1116-五言诗生成&古今地名标注与展示
五言诗生成
数据来源
之前的诗集收集中包含:五言,五言绝句,五言律诗

收集训练集
#提取相关的五言诗词,构成训练集
import pandas as pd
import re
#获取指定文件夹下的excel
import os
def get_filename(path,filetype): # 输入路径、文件类型例如'.xlsx'
name = []
for root,dirs,files in os.walk(path):
for i in files:
if os.path.splitext(i)[1]==filetype:
name.append(i)
return name # 输出由有后缀的文件名组成的列表
def read():
file = 'data/'
list = get_filename(file, '.xlsx')
wu_list=[]
for it in list:
newfile =file+it
print(newfile)
# 获取诗词内容
data = pd.read_excel(newfile)
formal=data.formal
content=data.content
for i in range(len(formal)):
fom=formal[i]
if fom=='五言绝句':
text=content[i].replace('\n','')
text_list=re.split('[,。]',text)
#print(text_list)
if len(text_list)==9 and len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
#print(len(it))
if len(it)!=5 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
wu_list.append(text[:24])
wu_list.append(text[24:48])
elif fom=='五言':
text = content[i].replace('\n', '')
text_list = re.split('[,。]', text)
print(text_list)
if len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
print(len(it))
if len(it)!=5 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
if len(text_list)==5:
wu_list.append(text[:24])
elif len(text_list)==13:
wu_list.append(text[:24])
wu_list.append(text[24:48])
wu_list.append(text[48:72])
elif fom=='七言律诗':
text = content[i].replace('\n', '')
text_list = re.split('[,。]', text)
print(text_list)
if len(text_list)==17 and len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
print(len(it))
if len(it)!=5 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
wu_list.append(text[:24])
wu_list.append(text[24:48])
wu_list.append(text[48:72])
wu_list.append(text[72:96])
print(wu_list)
return wu_list
def write(content):
with open("./poem_train/wu_jueju.txt", "w", encoding="utf-8") as f:
for it in content:
f.write(it) # 自带文件关闭功能,不需要再写f.close()
f.write("\n")
if __name__ == '__main__':
content=read()
write(content)
收集结果
总共收集2万条

模型训练
import torch
import torch.nn as nn
import numpy as np
from gensim.models.word2vec import Word2Vec
import pickle
from torch.utils.data import Dataset,DataLoader
import os
def split_poetry(file='wu_jueju.txt'):
all_data=open(file,"r",encoding="utf-8").read()
all_data_split=" ".join(all_data)
with open("split.txt","w",encoding='utf-8') as f:
f.write(all_data_split)
def train_vec(split_file='split.txt',org_file='wu_jueju.txt'):
#word2vec模型
vec_params_file="vec_params.pkl"
#判断切分文件是否存在,不存在进行切分
if os.path.exists(split_file)==False:
split_poetry()
#读取切分的文件
split_all_data=open(split_file,"r",encoding="utf-8").read().split("\n")
#读取原始文件
org_data=open(org_file,"r",encoding="utf-8").read().split("\n")
#存在模型文件就去加载,返回数据即可
if os.path.exists(vec_params_file):
return org_data,pickle.load(open(vec_params_file,"rb"))
#词向量大小:vector_size,构造word2vec模型,字维度107,只要出现一次就统计该字,workers=6同时工作
embedding_num=128
model=Word2Vec(split_all_data,vector_size=embedding_num,min_count=1,workers=6)
#保存模型
pickle.dump((model.syn1neg,model.wv.key_to_index,model.wv.index_to_key),open(vec_params_file,"wb"))
return org_data,(model.syn1neg,model.wv.key_to_index,model.wv.index_to_key)
class MyDataset(Dataset):
#数据打包
#加载所有数据
#存储和初始化变量
def __init__(self,all_data,w1,word_2_index):
self.w1=w1
self.word_2_index=word_2_index
self.all_data=all_data
#获取一条数据,并做处理
def __getitem__(self, index):
a_poetry_words = self.all_data[index]
a_poetry_index = [self.word_2_index[word] for word in a_poetry_words]
xs_index = a_poetry_index[:-1]
ys_index = a_poetry_index[1:]
#取出31个字,每个字对应107维度向量,【31,107】
xs_embedding=self.w1[xs_index]
return xs_embedding,np.array(ys_index).astype(np.int64)
#获取数据总长度
def __len__(self):
return len(self.all_data)
class Mymodel(nn.Module):
def __init__(self,embedding_num,hidden_num,word_size):
super(Mymodel, self).__init__()
self.embedding_num=embedding_num
self.hidden_num = hidden_num
self.word_size = word_size
#num_layer:两层,代表层数,出来后的维度[5,31,64],设置hidden_num=64
self.lstm=nn.LSTM(input_size=embedding_num,hidden_size=hidden_num,batch_first=True,num_layers=2,bidirectional=False)
#做一个随机失活,防止过拟合,同时可以保持生成的古诗不唯一
self.dropout=nn.Dropout(0.3)
#做一个flatten,将维度合并【5*31,64】
self.flatten=nn.Flatten(0,1)
#加一个线性层:[64,词库大小]
self.linear=nn.Linear(hidden_num,word_size)
#交叉熵
self.cross_entropy=nn.CrossEntropyLoss()
def forward(self,xs_embedding,h_0=None,c_0=None):
xs_embedding=xs_embedding.to(device)
if h_0==None or c_0==None:
#num_layers,batch_size,hidden_size
h_0=torch.tensor(np.zeros((2,xs_embedding.shape[0],self.hidden_num),np.float32))
c_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num),np.float32))
h_0=h_0.to(device)
c_0=c_0.to(device)
hidden,(h_0,c_0)=self.lstm(xs_embedding,(h_0,c_0))
hidden_drop=self.dropout(hidden)
flatten_hidden=self.flatten(hidden_drop)
pre=self.linear(flatten_hidden)
return pre,(h_0,c_0)
def generate_poetry_auto():
result=''
#随机产生第一个字的下标
word_index=np.random.randint(0,word_size,1)[0]
result += index_2_word[word_index]
h_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
c_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
for i in range(23):
word_embedding=torch.tensor(w1[word_index].reshape(1,1,-1))
pre,(h_0,c_0)=model(word_embedding,h_0,c_0)
word_index=int(torch.argmax(pre))
result+=index_2_word[word_index]
print(result)
if __name__ == '__main__':
device="cuda" if torch.cuda.is_available() else "cpu"
print(device)
#源数据小了,batch不能太大
batch_size=128
all_data,(w1,word_2_index,index_2_word)=train_vec()
dataset=MyDataset(all_data,w1,word_2_index)
dataloader=DataLoader(dataset,batch_size=batch_size,shuffle=True)
epoch=1000
word_size , embedding_num=w1.shape
lr=0.003
hidden_num=128
model_result_file='model_lstm.pkl'
#测试代码
# if os.path.exists(model_result_file):
# model=pickle.load(open(model_result_file, "rb"))
# generate_poetry_auto()
#训练代码
model=Mymodel(embedding_num,hidden_num,word_size)
#放入gpu训练
model.to(device)
optimizer=torch.optim.AdamW(model.parameters(),lr=lr)
for e in range(epoch):
#按照指定的batch_size获取诗词条数【32,31,107】
#ys_index:torch.Size([32,31])
for batch_index,(xs_embedding,ys_index) in enumerate(dataloader):
xs_embedding=xs_embedding.to(device)
ys_index=ys_index.to(device)
pre,_=model.forward(xs_embedding)
loss=model.cross_entropy(pre,ys_index.reshape(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_index%100==0:
print(f"loss:{loss:.3f}")
generate_poetry_auto()
pickle.dump(model, open(model_result_file, "wb"))
五言藏头诗:

古今地名
初步想法
通过百度百科检索,获得对应的地理位置:例如:长安-->西安

可视化展示
高德地图进行标注:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<script type="text/javascript" src="https://webapi.amap.com/maps?v=1.4.15&key=49d67dfcd1879085d0aa42f03bbc44a2"></script>
<script type="text/javascript" src="js/jquery-3.4.1.js"></script>
<link href="//cdn.bootcss.com/bootstrap/3.3.5/css/bootstrap.min.css" rel="stylesheet">
<link rel="stylesheet" href="http://cache.amap.com/lbs/static/main1119.css"/>
</head>
<body>
<div class="map-container" id="container"></div>
</body>
<script type="text/javascript">
function markLocation(mapId, address) {
AMap.plugin('AMap.Geocoder', function() {
var geocoder = new AMap.Geocoder();
geocoder.getLocation(address, function(status, result) {
if (status === 'complete' && result.info === 'OK') {
// 经纬度
var lng = result.geocodes[0].location.lng;
var lat = result.geocodes[0].location.lat;
alert(lng+" "+lat);
// 地图实例
map = new AMap.Map(mapId, {
resizeEnable: true, // 允许缩放
center: [lng, lat], // 设置地图的中心点
zoom: 15 // 设置地图的缩放级别,0 - 20
});
// 添加标记
var marker = new AMap.Marker({
map: map,
position: new AMap.LngLat(lng, lat), // 经纬度
});
marker.content = '<h3>我是第1' + '个XXX</h3>';
marker.content += '<div>经度:'+lng+'</div>';
marker.content += '<div>纬度:'+lat+'</div>';
marker.content += '<div><button class="btn btn-suucess btn-xs">历史轨迹</button>';
marker.content += ' <button class="btn btn-warning btn-xs">实时跟踪 </button>';
marker.content += ' <button class="btn btn-danger btn-xs">设置</button></div>';
marker.on('mouseover', infoOpen);
//注释后打开地图时默认关闭信息窗体
//marker.emit('mouseover', {target: marker});
marker.on('mouseout', infoClose);
marker.on('click', newMAp);
alert("完成标记");
} else {
alert("定位失败返回值:"+status+result)
console.log('定位失败!');
}
//鼠标点击事件,设置地图中心点及放大显示级别
function newMAp(e) {
//map.setCenter(e.target.getPosition());
map.setZoomAndCenter(15, e.target.getPosition());
var infoWindow = new AMap.InfoWindow({offset: new AMap.Pixel(0, -30)});
infoWindow.setContent(e.target.content);
infoWindow.open(map, e.target.getPosition());
}
function infoClose(e) {
infoWindow.close(map, e.target.getPosition());
}
function infoOpen(e) {
infoWindow.setContent(e.target.content);
infoWindow.open(map, e.target.getPosition());
}
map.setFitView();
});
});
}
$(function(){
markLocation('container', '西安');
})
</script>
</html>
展示效果
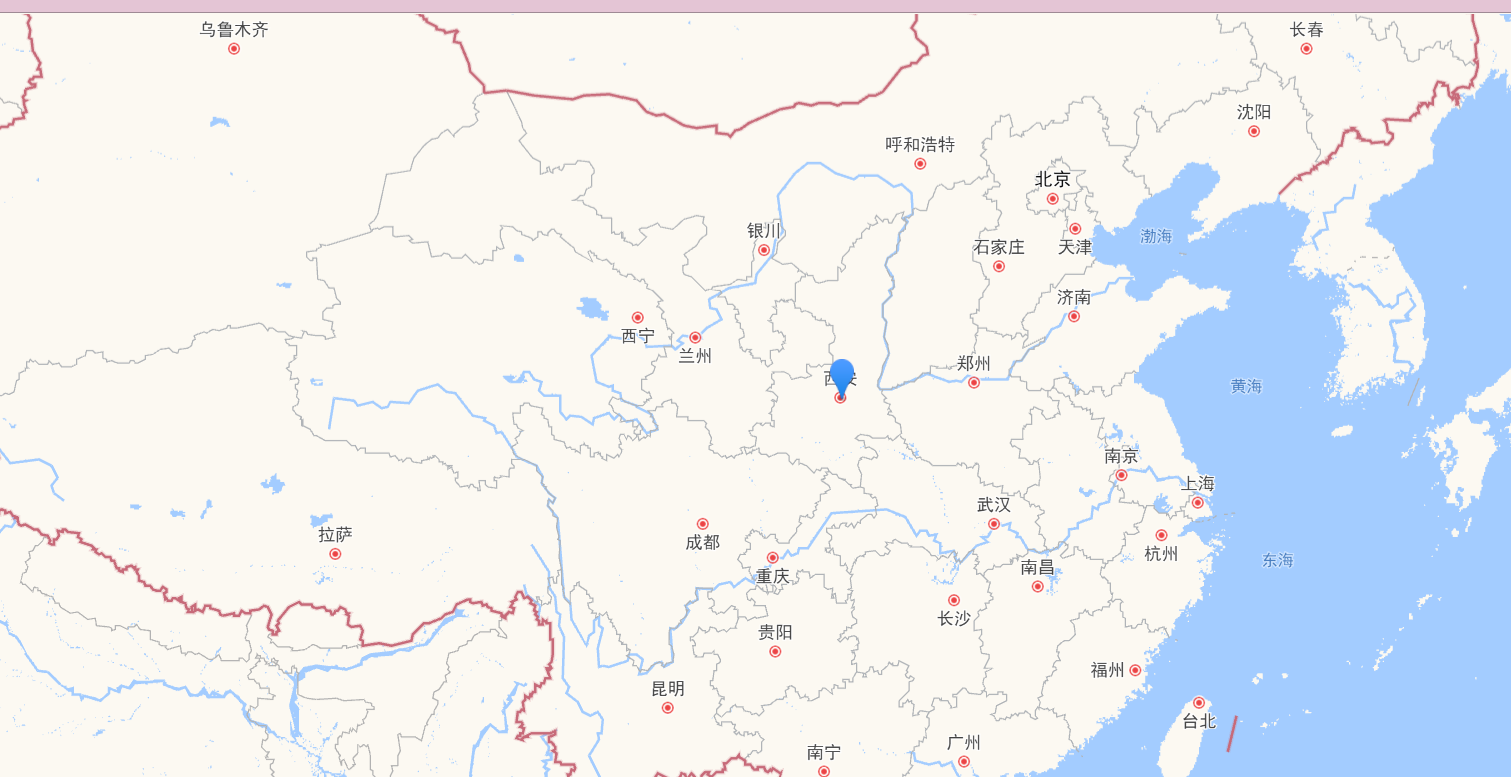
点击后,进入详细界面
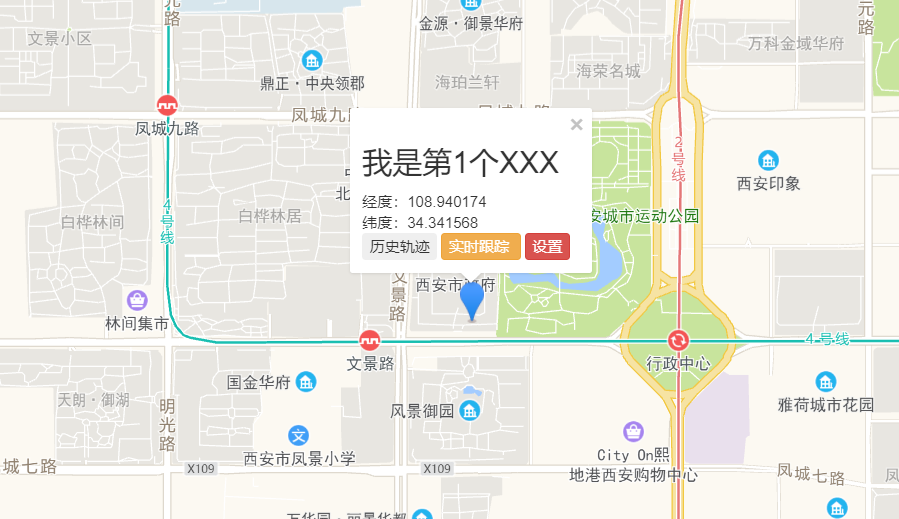
总结
明天主要完成所有诗人古代地名到现代地名的映射
映射的地名确保可以在高德地图上进行标注
利用高德地图进行测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号