求
print(r.status) # ``打印请求状态码
Post
发送post请求同样使用request方法,只需要将request方法中的method参数设置为POST,将fields参数设置为字典类型的表单参数。
import urllib3 # ``导入``urllib3``模块
urllib3.disable_warnings() # ``关闭``ssl``警告
url = '`https://www.httpbin.org/post`' # post``请求测试地址
params = {'name': 'Jack', 'country': '``中国``', 'age': 30} # ``定义字典类型的请求参数,这里可以随意写进行测试
http = urllib3.PoolManager() # ``创建连接池管理对象
r = http.request('POST', url, fields=params) # ``发送``POST``请求
print('``返回结果:``', r.data.decode('utf-8'))
可以看出表单中的"中国"两个汉字没有正常显示。而是显示了一段unicode编码,对此可以将编码方式设置为unicode_escape。
print(r.data.decode('unicode_escape'))
设置连接超时与读取超时。
重试请求
import urllib3 # ``导入``urllib3``模块
urllib3.disable_warnings() # ``关闭``ssl``警告
url = '`https://www.httpbin.org/get`' # get``请求测试地址
http = urllib3.PoolManager() # ``创建连接池管理对象
r = http.request('GET', url) # ``发送``GET``请求``,``默认重试请求
r1 = http.request('GET', url, retries=5) # ``发送``GET``请求``,``设置``5``次重试请求
r2 = http.request('GET', url, retries=False) # ``发送``GET``请求``,``关闭重试请求
print('``默认重试请求次数:``', r.retries.total)
print('``设置重试请求次数:``', r1.retries.total)
print('``关闭重试请求次数:``', r2.retries.total)
设置超时
import urllib3 # ``导入``urllib3``模块
urllib3.disable_warnings() # ``关闭``ssl``警告
baidu_url = '`https://www.baidu.com/`' # ``百度 超时请求测试地址
python_url = '`https://www.python.org/`' # Python ``超时请求测试地址
http = urllib3.PoolManager() # ``创建连接池管理对象
try:
r = http.request('GET', baidu_url, timeout=0.01) # ``发送``GET``请求,并设置超时时间为``0.01``秒
except Exception as error:
print('``百度超时:``', error)
http2 = urllib3.PoolManager(timeout=0.1) # ``创建连接池管理对象``,``并设置超时时间为``0.1``秒
try:
r = http2.request('GET', python_url) # ``发送``GET``请求
except Exception as error:
print('Python``超时:``', error)
设置连接超时与读取超时。
方法一:
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager(timeout=timeout)
http.request('GET', "`https://www.python.org/`")
方法二:
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager()
http.request('GET', "`https://www.python.org/`", timeout=timeout)
设置代理
设置代理IP需要创建ProxyManager对象,该对象需要有两个参数;proxy_url表示需要使用的代理IP,headers即请求头。
import urllib3 # ``导入``urllib3``模块
url = "`http://httpbin.org/ip`" # ``代理``IP``请求测试地址
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
# ``创建代理管理对象
proxy = urllib3.ProxyManager('xxxxxxxxxxxx', headers=headers)
r = proxy.request('get', url, timeout=2.0) # ``发送请求
print(r.data.decode()) # ``打印返回结果
上传文件
request()``方法提供了两种比较常用的文件上传方式:
①``一种是通过``fields``参数以元组的形式分别指定文件名、文件内容以及文件类型
②``另一种指定``body``参数,该参数对应值为图片的二进制数据,然后还需要``headers``参数指定文件类型
上传txt
import urllib3 # ``导入``urllib3``模块
import json # ``导入``json``模块
with open('test.txt') as f: # ``打开文本文件
data = f.read() # ``读取文件
http = urllib3.PoolManager() # ``创建连接池管理对象
# ``发送网络请求
r = http.request('POST', '`http://httpbin.org/post`', fields={'filefield': ('example.txt', data),})
files = json.loads(r.data.decode('utf-8'))['files'] # ``获取上传文件内容
print(files)
上传图片
import urllib3 # ``导入``urllib3``模块
with open('python.jpg', 'rb') as f: # ``打开图片文件
data = f.read() # ``读取文件
http = urllib3.PoolManager() # ``创建连接池管理对象
# ``发送请求
r = http.request('POST', '`http://httpbin.org/post`', body=data, headers={'Content-Type': 'image/jpeg'})
print(r.data.decode()) # ``打印返回结果
Request
2021年12月9日
20:21
基本GET请求(headers参数 和 parmas参数)
1. 最基本的GET请求可以直接用get方法
response = requests.get("http://www.baidu.com/")
# 也可以这么写
# response = requests.request("get", "http://www.baidu.com/")
2. 添加 headers 和 查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests
kw = {'wd':'长城'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
\# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers)
\# 查看响应内容,response.text 返回的是Unicode格式的数据
print response.text
\# 查看响应内容,response.content返回的字节流数据
print respones.content
# 查看完整url地址
print response.url
# ``查看响应头部字符编码
print response.encoding
# ``查看响应码
print response.status_code
# print(res.request.headers) # ``查看请求的请求头
# print(res.headers) # ``查看响应头
# print(res.request.cookies) # ``查看请求的``cookie
# print(res.cookies) # ``查看响应的``cookies
利用params参数发送带参数的请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"
}
# ``最后有没有问号结果都一样
url = '`https://www.baidu.com/s?`'
# ``请求参数是一个字典 即``wd=python
kw = {'wd': 'python'}
# ``带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
# ``当有多个请求参数时,``requests``接收的``params``参数为多个键值对的字典,比如
'?wd=python&a=c'-->{'wd': 'python', 'a': 'c'}
print(response.content)

基本POST请求(data参数)
1. 最基本的GET请求可以直接用post方法
response = requests.post("http://www.baidu.com/", data = data)
2. 传入data数据
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
import requests
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data = formdata, headers = headers)
print response.text
\# 如果是json文件可以直接显示
print response.json()
代理(proxies参数)

正向代理和反向代理
正向代理:给客户端做代理,隐藏客户端的``ip``地址,让服务器不知道客户端的真实``ip``地址
反向代理``: ``给服务器做代理,隐藏服务器的真实``ip``地址,同时可以实现负载均衡,处理静态文件请求等作用``,``比如``nginx
代理IP的分类
根据代理``ip``的匿名程度,代理``IP``主要可以分为下面三类:
1.``透明代理``(Transparent Proxy)``:透明代理虽然可以直接``“``隐藏``”``你的``IP``地址,但是还是可以查到你是谁。
2.``匿名代理``(Anonymous Proxy)``:使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
3.``高匿代理``(Elite proxy``或``High Anonymity Proxy)``:高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
import requests
# 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
私密代理验证(特定格式) 和 Web客户端验证(auth 参数)
urllib2 这里的做法比较复杂,requests只需要一步:
私密代理
import requests
# 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = { "http": "mr_mao_hacker:sffqry9r@61.158.163.130:16816" }
response = requests.get("http://www.baidu.com", proxies = proxy)
print response.text
web客户端验证
如果是Web客户端验证,需要添加 auth = (账户名, 密码)
import requests
auth=('test', '123456')
response = requests.get('http://192.168.199.107', auth = auth)
print response.text
Cookies 和 Sission
Cookies
如果一个响应中包含了cookie,那么我们可以利用 cookies参数拿到:
import requests
response = requests.get("http://www.baidu.com/")
# 7. 返回CookieJar对象:
cookiejar = response.cookies
# 8. 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print cookiejar
print cookiedict
Sission
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
实现人人网登录
import requests
# 1. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2. 处理 headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 3. 需要登录的用户名和密码
data = {"email":"mr_mao_hacker@163.com", "password":"alarmchime"}
# 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("http://www.renren.com/PLogin.do", data = data)
# 5. ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面
response = ssion.get("http://www.renren.com/410043129/profile")
# 6. 打印响应内容
print response.text
处理HTTPS请求 SSL证书验证
Requests也可以为HTTPS请求验证SSL证书:
- 要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写)
import requests
response = requests.get("https://www.baidu.com/", verify=True)
# 也可以省略不写
# response = requests.get("https://www.baidu.com/")
print r.text
如果我们想跳过 12306 的证书验证,把 verify 设置为 False 就可以正常请求了。
响应信息如下:
| 属性或方法 | 说明 |
|---|---|
| apparent_encoding | 编码方式 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据 |
| url | 返回响应的 URL |
Bs4
2021年12月9日
20:21
概述
bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签。
一、初始化
From bs4 import BeautifulSoup
soup = BeautifulSoup(html内容, "解析器")
两个参数:第一个参数是要解析的html文本,第二个参数是使用那种解析器,对于HTML来讲就是html.parser,这个是bs4自带的解析器。
如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的。
| 解析器 | 使用方法 | 优势 |
|---|---|---|
| Python标准库 | BeautifulSoup(html, "html.parser") | 1、Python的内置标准库 2、执行速度适中 3、文档容错能力强 |
| lxml HTML | BeautifulSoup(html, "lxml") | 1、速度快 2、文档容错能力强 |
| lxml XML | BeautifulSoup(html, ["lxml", "xml"]) BeautifulSoup(html, "xml") | 1、速度快 2、唯一支持XML的解析器 |
| html5lib | BeautifulSoup(html, "html5lib") | 1、最好的容错性 2、以浏览器的方式解析文档 3、生成HTML5格式的文档 |
格式化输出
soup.prettify() # prettify 有括号和没括号都可以
Find_all
字符串
查找所有的标签
soup.find_all('b') # [The Dormouse's story]
正则表达式
传入正则表达式作为参数,返回满足正则表达式的标签。下面例子中找出所有以b开头的标签。
soup.find_all(re.compile("^b")) # [The Dormouse's story]
列表
传入列表参数,将返回与列表中任一元素匹配的内容。下面例子中找出所有标签和标签。
soup.find_all(["a", "b"])
True
True可以匹配任何值,下面的代码查找到所有的tag,但是不会返回字符串节点。
soup.find_all(True)
方法
如果没有合适过滤器,那么还可以自定义一个方法,方法只接受一个元素参数,如果这个方法返回True表示当前元素匹配被找到。下面示例返回所有包含 class 属性但不包含 id 属性的标签。
def has_class_but_no_id(tag):
returntag.has_attr('class') andnottag.has_attr('id')
print(soup.find_all(has_class_but_no_id))
案例
soup.find('div',class_='song')# 属性定位:根据树新定位具体的标签,class属性为song的div标签,因为class是内置属性,所以要加下划线class_,如果是id则直接用id='xxx'
soup.finAll('a',id='feng')
find 和 find_all
搜索当前 tag 的所有 tag 子节点,并判断是否符合过滤器的条件
语法:
find(name=None, attrs={}, recursive=True, text=None, **kwargs)
find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
参数:
name:查找所有名字为 name 的 tag,字符串对象会被自动忽略掉。上面过滤器示例中的参数都是 name 参数。当然,其他参数中也可以使用过滤器。
attrs:按属性名和值查找。传入字典,key 为属性名,value 为属性值。
recursive:是否递归遍历所有子孙节点,默认 True。
text:用于搜索字符串,会找到 .string 方法与 text 参数值相符的tag,通常配合正则表达式使用。也就是说,虽然参数名是 text,但实际上搜索的是 string 属性。
limit:限定返回列表的最大个数。
kwargs:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作 tag 的属性来搜索。这里注意,如果要按 class 属性搜索,因为 class 是 python 的保留字,需要写作 class_。
获取文本属性:
textDate=pinjiao1.find('ul').text #find().text即可获取文本
textDate=pinjiao1.findAll('ul') #爬取所有含有ul标签的字段
For i in textDate:
print(i.get_text()) #即可获取所有文本
Sub.get(属性名)可以获得属性
二、对象
Beautfiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:tag,NavigableString,BeautifulSoup,Comment。
1、tag
Tag对象与 xml 或 html 原生文档中的 tag 相同。
通过标签取值
如果不存在,则返回 None,如果存在多个,则返回第一个。
Attributes
tag ``的属性是一个字典
取到指定的标签以后可以通过
tag.attrs来查看所有属性
取值方式和字典一样
多值属性
最常见的多值属性是class,多值属性的返回 list。
当一个属性中有多个值得时候,会返回那个属性值得列表形式
如果某个属性看起来好像有多个值,但在任何版本的HTML定义中都没有被定义为多值属性,那么Beautiful Soup会将这个属性作为字符串返回。
Text
text 属性返回 tag 的所有字符串连成的字符串。
tag.has_attr('id') # 返回 tag 是否包含 id 属性
2、NavigableString
字符串常被包含在 tag 内,Beautiful Soup 用 NavigableString 类来包装 tag 中的字符串。但是字符串中不能包含其他 tag。
3、BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象。但是 BeautifulSoup 对象并不是真正的 HTM L或 XML 的 tag,它没有attribute属性,name 属性是一个值为“[document]”的特殊属性。
4、Comment
Comment 一般表示文档的注释部分。
三、遍历
1、子节点
contents 属性
contents 属性返回所有子节点的列表,包括 NavigableString 类型节点。如果节点当中有换行符,会被当做是 NavigableString 类型节点而作为一个子节点。
NavigableString 类型节点没有 contents 属性,因为没有子节点。
children 属性
children 属性跟 contents 属性基本一样,只不过返回的不是子节点列表,而是子节点的可迭代对象。
descendants 属性
descendants 属性返回 tag 的所有子孙节点。
string 属性
如果 tag 只有一个 NavigableString 类型子节点,那么这个 tag 可以使用 .string 得到子节点。
如果一个 tag 仅有一个子节点,那么这个 tag 也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
如果 tag 包含了多个子节点,tag 就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None。
strings 和 stripped_strings 属性
如果 tag 中包含多个字符串,可以用 strings 属性来获取。如果返回结果中要去除空行,则可以用 stripped_strings 属性。
2****、父节点
parent 属性
parent 属性返回某个元素(tag、NavigableString)的父节点,文档的顶层节点的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的父节点是 None。
parents 属性
parent 属性递归得到元素的所有父辈节点,包括 BeautifulSoup 对象。
3****、兄弟节点
next_siblings 和 previous_siblings
next_siblings 返回后面的兄弟节点
previous_siblings 返回前面的兄弟节点
4****、回退和前进
把html解析看成依次解析标签的一连串事件,BeautifulSoup 提供了重现解析器初始化过程的方法。
next_element 属性指向解析过程中下一个被解析的对象(tag 或 NavigableString)。
previous_element 属性指向解析过程中前一个被解析的对象。
另外还有next_elements 和 previous_elements 属性,不赘述了。
4、其他搜索方法
find_parents() 返回所有祖先节点
find_parent() 返回直接父节点
find_next_siblings() 返回后面所有的兄弟节点
find_next_sibling() 返回后面的第一个兄弟节点
find_previous_siblings() 返回前面所有的兄弟节点
find_previous_sibling() 返回前面第一个兄弟节点
find_all_next() 返回节点后所有符合条件的节点
find_next() 返回节点后第一个符合条件的节点
find_all_previous() 返回节点前所有符合条件的节点
find_previous() 返回节点前所有符合条件的节点
css选择器:
\# 通过tag查找
print(soup.select('title')) # [<title>标题</title>]
\# 通过tag逐层查找
print(soup.select("html head title")) # [<title>标题</title>]
\# 通过class查找
print(soup.select('.sister'))
\# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>,
\# <a class="sister" href="http://example.com/2" id="link2">链接2</a>,
\# <a class="sister" href="http://example.com/3" id="link3">链接3</a>]
\# 通过id查找
print(soup.select('#link1, #link2'))
\# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>,
\# <a class="sister" href="http://example.com/2" id="link2">链接2</a>]
\# 组合查找
print(soup.select('p #link1'))
\# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>
]# 查找直接子标签
print(soup.select("head > title")) # [<title>标题</title>]
print(soup.select("p > #link1"))
\# [<a class="sister" href="http://example.com/1" id="link1">链接1</a>]
print(soup.select("p > a:nth-of-type(2)"))# [<a class="sister" href="http://example.com/2" id="link2">链接2</a>]
\# nth-of-type 是CSS选择器
\# 查找兄弟节点(向后查找)
print(soup.select("#link1 ~ .sister"))
\# [<a class="sister" href="http://example.com/2" id="link2">链接2</a>,
\# <a class="sister" href="http://example.com/3" id="link3">链接3</a>]
print(soup.select("#link1 + .sister"))
\# [<a class="sister" href="http://example.com/2" id="link2">链接2</a>]
\# 通过属性查找
print(soup.select('a[href="http://example.com/1"]'))
\# ^ 以XX开头
print(soup.select('a[href^="http://example.com/"]'))
\# * 包含
print(soup.select('a[href*=".com/"]'))
\# 查找包含指定属性的标签
print(soup.select('[name]'))
\# 查找第一个元素
print(soup.select_one(".sister)
soup.div # 标签定位
soup.find('div',class_='song')# 属性定位:根据树新定位具体的标签,class属性为song的div标签,因为class是内置属性,所以要加下划线class_,如果是id则直接用id='xxx'
soup.finAll('a',id='feng')
soup.select('#feng')# 根据 id选择器定位a标签
soup.select('.song')# 定位class为song的标签
#层级选择器
soup.select('.tang > ul > li > a')# >表示一个层级
soup.select('.tang a')# 空格表示多个层级
soup.p.string# 取出p标签直系的文本内容
soup.div.text# 取出div标签中所有的文本内容
soup.a['href']# 取出按标签属性为href的数
Lxml/xpath
2021年11月21日
15:23
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
python安装:
Pip install lxml

XPath中的运算符
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| or | 或 | age=19 or age=20 | 如果age等于19或者等于20则返回true反正返回false |
| and | 与 | age>19 and age<21 | 如果age等于20则返回true,否则返回false |
| mod | 取余 | 5 mod 2 | 1 |
| | | 取两个节点的集合 | //book | //cd | 返回所有拥有book和cd元素的节点集合 |
| + | 加 | 6+4 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 6*4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | age=19 | true |
| != | 不等于 | age!=19 | true |
| < | 小于 | age<19 | true |
| <= | 小于或等于 | age<=19 | true |
| > | 大于 | age>19 | true |
| >= | 大于或等于 | age>=19 | true |
XPath 轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
步(step)包括:
轴(``axis``)
定义所选节点与当前节点之间的树关系
节点测试(``node-test``)
识别某个轴内部的节点
零个或者更多谓语(``predicate``)
更深入地提炼所选的节点集
步的语法:
轴名称::节点测试[谓语]
实例
| 例子 | 结果 |
|---|---|
| child::book | 选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang | 选取当前节点的 lang 属性。 |
| child:😗 | 选取当前节点的所有子元素。 |
| attribute:😗 | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child:😗/child::price | 选取当前节点的所有 price 孙节点。 |
位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:
/step/step/...
相对位置路径:
step/step/...
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
获取父节点
我们知道通过连续的/或者//可以查找子节点或子孙节点,那么要查找父节点可以使用..来实现也可以使用parent::来获取父节点
'''html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//a[@href="link2.html"]/../@class')
result1=html.xpath('//a[@href="link2.html"]/parent:😗/@class')
属性匹配
在选取的时候,我们还可以用@符号进行属性过滤。比如,这里如果要选取class为item-1的li节点,可以这样实现:
文本获取
我们用XPath中的text()方法获取节点中的文本
result=html.xpath('//li[@class="item-1"]/a/text()') #``获取``a``节点下的内容
result1=html.xpath('//li[@class="item-1"]//text()') #``获取``li``下所有子孙节点的内容
属性获取
使用@符号即可获取节点的属性,如下:获取所有li节点下所有a节点的href属性
result=html.xpath('//li/a/@href') #获取a的href属性
result=html.xpath('//li//@href') #获取所有li子孙节点的href属性
属性多值匹配
如果某个属性的值有多个时,我们可以使用contains()函数来获取
from lxml import etree
text1='''
<ul>
<li class="aaa item-0"><a href="link1.html">``第一个``</a></li>
<li class="bbb item-1"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[@class="aaa"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa")]/a/text()')
print(result)
print(result1)
#``通过第一种方法没有取到值,通过``contains``()就能精确匹配到节点了
[]
['``第一个``']
多属性匹配
另外我们还可能遇到一种情况,那就是根据多个属性确定一个节点,这时就需要同时匹配多个属性,此时可用运用and运算符来连接使用:
from lxml import etree
text1='''
<ul>
<li class="aaa" name="item"><a href="link1.html">``第一个``</a></li>
<li class="aaa" name="fore"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[@class="aaa" and @name="fore"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa") and @name="fore"]/a/text()')
print(result)
print(result1)
#
['second item']
['second item']
按序选择
有时候,我们在选择的时候某些属性可能同时匹配多个节点,但我们只想要其中的某个节点,如第二个节点或者最后一个节点,这时可以利用中括号引入索引的方法获取特定次序的节点:
from lxml import etree
text1='''
<ul>
<li class="aaa" name="item"><a href="link1.html">``第一个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第二个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第三个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第四个``</a></li>
</ul>
</div>
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[contains(@class,"aaa")]/a/text()') #``获取所有``li``节点下``a``节点的内容
result1=html.xpath('//li[1][contains(@class,"aaa")]/a/text()') #``获取第一个
result2=html.xpath('//li[last()][contains(@class,"aaa")]/a/text()') #``获取最后一个
result3=html.xpath('//li[position()>2 and position()<4][contains(@class,"aaa")]/a/text()') #``获取第一个
result4=html.xpath('//li[last()-2][contains(@class,"aaa")]/a/text()') #``获取倒数第三个
print(result)
print(result1)
print(result2)
print(result3)
print(result4)
#
['``第一个``', '``第二个``', '``第三个``', '``第四个``']
['``第一个``']
['``第四个``']
['``第三个``']
['``第二个``']
节点轴选择
XPath提供了很多节点选择方法,包括获取子元素、兄弟元素、父元素、祖先元素等,示例如下:
from lxml import etree
text1='''
<ul>
<li class="aaa" name="item"><a href="link1.html">``第一个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第二个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第三个``</a></li>
<li class="aaa" name="item"><a href="link1.html">``第四个``</a></li>
</ul>
</div>
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[1]/ancestor::*') #``获取所有祖先节点
result1=html.xpath('//li[1]/ancestor::div') #``获取``div``祖先节点
result2=html.xpath('//li[1]/attribute::*') #``获取所有属性值
result3=html.xpath('//li[1]/child::*') #``获取所有直接子节点
result4=html.xpath('//li[1]/descendant::a') #``获取所有子孙节点的``a``节点
result5=html.xpath('//li[1]/following::*') #``获取当前子节之后的所有节点
result6=html.xpath('//li[1]/following-sibling::*') #``获取当前节点的所有同级节点
#
[<Element html at 0x3ca6b960c8>, <Element body at 0x3ca6b96088>, <Element div at 0x3ca6b96188>, <Element ul at 0x3ca6b961c8>]
[<Element div at 0x3ca6b96188>]
['aaa', 'item']
[<Element a at 0x3ca6b96248>]
[<Element a at 0x3ca6b96248>]
[<Element li at 0x3ca6b96308>, <Element a at 0x3ca6b96348>, <Element li at 0x3ca6b96388>, <Element a at 0x3ca6b963c8>, <Element li at 0x3ca6b96408>, <Element a at 0x3ca6b96488>]
[<Element li at 0x3ca6b96308>, <Element li at 0x3ca6b96388>, <Element li at 0x3ca6b96408>]
xpath****参考网站
爬虫和mongo
2022年10月19日
11:32
使用PyMongo库存储到数据库
PyMongo``是用于``MongoDB``的开发工具``,``是``python``操作``MongoDB``数据库的推荐方式``.PyMongo``中主要提供了如下类与``MongoDB``数据库进行交互:
- MongoClient类:用于与MongoDB服务器建立连接
- DataBase类:表示MongoDB中的数据库
- Collection类:表示MongoDB中的集合
- Cursor类:表示查询方法返回的结果,用于对多行数据进行遍历
PyMongo``库的基本使用流程如下:
- 创建一个MongoClient类的对象,与MongoDB服务器建立连接
- 通过MongoClient对象访问数据库(DataBase对象)
- 使用上个步骤的数据库创建一个集合(Collection对象)
- 调用集合中提供的方法在集合中插入,删除,修改和查询文档
1.创建连接
pymongo.mongo_client.MongoClient(host="localhost",
**port**``**=**``**27017,**
**document_class=dict,**
**tz_aware=False,**
**connect=True,**
***\*kwargs)**
参数说明:
- host参数:表示主机名或IP地址
- port参数:表示连接的端口号
- document_class参数:客户端查询返回的文档默认使用此类
- tz_aware参数:如果为True,则此MongoClient作为文档中的值返回的datetime实例,将会别时区所识别
- connect参数:若为True(默认),则立即开始在后台连接到MongoDB,否则连接到第一个操作
from pymongo.mongo_client import MongoClient
client=MongoClient("localhost",27017)
# client=MongoClient("mongodb://localhost:27017")
2.访问数据库
db=client.test
3.创建集合
# ``数据库中若没有``,``则创建``test``集合
collection=db.test
4.插入文档
往集合中插入文档的方法主要有如下两个:
- insert_one()方法:插入一条文档对象
- insert_many()方法:插入列表形式的多条文档对象
# ``插入一条文档
try:
result=collection.insert_one({"name":"zhagngsan","age":20})
print(result)
except Exception as error:
print(error)
# ``插入多条文档
result=collection.insert_many([
{"name":"lisi","age":21},
{"name":"wangwu","age":22},
{"name":"liliu","age":23}
])
print(result)
5.查询文档
用于查找文档的方法主要有如下几个:
- find_one()方法:查找一条文档对象
- find_many()方法:查找多条文档对象
- find()方法:查找所有文档对象
result=collection.find({"age":23})
print(result)
for doc in result:
print(doc)
6.更新文档
用于更新文档的方法主要有如下几个:
- update_one()方法:更新一条文档对象
- update_many()方法:更新多条文档对象
collection.update_one({"name":"zhangsan"},{"$set":{"age":25}})
7.删除文档
用于删除文档的方法包括如下几个:
- delete_one()方法:删除一条文档对象
- delete_many()方法:删除所有记录
collection.delete_one({"name":"liliu"})
案例一
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Author LQ6H
import urllib.request
from pymongo.mongo_client import MongoClient
from bs4 import BeautifulSoup
def movie():
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36"
headers={
"User-Agent":user_agent
}
base_url="https://movie.douban.com/top250?start="
for i in range(0,10):
full_url=base_url+str(i*25)
request=urllib.request.Request(full_url,headers=headers)
response=urllib.request.urlopen(request)
html=response.read()
# print(html)
# ``选取符合要求的节点信息
soup=BeautifulSoup(html,"lxml")
div_list=soup.find_all("div",{"class":"info"})
for node in div_list:
# ``电影名称
title=node.find("a").find("span").text
# ``电影评分
score=node.find("div",class_="star").find("span",class_="rating_num").text+"``分``"
# ``详情链接
link=node.find("a")["href"]
data_dict={"``电影``":title,"``评分``":score,"``链接``":link}
client=MongoClient("localhost",27017)
db=client.test
collection=db.movie
# ``逐条往集合插入文档
collection.insert_one(data_dict)
# ``查找``score``等于``9.5``的文档
cursor=collection.find({"``评分``":"9.5``分``"})
print(cursor)
if __name__=="__main__":
movie()
进程和线程以协程
2022年6月20日
10:05
进程
进程的特点
动态性:进程是程序的一次执行过程,动态产生,动态消亡。
独立性:进程是一个能独立运行的基本单元。是系统分配资源与调度的基本单元。
并发性:任何进程都可以与其他进程并发执行。
结构性:进程由程序、数据和进程控制块三部分组成。
缺点
无法即时完成的任务带来大量的上下文切换代价与时间代价。
进程的上下文:当一个进程在执行时,``CPU``的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。
上下文切换:当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够得到切换时的状态并执行下去。
进程适合用于cpu密集型的计算
Python``要充分利用多核``CPU``,就用多进程。
原因是:每个进程有各自独立的``GIL``,互不干扰,这样就可以真正意义上的并行执行,所以在``Python``中,多进程的执行效率优于多线程``(``仅仅针对多核``CPU``而言``)``。
进程模块
导入模块`` ``:`` multiprocessing
From multiprocessing import Process,Lock
简单使用、
初始化一个进程
p=Process(target=``传入方法名不要括号``(``相当于吧内存地址传过去了``),args=(``参数元组类型``(1``,``)))
p.start() ``# ``启动这个进程
p.join() ``# ``设置阻塞这个进程 不让主方法继续执行
设置锁来保证i/o安全
lock=Lock()
方法一: 在with中加锁
with lock:`
` # do something...
相当于以下代码:
lock.acquire() ``# ``加锁
try:`
` # do something...`
`finally:`
` temp_lock.release() ``# ``释放锁
进程池
ProcessPoolExecutor`` ``类是 ``Executor`` ``的子类,它使用进程池来异步地执行调用。
max_workers ``可以设置最大进程
方法一
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime)
方法二:
aa =``concurrent.futures.ProcessPoolExecutor()
返回值列表`` = aa.map(``方法,参数``)
方法介绍
map
# 这个是有序调用,会依次拿取参数中的值
返回一个返回值列表future = map(fanc =传入方法的地址,要传入的参数列表)
future.result() # ``获取返回结果
Submit
将可调用**对象 fn 调度为执行,并返回一个表示可调用对象执行的 [Future](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/concurrent.futures.html#concurrent.futures.Future) 对象。fn(*args, **kwargs)
future=executor.submit(``fn =``传入方法的地址参数,用逗号隔开``)
future.result() # ``获取返回结果
result(timeout=None)
返回调用返回的值。如果调用还没完成那么这个方法将等待`` ``timeout`` ``秒。如果在`` ``timeout`` ``秒内没有执行完成,`[concurrent.futures.TimeoutError](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/concurrent.futures.html#concurrent.futures.TimeoutError)` ``将会被触发。``timeout`` ``可以是整数或浮点数。如果`` ``timeout`` ``没有指定或为`` ``None``,那么等待时间就没有限制。
pipeline框架

我们现在有一个事情由输入数据得到输出数据,中间会经过很多的模块,而这些模块之间会通过中间数据进行交互。我们称这些处理模块为处理器也叫Processor,而把事情分为很多模块进行处理的架构称为Pipeline架构。
多线程数据通信的queue.Queue
我们上文提到多线程的生产者和消费者之间需要数据交互进行完成爬虫。同时也遗留了一个问题,那就是多线程之间如何进行数据交互。于是,便有了``queue.Queue``。
queue.Queue``可以用于多线程之间的、线程安全的数据通信
class`` ``queue.Queue(maxsize=0)
``FIFO`` ``队列的构造函数。````maxsize`` ``是一个整数,用于设置队列中可放置的项目数的上限。一旦达到此大小,插入将阻塞,直到队列项目被消耗。如果`` ``maxsize`` ``小于或等于零,则队列大小是无限的。``
class`` ``queue.LifoQueue(maxsize=0)
LIFO`` ``队列构造函数。`` ``maxsize`` ``是个整数,用于设置可以放入队列中的项目数的上限。当达到这个大小的时候,插入操作将阻塞至队列中的项目被消费掉。如果`` ``maxsize`` ``小于等于零,队列尺寸为无限大。
class`` ``queue.PriorityQueue(maxsize=0)
优先级队列构造函数。`` ``maxsize`` ``是个整数,用于设置可以放入队列中的项目数的上限。当达到这个大小的时候,插入操作将阻塞至队列中的项目被消费掉。如果`` ``maxsize`` ``小于等于零,队列尺寸为无限大。
# 1.``导入类库
import queue
# 2.``创建``Queue maxsize```` ``是一个整数,用于设置队列中可放置的项目数的上限。一旦达到此大小,插入将阻塞,直到队列项目被消耗。如果 ``````maxsize```` ``小于或等于零,则队列大小是无限的
q = queue.Queue(maxsize=0)
# 3.``添加元素``(``如果队列已满,则进行阻塞,等待队列不满时添加``)
q.put(item)
# 4.``获取元素(如果队列为空,则进行阻塞,等待队列不空时获取)
item = q.get()
# 5.``查询状态
# ``查看元素的多少
q.qsize()
# ``判断是否为空
q.empty()
# ``判断是否已满
q.full()

线程
Python多线程下,每个线程的执行方式如下:
获取GIL
执行代码直到sleep或者是python虚拟机将其挂起。
释放GIL
可见,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。
因此,同一时刻,只有一个线程在运行,其它线程只能等待,即使是多核CPU,也没办法让多个线程「并行」地同时执行代码,只能是交替执行,因为多线程涉及到上线文切换、锁机制处理(获取锁,释放锁等),所以,在CPU密集型应用中多线程执行不快反慢。
补充说明:GIL
在 CPython 解释器(Python语言的主流解释器)中,有一把全局解释锁GIL(Global Interpreter Lock),某个线程须先拿到GIL才允许进入CPU执行。
什么时候 GIL 被释放呢?
当一个线程遇到 I/O 任务时,将释放GIL。
计算密集型(CPU-bound)线程执行 100 次解释器的计步(ticks)时(计步可粗略看作 Python 虚拟机的指令),也会释放 GIL。在Python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL)。
特别提示:GIL只在CPython中才有,因为CPython调用的是c语言的原生线程,所以他不能直接操作cpu,只能利用GIL保证同一时间只能有一个线程拿到数据。而在PyPy和Jython中是没有GIL的。
线程模块
导入模块`` ``:`` multiprocessing
From threading import ``Thread``,Lock
简单使用、
初始化一个进程
t``=thread(target=``传入方法名不要括号``(``相当于吧内存地址传过去了``),args=(``参数元组类型``(1``,``)))
t.start() ``# ``启动这个线程
t.join() ``# ``设置阻塞这个线程不让主方法继续执行
设置锁来保证i/o安全
lock=Lock()
方法一: 在with中加锁
with lock:`
` # do something...
相当于以下代码:
lock.acquire() ``# ``加锁
try:`
` # do something...`
`finally:`
` temp_lock.release() ``# ``释放锁
线程池
ThreadPoolExecutor`` ``类是 ``Executor`` ``的子类,它使用进程池来异步地执行调用。
max_workers ``可以设置最大线程
方法一
with concurrent.futures.ThreadPoolExecutor`` ``() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime)
方法二:
aa =``concurrent.futures.ThreadPoolExecutor`` ``()
返回值列表`` = aa.map(``方法,参数``)
方法介绍
map
# 这个是有序调用,会依次拿取参数中的值
返回一个返回值列表future = map(fanc =传入方法的地址,要传入的参数列表)
future.result() # ``获取返回结果
Submit
将可调用**对象 fn 调度为执行,并返回一个表示可调用对象执行的 [Future](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/concurrent.futures.html#concurrent.futures.Future) 对象。fn(*args, **kwargs)
future=executor.submit(``fn =``传入方法的地址参数,用逗号隔开``)
future.result() # ``获取返回结果
result(timeout=None)
返回调用返回的值。如果调用还没完成那么这个方法将等待`` ``timeout`` ``秒。如果在`` ``timeout`` ``秒内没有执行完成,`[concurrent.futures.TimeoutError](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/concurrent.futures.html#concurrent.futures.TimeoutError)` ``将会被触发。``timeout`` ``可以是整数或浮点数。如果`` ``timeout`` ``没有指定或为`` ``None``,那么等待时间就没有限制。
协程 asyncio
Python协程
运行效率极高,协程的切换完全由程序控制,不像线程切换需要花费操作系统的开销,线程数量越多,协程的优势就越明显。
同时,在Python中,协程不需要多线程的锁机制,因为只有一个线程,也不存在变量冲突。
协程对于IO密集型任务非常适用,如果是CPU密集型任务,推荐多进程+协程的方式。对于多核CPU,利用多进程+协程的方式,能充分利用CPU,获得极高的性能。
Python协程的发展时间较长:
-
- Python2.5 为生成器引用.send()、.throw()、.close()方法
- Python3.3 为引入yield from,可以接收返回值,可以使用yield from定义协程
- Python3.4 加入了asyncio模块
- Python3.5 增加async、await关键字,在语法层面的提供支持
- Python3.7 使用async def + await的方式定义协程
- 此后asyncio模块更加完善和稳定,对底层的API进行的封装和扩展
- Python将于3.10版本中移除以yield from的方式定义协程
注意:
使用``async def``的形式定义
在协程中可以使用``await``关键字,注意,其后跟的是``"``可等待对象``"(``协程``, ``任务`` ``和`` Future)
协程不能直接执行,需要在``asyncio.run()``中执行,也可以跟在``await``后面
async``和``await``这两个关键字只能在协程中使用
其中,``asyncio.run(main, *, debug=False)``方法就是对``run_until_complete``进行了封装:
loop = events.new_event_loop()
return loop.run_until_complete(main)
Lock
class`` ``asyncio.Lock
实现一个用于`` asyncio ``任务的互斥锁。`` ``非线程安全。
asyncio ``锁可被用来保证对共享资源的独占访问。
使用`` Lock ``的推荐方式是通过`` `[async with](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/reference/compound_stmts.html#async-with)` ``语句``:
lock=asyncio.Lock()
# ... Later
async with lock:
# access shared state
这等价于``:
lock=asyncio.Lock()
# ... Later
Await lock.acquire()
try:
# access shared state
finally:
lock.release()
在`` 3.10 ``版更改``:`` ``Removed the`` ``loop`` ``parameter.
coroutine`` ``acquire()
获取锁。
此方法会等待直至锁为`` ``unlocked``,将其设为`` ``locked`` ``并返回`` ``True``。
当有一个以上的协程在`` `[acquire()](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/asyncio-sync.html#asyncio.Lock.acquire)` ``中被阻塞则会等待解锁,最终只有一个协程会被执行。
锁的获取是`` ``公平的``: ``被执行的协程将是第一个开始等待锁的协程。
release()
释放锁。
当锁为`` ``locked`` ``时,将其设为`` ``unlocked`` ``并返回。
如果锁为`` ``unlocked``,则会引发`` `[RuntimeError](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/library/exceptions.html#RuntimeError)`。
locked()
如果锁为`` ``locked`` ``则返回`` ``True``。
异步协程爬取框架
未设置并发度:
import asyncio
# ``获取事件循环
loop = asyncio.get_event_loop()
# ``根据协程语法定义一个协程方法
async def main(url):
await get_url(url) ``# ``其他方法
# ``await ``不会等待直接进入下一个
创建``task``列表
tasks = [loop.create_task(main(url)) for url in urls]
# ``执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
设置并发度
import asyncio
# ``获取事件循环
asem = asyncio.Semaphore(10) ``# ``设置10的最大并发
loop = asyncio.get_event_loop()
# ``根据协程语法定义一个协程方法
async def main(url):
async with asem:
await get_url(url) # ``其他方法
# await ``不会等待直接进入下一个
创建``task``列表
tasks = [loop.create_task(main(url)) for url in urls]
# ``执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))


并发度第二种方法:
i``mport asyncio
async def foo(char:str, count: int):`
` for i in range(count):`
` print(f"{char}-{i}")`
` await asyncio.sleep(1)
async def main():`
` task1 = asyncio.create_task(foo("A", 2))`
` task2 = asyncio.create_task(foo("B", 3))`
` task3 = asyncio.create_task(foo("C", 2))
await task1`
`await task2`
`await task3
if __name__ == '__main__':`
` asyncio.run(main())
创建一个任务或者说并发任务
asyncio.create_task(coro,`` ``*,`` ``name=None)
将`` ``coro`` ``协程`` ``封装为一个`` ``Task`` ``并调度其执行。返回`` Task ``对象。``一个异步方法``\``协程方法
name`` ``不为`` ``None``,它将使用`` ``Task.set_name()`` ``来设为任务的名称
第三种方法设置并发度:
Import asyncio
Async def foo(char:str, count: int):
For i in range(count):
print(f"{char}-{i}")
awaitasyncio.sleep(.5)
Async def main():
Await asyncio.gather(foo("A", 2), foo("B", 3), foo("C", 2))
if__name__ == '__main__':
asyncio.run(main())
运行 asyncio 程序
asyncio.run(coro, ***, debug=False)
执行 [coroutine](file:///C:/Users/FQCj/Desktop/python-3.10.5-docs-html/glossary.html#term-coroutine) coro 并返回结果。
此函数会运行传入的协程,负责管理 asyncio 事件循环,终结异步生成器,并关闭线程池。
当有其他 asyncio 事件循环在同一线程中运行时,此函数不能被调用。
如果 debug 为 True,事件循环将以调试模式运行。
此函数总是会创建一个新的事件循环并在结束时关闭之。它应当被用作 asyncio 程序的主入口点,理想情况下应当只被调用一次。
总结:
-
- 线程和协程推荐在IO密集型的任务(比如网络调用)中使用,而在CPU密集型的任务中,表现较差。
- 对于CPU密集型的任务,则需要多个进程,绕开GIL的限制,利用所有可用的CPU核心,提高效率。
- 在高并发下的最佳实践就是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
生产者消费者爬虫
2022年6月20日
10:02
通过多线程来创建出线程,来进行同时的爬取数据(生产者)和解析数据(消费者)
当生产者消费者爬虫没有运用到线程池是一般是通过pipeline框架实现的

我们现在有一个事情由输入数据得到输出数据,中间会经过很多的模块,而这些模块之间会通过中间数据进行交互。我们称这些处理模块为处理器也叫Processor,而把事情分为很多模块进行处理的架构称为Pipeline架构。
多线程数据通信的queue.Queue
- 我们上文提到多线程的生产者和消费者之间需要数据交互进行完成爬虫。同时也遗留了一个问题,那就是多线程之间如何进行数据交互。于是,便有了queue.Queue。
- queue.Queue可以用于多线程之间的、线程安全的数据通信
import requests
import threading
from queue import Queue
import time
\#生产者只请求页面
class MyProducer(threading.Thread):
def __init__(self,i,page_queue):
super().__init__()
self.i = i
self.page_queue = page_queue
\#复写run方法
def run(self):
\#任务队列不为空就取数据执行
while True:
if self.page_queue.empty():
break
try:
q = self.page_queue.get(block=False)
print(self.i, '开始任务%s======='%(q))
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=python&pageIndex=%s&pageSize=10'%(q)
self.getHtml(url)
print(self.i,'结束任务=======')
except:
pass
def getHtml(self,url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
response = requests.get(url=url, headers=headers).json()
response_q.put(response)
class MyCousumer(threading.Thread):
def __init__(self,i):
super().__init__()
self.i = i
\#复写run方法
def run(self):
\#任务队列不为空就取数据执行
while True:
\#1.任务队列为空,2生产者进程全部结束
if response_q.empty() and flag:
break
try:
response = response_q.get(block=False)
self.parse_html(response)
except:
pass
def parse_html(self,response):
job_lst = response['Data']['Posts']
for job in job_lst:
name = job['RecruitPostName']
address = job['LocationName']
Responsibility = job['Responsibility']
Responsibility = Responsibility.replace('\n', '').replace('\r', '')
PostURL = job['PostURL']
info = "工作名称:%s,工作地点:%s,岗位职责:%s,详情:%s" % (name, address, Responsibility, PostURL)
\#加锁
with lock:
with open("腾讯招聘.txt", 'a', encoding='utf-8') as f:
f.write(info + '\n')
lock = threading.Lock() #锁
response_q = Queue() #消费者队列
flag = False #表示生产者线程是否都结束
if __name__ == '__main__':
\#创建生产者任务队列
page_queue = Queue()
for i in range(1,88):
page_queue.put(i)
\#启线程队列
producer_name = ['p1','p2','p3']
p_tread = []
cousumer_name = ['c1','c2','c3']
c_tread = []
\#启动三个生产者线程
for i in producer_name:
p_crawl = MyProducer(i,page_queue)
p_crawl.start()
p_tread.append(p_crawl)
\#启动三个消费者线程
for j in cousumer_name:
c_crawl = MyCousumer(j)
c_crawl.start()
c_tread.append(c_crawl)
\#生产者阻塞主线程
for threadi in p_tread:
threadi.join()
\#生产者都死了把flag变成True,可以让消费者做判断
flag = True
\#消费者阻塞主线程
for threadi in c_tread:
threadi.join()
python执行js代码
2022年6月21日
19:13
安装
Pip install pyexecjs
使用
Imput execjs
# 实例化一个对象
Node = execjs.get()
# 进行源文件编译
Ctx = node.compile(open('路径',encoding='utf-8').rend())
#执行js函数
Funname= '函数和参数之列的'
Pwd = ctx.eval(funname)
scrapy概述
2021年12月3日
14:59
概述
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
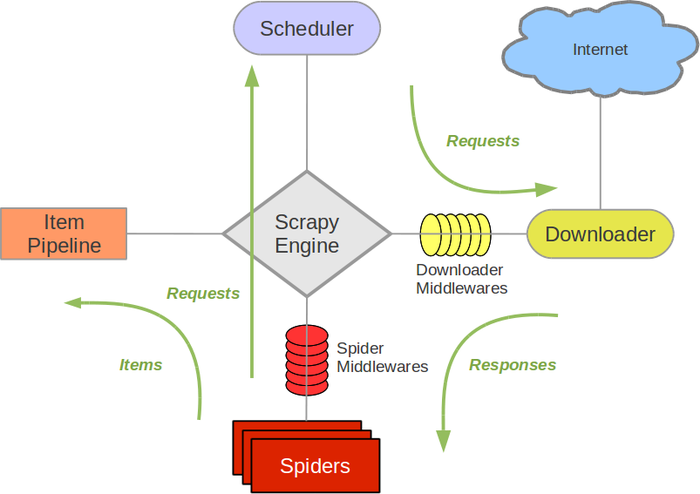
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器****(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器****(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件****(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流****(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
事件驱动网络****(Event-driven networking)
Scrapy基于事件驱动网络框架 Twisted 编写。因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
=
Scrapy srtiings
2021年12月3日
14:27
#CONCURRENT_REQUESTS=16 这个是进程数默认16
DOWNLOAD_DELAY=3 这个是爬取时等待几秒
DOWNLOAD_DELAY
默认``:`` ``0
下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度,`` ``减轻服务器压力。同时也支持小数``:
DOWNLOAD_DELAY=0.25# 250 ms of delay
该设定影响``(``默认启用的``)`` `[RANDOMIZE_DOWNLOAD_DELAY](https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html#std:setting-RANDOMIZE_DOWNLOAD_DELAY)` ``设定。`` ``默认情况下,``Scrapy``在两个请求间不等待一个固定的值,`` ``而是使用``0.5``到``1.5``之间的一个随机值`` *`` `[DOWNLOAD_DELAY](https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html#std:setting-DOWNLOAD_DELAY)` ``的结果作为等待间隔。
当`` `[CONCURRENT_REQUESTS_PER_IP](https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html#std:setting-CONCURRENT_REQUESTS_PER_IP)` ``非``0``时,延迟针对的是每个``ip``而不是网站。
另外您可以通过``spider``的`` ``download_delay`` ``属性为每个``spider``设置该设定。
COOKIES_ENABLED=False这个是是不是让框架自己写cookies,默认是可以,但是要是要自己设置的时候要关掉
DEFAULT_REQUEST_HEADERS={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'Accept-Language':'en',
'Referer':'http://www.bookschina.com/',
'Cookie':'ASP.NET_SessionId=wpvthe1xfgpinfxhwzgtcwwv;Hm_lvt_6993f0ad5f90f4e1a0e6b2d471ca113a=1638492946,'
'1638498510;booklisthistory=8186531,4513894;UserUnionId=61bfb70d-b62c-4683-ac77-7f65c7540dad;'
'UserViewBooks=[4513894,8186531];ck=5bfd8eb913e07a8f;bind=53fb906683390a58;indexCache=yes;'
'BookUser=4750214%7cztw_17670dzk686%7c1%7c1%7c637767183802012192%7c20180722%7cbb0dc4f17c9f8ad7;'
'uplevel=2021/12/311:06:20;Hm_lpvt_6993f0ad5f90f4e1a0e6b2d471ca113a=1638500791'
}这个是用来设置请求头参数的,自定义cookies也是在这里
这两个分别是,默认是关闭的
爬虫中间件,
Enableordisablespidermiddlewares
Seehttps://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES={
'bookschina_path_project.middlewares.BookschinaPathProjectSpiderMiddleware':543,
}
下载中间件
Enableordisabledownloadermiddlewares
Seehttps://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES={
'bookschina_path_project.middlewares.BookschinaPathProjectDownloaderMiddleware':543,
}
这个是管道配置,可以自定义管道,300表示优先级
Configureitempipelines
Seehttps://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES={
'bookschina_path_project.pipelines.BookschinaPathProjectPipeline':300,
}
DOWNLOADER_STATS
默认: True
是否收集下载器数据。
Scrapy 请求
2021年12月3日
14:38
get请求
Request 、Respones
Post
FormReuqest()
start_requests(self)
注意
spider文件中删除start_urls
post提交
Yield scrapy.FormReuqest()
参数:
Url ,formdata,headers,cookies,callback,其中黄色标记的是字典格式
get提交:
Yield scrapy.Reqeust()
Yield :方法在调用之前一般都要加yield表示返回这个对象给引擎
Scrapy 暂停
2021年12月3日
14:41
Jobs: 暂停,恢复爬虫
有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。
Scrapy通过如下工具支持这个功能:
- 一个把调度请求保存在磁盘的调度器
- 一个把访问请求保存在磁盘的副本过滤器[duplicates filter]
- 一个能持续保持爬虫状态(键/值对)的扩
Job 路径
要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。这个路径将会存储 所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。必须要注意的是,这个目录不允许被不同的spider 共享,甚至是同一个spider的不同jobs/runs也不行。也就是说,这个目录就是存储一个 单独 job的状态信息。
怎么使用
要启用一个爬虫的持久化,运行以下命令:
Scrapy crawl somespider -s JOBDIR=crawls/somespider - 1
然后,你就能在任何时候安全地停止爬虫(按Ctrl-C或者发送一个信号)。恢复这个爬虫也是同样的命令:
Scrapy crawl somespider -s JOBDIR=crawls/somespider-1
注意
Cookies****的有效期
Cookies是有有效期的(可能过期)。所以如果你没有把你的爬虫及时恢复,那么他可能在被调度回去的时候 就不能工作了。当然如果你的爬虫不依赖cookies就不会有这个问题了。
请求序列化
请求是由 pickle 进行序列化的,所以你需要确保你的请求是可被pickle序列化的。 这里最常见的问题是在在request回调函数中使用 lambda 方法,导致无法序列化。
scrapy中间件
2021年12月4日
12:08
中间件
-下载中间件
-爬虫中间件
-下载中间件:
-位置。在引擎和下载器之间
-作用:批量拦截到整个工程中的所有的请求和响应
-拦截请求:
-UA伪装,可以获取到头部的请求,然后伪装--USER_AGENT
-代理ip
-拦截响应:
-篡改响应数据,:比如ajax等动态加载的东西去发请求,或响应对象,
BookCommentProjectDownloaderMiddleware 下载中间件
-
process_request --拦截请求的方法
-
-
用来写ua伪装--USER_AGENT
-
-
Request.headers['USER_AGENT'] 来获取
-
然后可以封装一个列表在列表写入可用的ua,在通过random函数去随机取值
-
- Request.headers['USER_AGENT'] = Random.choice(列表)

-
-
-
process_response -- 拦截所有的响应
-

- 基于selenium便捷的获取动态加载数据
-
process_exception -- 拦截发生的异常的请求
-
-
这里可以来修正请求---USER_AGENT
-
通过代理ip修正
-
- 注意在更换代理ip是要注意网页的协议,是http还是https,这两个的ip是不同的
- 获取请求中的ip : reques.meta[' proxy '],然后重新赋值就可以了
- 代理ip其实就是两个列表里面放的是ip,http和https的ip,就是对我们原来的ip进行随机赋值就好
- 原理就是判断一下网页的协议,而后进行分别赋值,

- 然后修正以后要把我们的请求重新去发送,这里就是用 return request 就可以
-
-
spider_opened --日志的方法
scrapy中间件运用selenium
2021年12月4日
14:09
1.安装|导包
pip安装
From selenium import webdriver
2.在爬虫文件中定义一个构造方法来初始化一个selenium对象
Def init(self):
Self.selenium对象 = webdriver.Chrome(executable_path='浏览器驱动对象地址' )这里我们用的是谷歌浏览器
3.在中间件中获取爬虫类对象
可以用 spider.selenium对象名来获取到,把他存到变量中去
然后就可以用变量进行操作selenium
4.关闭可以在spider爬虫文件中用:
Def closed(self,spider):
Self.selenium对象.quit()关闭所有就可以了
CrawlScrapy全站爬取
2021年12月5日
14:01
CrawlScrapy:scrapy的一个子类
-
全站数据爬取的方法
-
- 基于scrapy:手动请求
- 基于Crawlscrapy
-
crawlscrapy的使用:
-
-
创建一个工程
-
- Cd 文件路径
-
创建爬虫文件
-
- Scrapy genspider -t crawl 爬虫名字 域名
-
规则解析器:
-
- rules=(
-
Rule(LinkExtractor(allow=r’Item/‘),Callback='parse_item',follow=True),)
-
作用:将链接提取器提取到的链接进行指定规则(callback)的解析操作
-
Follow=True:可以将链接提取器,继续作用到,链接提取器提取到的链接,所对应的页面中,
-
简单来说就是可以吧所有URL搞出来
-
链接提取器:LinkExtractor(allow=r’Item/‘)
-
- 作用:根据指定规则(allow='正则')进行指定链接的提取
数据管道
2021年12月1日
20:07
-
setting中配置管道
-
Process_item(self,item,spider)管道类的处理数据方法
-
- 通过isinstance()判断item属于哪一种类型,然后按某一类进行处理
- 扩展python自身相关函数
type(obj)获取对象的类型
山r(obj)获取对象中所有的属性(函数、类、变量)
help(obj)获取对象的文档帮助信息
isinstance(obj,类)判断。bj是否为类的实例对象
issubclass(类,父类)判断类是否为父类的子类
hasattr(对象,属性或方法)判断对象中是否存在属性或方法
getattr(对象,属性或方法)获取对象中的属性或方法
setattr(对象,属性,属性值)设置对象的属性或方法
id(对象)获取对象在内存中的唯一标识
-

-
返回item:
-
- 目的:让优先级第一的数据管道类可以接收得到iitem数据
图片管道
2021年11月26日
10:42
1.导包;
From scrapy.pipelines.images import ImagesPipeline
2.设置管道:

3.在settings中添加保存位置:

4.在管道中设置固定的传入位置:

image_urls:默认url地址
images:默认结果字段
5.设置我的爬虫是从哪里访问图片的:防跨域请求

文件保存
2021年11月22日
11:18
视频
参考网站
2021年11月22日
11:18
Scrapy 参考网站
(43条消息) scrapy爬虫案例-----赶集网_dj_hanhan的博客-CSDN博客
xpath****参考网站

 浙公网安备 33010602011771号
浙公网安备 33010602011771号