1102-诗词类别补充与pyhanlp探索
诗词类别补充
爬取对应的唐代,宋代,元代,明代,清代的诗词类别
网站爬取的页面如下:
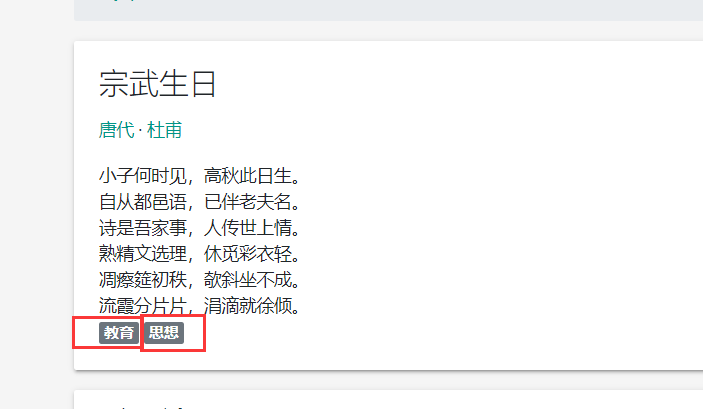
爬取代码:
不在重复爬取之前爬过的数据,直接爬取需要的分类信息
import requests
from bs4 import BeautifulSoup
from lxml import etree
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
pom_list=[]
k=1
for i in range(1,500):
url='https://www.xungushici.com/shicis/cd-qing-p-'+str(i)
r=requests.get(url,headers=headers)
content=r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
hed=soup.find('div',class_='col col-sm-12 col-lg-9')
list=hed.find_all('div',class_="card mt-3")
# print(len(list))
for it in list:
content = {}
#1.1获取单页所有诗集
href=it.find('h4',class_='card-title').a['href']
real_href='https://www.xungushici.com'+href
title=it.find('h4',class_='card-title').a.text
#print(title)
#2.1爬取诗词
get = requests.get(real_href).text
selector = etree.HTML(get)
#2.2获取标题
xtitle=selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/h3/text()')[0]
# 2.3获取朝代
# desty=selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/p/a/text()')[0]
# 2.4获取作者
# if len(selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/p/span/text()'))==0:
# author=selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/p/a[2]/text()')[0]
# else:
# author =selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/p/span/text()')[0]
#2.5诗词分类
tag=""
if len(selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/div[2]//a'))!=0:
tag=selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/div[2]//a/text()')
tag=",".join(tag)
#
# 2.6获取文章
# ans=""
# if len(selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/div[1]/p/text()'))==0:
# artical=selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/div[1]/text()')
# for it in artical:
# ans=ans+it.replace("\r","").replace("\t","").replace("\n","")
# else:
# artical = selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div/div[1]/p/text()')
# for it in artical:
# ans=ans+it.replace("\r","").replace("\t","").replace("\n","")
# 2.7获取译文
# trans=""
# flag=0
# for j in range(2,8):
# path='/html/body/div[1]/div/div[1]/div[2]/div[2]/p[%d]'%j
# if selector.xpath(path+'/text()')==[]:
# break
# else:
# translist=selector.xpath(path+'/text()')
# for it in translist:
# trans = trans + it + "\n"
# 2.8获取鉴赏
# appear=""
# for j in range(1,19):
# path='/html/body/div[1]/div/div[1]/div[3]/div[2]/p[%d]'%j
# if selector.xpath(path+'/text()')==[]:
# break
# else:
# apperlist=selector.xpath(path+'/text()')
# for it in apperlist:
# appear = appear + it + "\n"
# 2.9创作背景
# background=selector.xpath('/html/body/div[1]/div/div[1]/div[4]/div[2]/p/text()')
# text_back=""
# if background!=[]:
# for it in background:
# text_back=text_back+it+"\n"
content['title']=xtitle
# content['desty']=desty
# content['author']=author
# content['content']=ans
# content['trans_content']=trans
# content['appear']=appear
# content['background']=text_back
content['tag']=tag
pom_list.append(content)
print("第"+str(k)+"个")
k=k+1
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0,0,"title")
# sheet1.write(0,1,'desty')
# sheet1.write(0,2,'author')
# sheet1.write(0,3,'content')
# sheet1.write(0,4,'trans_content')
# sheet1.write(0,5,'appear')
# sheet1.write(0,6,'background')
sheet1.write(0,7,'tag')
for i in range(0,len(pom_list)):
sheet1.write(i+1,0,pom_list[i]['title'])
# sheet1.write(i+1, 1, pom_list[i]['desty'])
# sheet1.write(i+1, 2, pom_list[i]['author'])
# sheet1.write(i+1, 3, pom_list[i]['content'])
# sheet1.write(i+1, 4, pom_list[i]['trans_content'])
# sheet1.write(i+1, 5, pom_list[i]['appear'])
# sheet1.write(i+1, 6, pom_list[i]['background'])
sheet1.write(i + 1, 7, pom_list[i]['tag'])
xl.save("qing_tag.xlsx")
# print(pom_list)
结果如下:类别之间用","分割

pyhanlp探索
分词
from pyhanlp import *
#1.分词
sentence = "我爱北京天安门,天安门上放光彩"
#返回一个list,每个list是一个分词后的Term对象,可以获取word属性和nature属性,分别对应的是词和词性
terms = HanLP.segment(sentence )
for term in terms:
print(term.word,term.nature)

关键词提取与自动摘要
document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \
"有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \
"严格地进行水资源论证和取水许可的批准。"
#提取document的两个关键词
print(HanLP.extractKeyword(document, 2))
#提取ducument中的3个关键句作为摘要
print(HanLP.extractSummary(document,3))

依存句法分析
#依存句法分析
print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
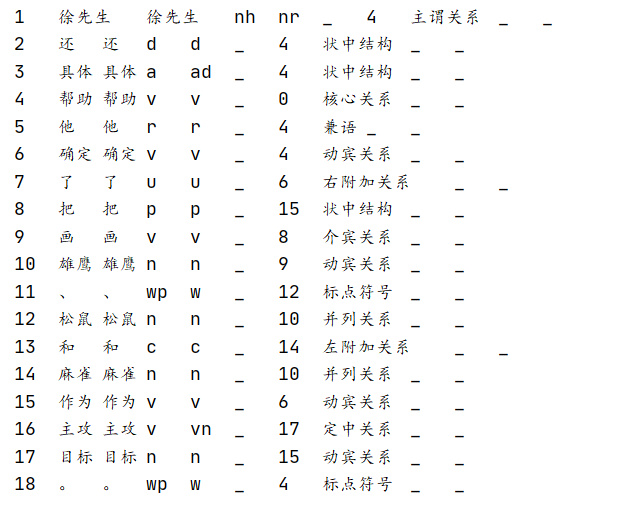
短语提取
text = "在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法"
phraseList = HanLP.extractPhrase(text, 10)
print(phraseList);


 浙公网安备 33010602011771号
浙公网安备 33010602011771号