MySql-索引&主备库&锁与幻读
索引
今天前辈说了回表
首先想一个问题
基于主键索引和普通索引的查询有什么区别?
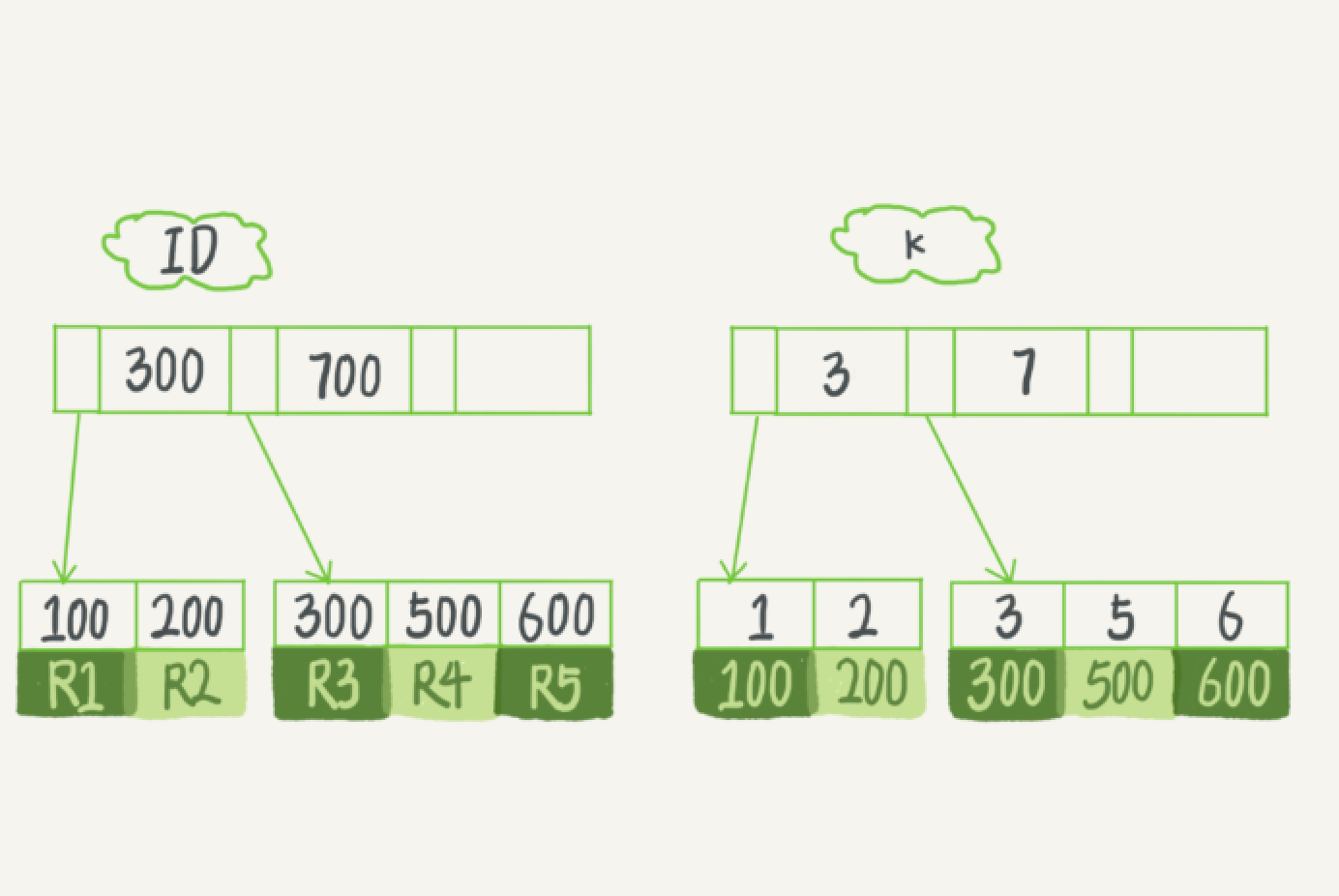
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树, 得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询
主键索引与非主键索引
- 表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树
根据叶子节点的内容,索引类型分为主键索引和非主键索引。- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引 (secondary index)。
索引维护
- B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。
- 如果插入新的行ID值为 800,则只需要在 R5 的记录后面插入一个新记录。
- 如果新插入的 ID 值为 400,需要逻辑上挪动后面的数据,空出位置。
- 如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新 的数据页,然后挪动部分数据过去。这个过程称为页分裂。
- 这里可以去查看B+树的插入删除节点方式
在上图我们如果执行下面的语句会有什么流程呢
select * from T where k between 3 and 5
- 首先我们去k索引树找到k=3,拿到ID=300
- 再到ID索引树找到ID=300对应的R3
- 在 k 索引树取下一个值 k=5,拿到 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这里每次回到主键索引树搜索的过程叫做回表
覆盖索引
- 如果执行的语句是 select ID from T where k between 3 and 5,
- 这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,
- 因此可以直接提供查询结果,不需要回表。也就是说,在这个查 询里面,
- 索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
-由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能
优化手段。
最左前缀原则
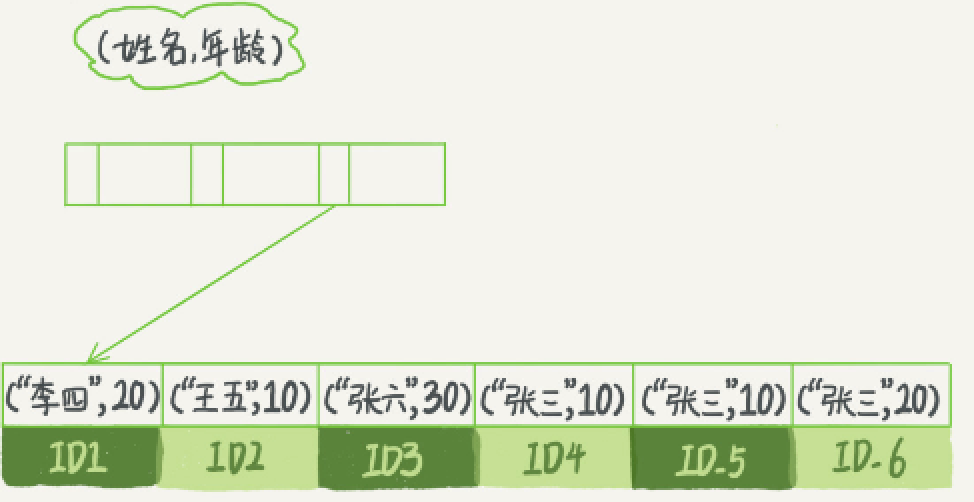
- 当需求是查到所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历得到所 有需要的结果。
- 如果要查的是所有名字第一个字是“张”的人, SQL 语句的条件是
where name like ‘张 %。 - 这时,也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍 历,直到不满足条件为止。
- 可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。
- 这个最左 前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
索引下推
- 最左前缀可以用于在索引中定位记录,那些不符合最左前缀的部分,会怎么样呢?
- 以市民表的联合索引(name, age)为例。如果现在有一个需求:检索出表中“名字第 一个字是张,而且年龄是 10 岁的所有男孩”。SQL 语句如下
select * from user where name like '张 %' and age=10 and ismale=1;
- 所以这个语句在搜索索引树的时候,只能用 “张”,找到第一个 满足条件的记录 ID3。当然,这还不错,总比全表扫描要好
- MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,
- 对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
无索引下推

- 在 (name,age) 索引里面我特意去掉了 age 的值,这个过程 InnoDB 并不会去看 age 的值,
- 只是按顺序把“name 第一个字是’张’的记录一条条取出来回表。因此,需要回表 4 次。
有索引下推
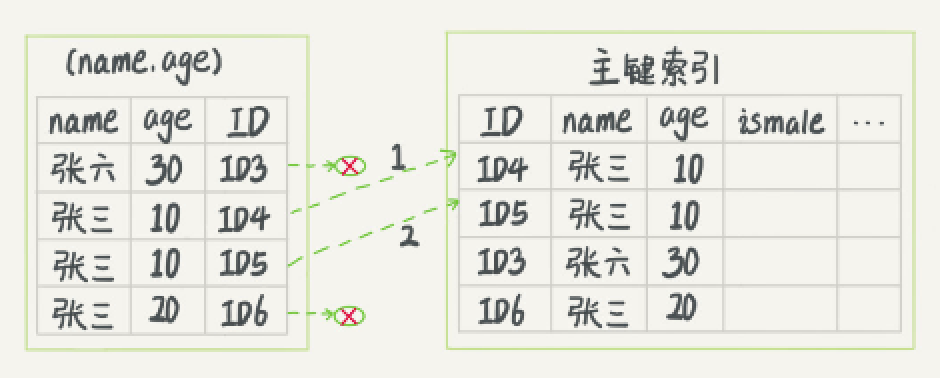
- 每一个虚线箭头表示回表一次。
- InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等 于 10 的记录,直接判断并跳过。- 只需要对 ID4、ID5 这两条记录回表取 数据判断,就只需要回表 2 次。
主库与备库
主库与备库一致性
- 只要主库执行更新生成的所有 binlog,都可以传到备库并被正确地执行,备库就能达到跟主库一致的状态
主备延迟
主动切换流程步骤
- 主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;
- 之后传给备库 B,把备库 B 接收完这个binlog 的时刻记为 T2;
- 备库 B 执行完成这个事务,把这个时刻记为 T3。
同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也 就是 T3-T1。
如果主备库机器的系统时间不一致也没关系
- 备库连接到主库的时候,会通过执行
SELECT UNIX_TIMESTAMP()函数来获得当前主库的系统时间。 - 如果这时候发现主库的系统时间与自己不一致,备库在执行
seconds_behind_master计算的时候会自动扣掉这个差值。
主备延迟的来源
- 有些部署条件下,备库所在机器的性能要比主库所在的机器性能差。
- 备库压力大
- 大事务
- 因为主库上必须等事务执行完成才会写入 binlog,再传给备库。
- 所以,如果一个主库上的语句执行 10 分钟,那这个事务很可能就会导致从库延迟 10 分钟。
- 大表DDL
锁与幻读
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`) ENGINE = InnoDB;
INSERT INTO t
values(0, 0, 0), (5, 5, 5), 10 (10, 10, 10), (15, 15, 15), (20, 20, 20), (25, 25, 25);
- 表除了主键 id 外,还有一个索引 c,初始化语句在表中插入了 6 行数据。
加锁
begin;
select * from t where d=5 for update;
commit;
- 这个语句会命中 d=5 的这一行,对应的主键 id=5,因此在 select 语句执行 完成后,id=5 这一行会加一个写锁
- 而且由于两阶段锁协议,这个写锁会在执行 commit 语句 的时候释放。
- 由于字段 d 上没有索引,因此这条查询语句会做全表扫描。那么,其他被扫描到的,但是不满 足条件的 5 行记录上;
分析是否会被加锁

- session A 里执行了三次查询,分别是 Q1、Q2 和 Q3。
- 它们的 SQL 语句相同,都 是
select * from t where d=5 for update。 - 而且使用的是当前读,并且加上写锁
在Q3读到id=1这一行的现象成为 幻读
幻读
- 读指的是一个事务在前后 两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。
- 正常情况下,普通快照读,是不会看到另一个事务插入的数据
出现的问题 - 首先语义上,在T1时刻已经把id=5行锁住,不允许其他事务进行读写
- 再往 session B 和 session C 里面分别加一条SQL语句,如下图

- sessionB 第二条将id=0,d=5的c值变为了5
- 因为T1还在给id=5这一行加锁,没有涉及到id=0,所以可以执行
- 但是破坏了session A中d=5行的加锁
导致数据不一致的问题
解决幻读
- 产生原因:行锁只能锁住行,但是新插入记录这个动作,要更新的是记 录之间的“间隙”
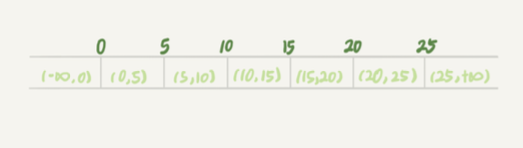
- 当执行
select * from t where d=5 for update的时候,就不止是给数据库中已有的 6 个记录加上了行锁 - 还同时加了 7 个间隙锁。这样就确保了无法再插入新的记录
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。
也就是说,表 t 初始化以后,如果用 select * from t for update 要把整个表所有记录锁起来,
就形成了 7 个 next-key lock,分别是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +∞]。
- 间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度 的
一条SQL语句的执行过程
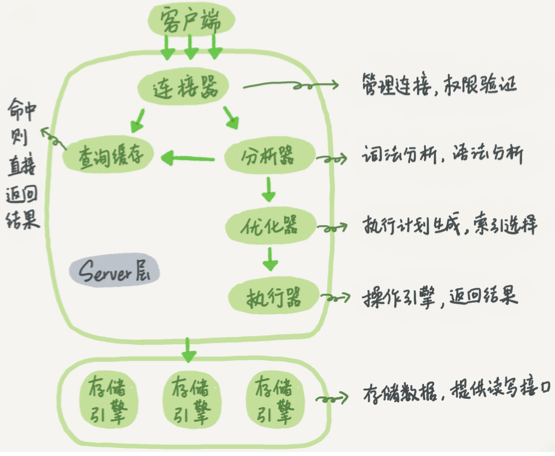
连接器
- 首先连接数据库,就是连接器负责跟客户端建立连接、获取权限和管理连接
查询缓存
- 建立连接后,就可以执行select语句,拿到请求后
- 先去查看缓存,不在缓存中再继续后面的执行阶段
分析器
- 分析器来做词法分析
- 查看语法是否正确
优化器
- 在开始执行之前,先要经过优化器的处理
- 去决定使用哪个索引,各个表的连接顺序
执行器
- 先判断表有没有执行读的权限
由于时间有限,写的不好请见谅,理解万岁(:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号