1106-Dataset&DataLoader、softmax分类器
Dataset&DataLoader
代码
import numpy as np
import torch
from torch.utils.data import Dataset,DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
def __getitem__(self, item):
return self.x_data[item],self.y_data[item]
def __len__(self):
return self.len
dataset=DiabetesDataset('diabetes.csv.gz')
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
self.activate=torch.nn.ReLU()
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model=Model()
criterion=torch.nn.BCELoss(reduction='sum')
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,labels=data
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
实战泰坦尼克号
代码:
import numpy as np
import pandas as pd
from torch.utils.data import Dataset
import torch
class TaiDataset(Dataset):
def __init__(self,filepath):
feature= ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
data=pd.read_csv(filepath)
self.len=data.shape[0]
self.x_data=torch.from_numpy(np.array(pd.get_dummies(data[feature])))
self.y_data=torch.from_numpy(np.array(data['Survived']))
def __getitem__(self, item):
return self.x_data[item],self.y_data[item]
def __len__(self):
return self.len
#建立数据集
dataset=TaiDataset('./taitannik/train.csv')
# 建立数据集加载器
from torch.utils.data import DataLoader
train_loader = DataLoader(dataset=dataset, batch_size=2, shuffle=True, num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(6,3)
self.linear2 = torch.nn.Linear(3,1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
def predict(self,x):
with torch.no_grad():
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
y=[]
for i in x:
if i>0.5:
y.append(1)
else:
y.append(0)
return y
model=Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)
#train
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# 这里先转换了一下数据类型。
inputs = inputs.float()
labels = labels.float()
y_pred = model(inputs)
# 将维度压缩至1维。
y_pred = y_pred.squeeze(-1)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 读取test文件
test_data = pd.read_csv("./taitannik/test.csv")
features = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[features])))
# 进行预测
y = model.predict(test.float())
# 输出预测结果到文件
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('./taitannik/my_predict.csv', index=False)
预测

Softmax分类
手写体分类
import torch
import numpy as np
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size=64
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset=datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader=DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset=datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader=DataLoader(test_dataset,shuffle=True,batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1=torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x=x.view(-1,784)
x=F.relu(self.l1(x))
x=F.relu(self.l2(x))
x=F.relu(self.l3(x))
x=F.relu(self.l4(x))
return self.l5(x)
model=Net()
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target=data
optimizer.zero_grad()
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_size%300==299:
print('[%d, %5d] loss: %.3f'% (epoch+1,batch_size+1,running_loss/300))
running_loss=0.0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs.data,dim=1)
total+=labels.size(0)
correct+=(predicted == labels).sum().item()
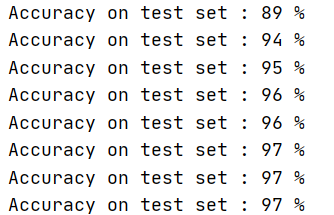
print('Accuracy on test set : %d %%' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号