机器学习十讲-第三讲分类
感知机
原理

下面用一个 perception 函数实现上述算法。为了深入观察算法运行过程,我们保留了每一轮迭代的参数 ww,并对每一轮迭代中随机选取的样本也进行了记录。所以,perception 函数返回三个取值: 最终学习到的参数 w, 每轮迭代的参数 W, 每轮迭代随机选取的样本 mis_samples 。
代码实现
def perception(X,y,learning_rate,max_iter=1000): w = pd.Series(data=np.zeros_like(X.iloc[0]),index=X.columns) # 初始化参数 w0 W = [w] # 定义一个列表存放每次迭代的参数 mis_samples = [] # 存放每次误分类的样本 for t in range(max_iter): # 2.1 寻找误分类集合 M m = (X.dot(w))*y #yw^Tx < 0 的样本为误分类样本 X_m = X[m <= 0] # 误分类样本的特征数据 y_m = y[m <= 0] # 误分类样本的标签数据 if(len(X_m) > 0): # 如果有误分类样本,则更新参数;如果不再有误分类样本,则训练完毕。 # 2.2 从 M 中随机选取一个样本 i i = np.random.randint(len(X_m)) mis_samples.append(X_m.iloc[i,:]) # 2.3 更新参数 w w = w + learning_rate * y_m.iloc[i]*X_m.iloc[i,:] W.append(w) else: break mis_samples.append(pd.Series(data=np.zeros_like(X.iloc[0]),index=X.columns)) return w,W,mis_samples
w_percept,W,mis_samples = perception(data[["x1","x2","ones"]], data["label"],1,max_iter=1000)
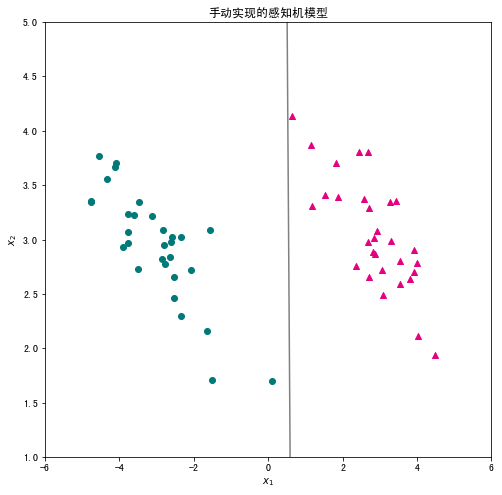
将学习到的感知机的决策直线可视化,观察分类效果。
x1 = np.linspace(-6, 6, 50)
x2 = - (w_percept[0]/w_percept[1])*x1 - w_percept[2]/w_percept[1]
plt.figure(figsize=(8, 8)) #设置图片尺寸 plt.scatter(data_pos["x1"],data_pos["x2"],c="#E4007F",marker="^") # 类别为1的数据绘制成洋红色 plt.scatter(data_neg["x1"],data_neg["x2"],c="#007979",marker="o") # 类别为-1的数据绘制成深绿色 plt.plot(x1,x2,c="gray") # 画出分类直线 plt.xlabel("$x_1$") #设置横轴标签 plt.ylabel("$x_2$") #设置纵轴标签 plt.title('手动实现的感知机模型') plt.xlim(-6,6) #设置横轴显示范围 plt.ylim(1,5) #设置纵轴显示范围 plt.show()
展示:
逻辑回归
原理

代码实现
梯度下降法求解逻辑回归
import numpy as np # 定义梯度下降法求解的迭代公式 def logistic_regression(X,y,learning_rate,max_iter=1000): # 初始化w w = np.zeros(X.shape[1]) for t in range(max_iter): # 计算yX yx = y.values.reshape((len(y),1)) * X # 计算1 + e^(yXW) logywx = (1 + np.power(np.e,X.dot(w)*y)).values.reshape(len(y),1) w_grad = np.divide(yx,logywx).sum() # 迭代w w = w + learning_rate * w_grad return w
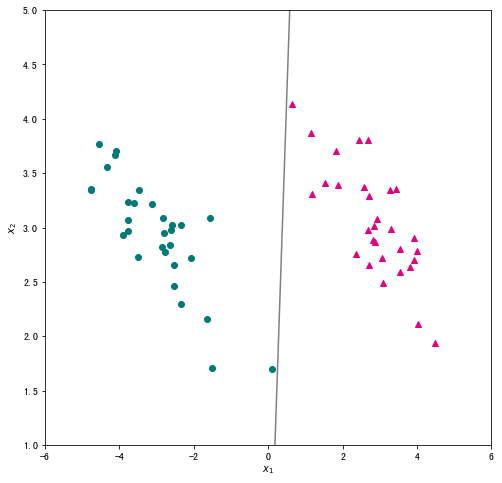
我们将数据及标签带入上面定义的函数,学习率设为 0.5 ,迭代次数为1000次,输出训练好的参数,并将分类结果进行可视化。
# 输出训练好的参数 w = logistic_regression(data[["x1","x2","ones"]], data["label"],0.5,max_iter=1000) print(w) # 可视化分类结果 x1 = np.linspace(-6, 6, 50) x2 = - (w[0]/w[1])*x1 - w[2]/w[1] plt.figure(figsize=(8, 8)) plt.scatter(data_pos["x1"],data_pos["x2"],c="#E4007F",marker="^") # 类别为1的数据绘制成洋红色 plt.scatter(data_neg["x1"],data_neg["x2"],c="#007979",marker="o") # 类别为-1的数据绘制成深绿色 plt.plot(x1,x2,c="gray") plt.xlabel("$x_1$") plt.ylabel("$x_2$") plt.xlim(-6,6) plt.ylim(1,5) plt.show()
随机梯度下降法求解逻辑回归

# 定义随机梯度下降法求解的迭代公式 def logistic_regression_sgd(X,y, learning_rate, max_iter=1000): # 初始化w w = np.zeros(X.shape[1]) for t in range(max_iter): # 随机选择一个样本 i = np.random.randint(len(X)) # 计算yx yixi = y[i] * X.values[i] # 计算1 + e^(yxW) logyiwxi = 1 + np.power(np.e, w.T.dot(X.values[i])*y[i]) w_grad = yixi / logyiwxi # 迭代w w = w + learning_rate * w_grad return w
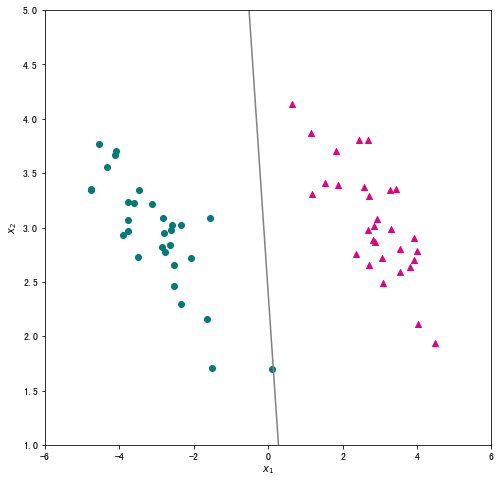
我们将学习率设为 0.5,迭代次数为1000次,并输出训练好的参数,将分类结果可视化。
# 输出训练好的参数 w = logistic_regression_sgd(data[["x1","x2","ones"]], data["label"],0.5,max_iter=1000) print(w) # 可视化分类结果 x1 = np.linspace(-6, 6, 50) x2 = - (w[0]/w[1])*x1 - w[2]/w[1] plt.figure(figsize=(8, 8)) plt.scatter(data_pos["x1"],data_pos["x2"],c="#E4007F",marker="^") # 类别为1的数据绘制成洋红色 plt.scatter(data_neg["x1"],data_neg["x2"],c="#007979",marker="o") # 类别为-1的数据绘制成深绿色 plt.plot(x1,x2,c="gray") plt.xlabel("$x_1$") plt.ylabel("$x_2$") plt.xlim(-6,6) plt.ylim(1,5) plt.show()
向量机
原理

代码实现
import numpy as np import matplotlib.pyplot as plt %matplotlib inline # 定义函数 def linear_svm(X,y,lam,max_iter=2000): w = np.zeros(X.shape[1]) # 初始化w support_vectors = [] # 创建空列表保存支持向量 for t in range(max_iter): # 进行迭代 learning_rate = 1/(lam * (t + 1)) # 计算本轮迭代的学习率 i = np.random.randint(len(X)) # 从训练集中随机抽取一个样本 ywx = w.T.dot(X.values[i])*y[i] # 计算y_i w^T x_i if ywx < 1:# 进行指示函数的判断 w = w - learning_rate * lam*w + learning_rate * y[i] * X.values[i] # 更新参数 else: w = w - learning_rate * lam*w # 更新参数 for i in range(len(X)): ywx = w.T.dot(X.values[i])*y[i] # 计算y_i w^T x_i if ywx <= 1: # 根据样本是否位于间隔附近判断是否为支持向量 support_vectors.append(X.values[i]) return w,support_vectors
需要注意的是,线性支持向量机的正则化项通常不包括截距项,我们可以将数据进行中心化,再调用上述代码。
# 对训练集数据进行归一化,则模型无需再计算截距项 X = data[["x1","x2"]].apply(lambda x: x - x.mean()) # 训练集标签 y = data["label"] w,support_vectors = linear_svm(X,y, lam=0.05, max_iter=5000)
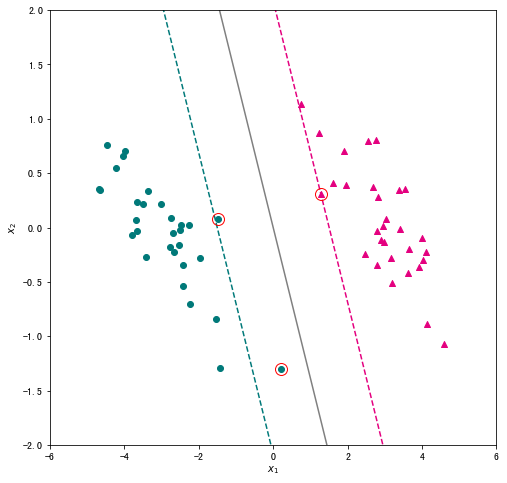
将得到的超平面可视化,同时将两个函数间隔为 1 的线也绘制出来。对于所有不满足约束的样本,使用圆圈标记出来。
# 创建绘图框 plt.figure(figsize=(8, 8)) # 绘制两类样本点 X_pos = X[ y==1 ] X_neg = X[ y==-1 ] plt.scatter(X_pos["x1"],X_pos["x2"],c="#E4007F",marker="^") # 类别为1的数据绘制成洋红色 plt.scatter(X_neg["x1"],X_neg["x2"],c="#007979",marker="o") # 类别为-1的数据绘制成深绿色 # 绘制超平面 x1 = np.linspace(-6, 6, 50) x2 = - w[0]*x1/w[1] plt.plot(x1,x2,c="gray") # 绘制两个间隔超平面 plt.plot(x1,-(w[0]*x1+1)/w[1],"--",c="#007979") plt.plot(x1,-(w[0]*x1-1)/w[1],"--",c="#E4007F") # 标注支持向量 for x in support_vectors: plt.plot(x[0],x[1],"ro", linewidth=2, markersize=12,markerfacecolor='none') # 添加轴标签和限制轴范围 plt.xlabel("$x_1$") plt.ylabel("$x_2$") plt.xlim(-6,6) plt.ylim(-2,2)
实例-新闻主题分类
步骤
读取数据
raw_train = pd.read_csv("./input/chinese_news_cutted_train_utf8.csv",sep="\t",encoding="utf8") raw_test = pd.read_csv("./input/chinese_news_cutted_test_utf8.csv",sep="\t",encoding="utf8")
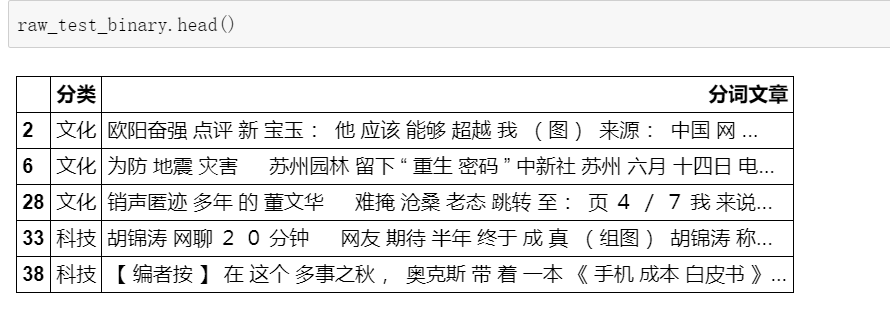
查看训练集的前5行。
raw_train.head()

为了简单,我们这里先只考虑二分类,我们选取主题为"科技"和“文化”新闻。
raw_train_binary = raw_train[((raw_train["分类"] == "科技") | (raw_train["分类"] == "文化"))] raw_test_binary = raw_test[((raw_test["分类"] == "科技") | (raw_test["分类"] == "文化"))]

模型效果评估
下面使用混淆矩阵来分析模型在测试集上的表现。混淆矩阵从样本的真实标签和模型预测标签两个维度对测试集样本进行分组统计,然后以矩阵的形式展示。借助混淆矩阵可以很好地分析模型在每一类样本上的分类效果。为了更直观地分析,我们借助 Python 中的可视化库 Seaborn 提供的 heatmap 函数,将线性支持向量机模型的混淆矩阵进行可视化。
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(5,5)) # 设置正常显示中文 sns.set(font='SimHei') # 绘制热力图 y_svm_pred = lsvm_clf.predict(X_test) # 预测标签 y_test_true = raw_test_binary["分类"] #真实标签 confusion_matrix = confusion_matrix(y_svm_pred,y_test_true)#计算混淆矩阵 ax = sns.heatmap(confusion_matrix,linewidths=.5,cmap="Greens", annot=True, fmt='d',xticklabels=lsvm_clf.classes_, yticklabels=lsvm_clf.classes_) ax.set_ylabel('真实') ax.set_xlabel('预测') ax.xaxis.set_label_position('top') ax.xaxis.tick_top() ax.set_title('混淆矩阵热力图')
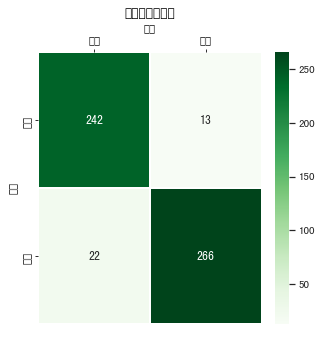
可见:正对角线还是比较集中的,代表效果还不错
总结
在本案例中,我们使用随机梯度方法实现了三种使用回归的思想来解决分类问题的模型:感知机、逻辑回归和线性支持向量机。在实现时主要使用了 NumPy, Pandas 和 Matplotlib 等 Python 库。在 Sklearn 中,linear.model.SGDClassifier 类实现了常见算法的随机梯度下降实现。我们使用该类,在一份中文新闻数据上分别用随机梯度下降算法训练了感知机、逻辑回归和线性支持向量机模型,实现了对中文新闻主题的分类。最后,使用 Sklearn.metrics 实现的模型评价方法,用正确率和混淆矩阵对分类效果进行了简单的分析。
import numpy as np import matplotlib.pyplot as plt %matplotlib inline yfx = np.linspace(-4, 4, 500) perception = [0 if i >= 0 else -i for i in yfx] hinge = [(1-i) if i <= 1 else 0 for i in yfx] log = np.log2(1 + np.power(np.e,-yfx)) plt.figure(figsize=(8, 6)) plt.plot(yfx,perception,c="b",label="感知机损失") plt.plot(yfx,hinge,c="g",label="合页损失(SVM)") plt.plot(yfx,log,c="red",label="对数损失(LR)") plt.hlines(1,-4,0) plt.vlines(0,0,1) plt.xlabel("$yf(x)$") plt.ylabel("$L_i(y_i,yf(x))$") plt.xlim(-4,4) plt.ylim(0,6) plt.legend()
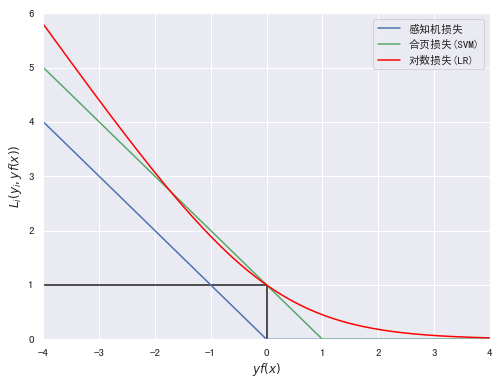
以下为绘制三种分类模型的从回归到分类的映射函数。
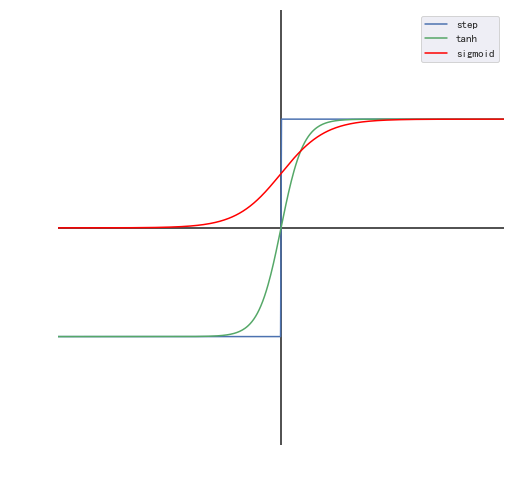
import numpy as np import matplotlib.pyplot as plt %matplotlib inline #创建画布并引入axisartist工具。 import mpl_toolkits.axisartist as axisartist #创建画布 fig = plt.figure(figsize=(8, 8)) fx = np.linspace(-10, 10, 500) step = [1 if i >= 0 else -1 for i in fx] tanh = np.tanh(fx) sigmoid = 1/(1 + np.power(np.e,-fx)) plt.axhline(0,-10,10,color="k") plt.axvline(0,-2,2,color="k") plt.plot(fx,step,c="b",label="step") plt.plot(fx,tanh,c="g",label="tanh") plt.plot(fx,sigmoid,c="red",label="sigmoid") plt.xlabel("$f$") plt.ylabel("$H(f)$") plt.grid(False) plt.xlim(-10, 10) plt.ylim(-2,2) plt.axis('off') plt.legend()
raw_train = pd.read_csv("./input/chinese_news_cutted_train_utf8.csv",sep="\t",encoding="utf8")raw_test = pd.read_csv("./input/chinese_news_cutted_test_utf8.csv",sep="\t",encoding="utf8")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号