机器学习十讲-第一讲
有监督学习
含义
数据集中的样本带有标签,有明确目标
回归和分类
回归模型:线性回归、岭回归、LASSO和回归样条等
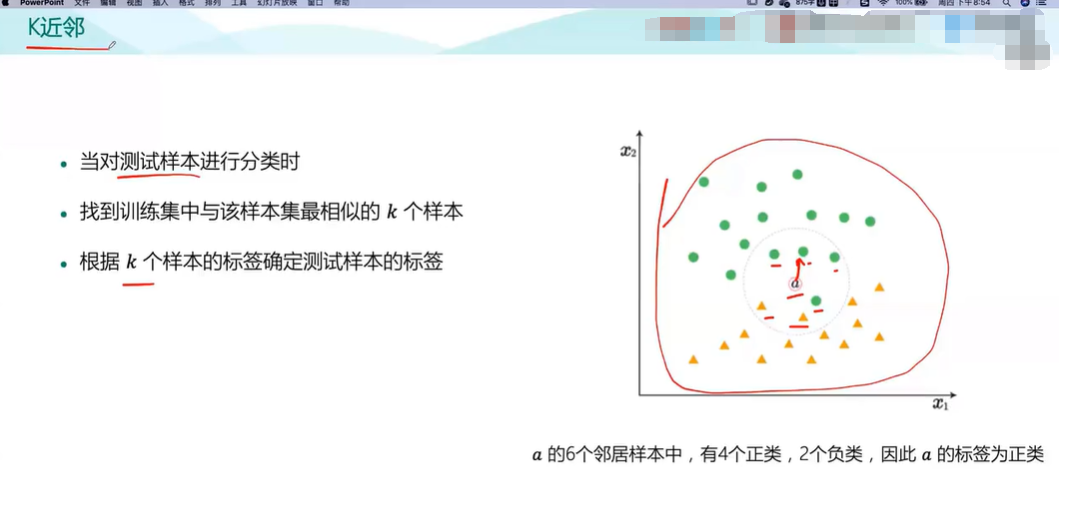
分类模型:逻辑回归、K近邻、决策树、支持向量机等
应用场景
垃圾邮件分类、病理切片分类、客户流失预警、客户风险评估、房价预测等。
无监督学习( unsupervised learning )
含义
数据集中的样本没有标签,没有明确目标
无监督学习:根据数据本身的分布特点,挖掘反映数据的内在特性
聚类
将数据集中相似的样本进行分组,使得:
- 同一组对象之间尽可能相似; .
- 不同组对象之间尽可能不相似。
应用场景
基因表达水平聚类:根据不同基因表达的时序特征进行聚类,得到基因表达处于信号通路
上游还是下游的信息
篮球运动员划分:根据球员相关数据,将其划分到不同类型(或者不同等级)的运动员阵
营中
客户分析:把客户细分成不同客户群,每个客户群有相似行为,做到精准营销
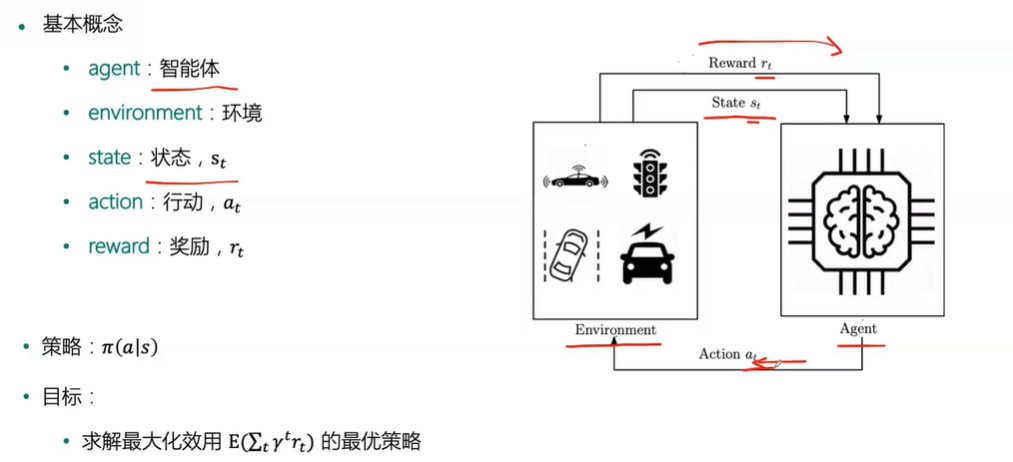
强化学习( reinforcement learing )
含义
智慧决策的过程,通过过程模拟和观察来不断学习、提高决策能力
流程
实例
例如: AlphaGo
数学结构
数据也是有数学结构的,没有数学结构我们便无法处理数据。
度量结构
表示数据之间的距离。
网络结构
有些数据本身就有网络结构,如社交网络。如果没有,可以利用度量结构给数据附加一个网络结构。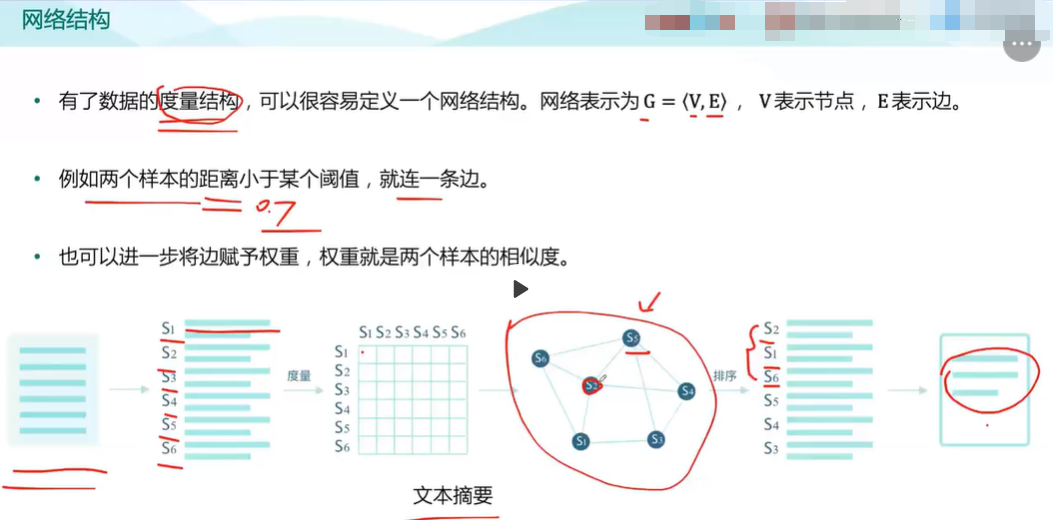
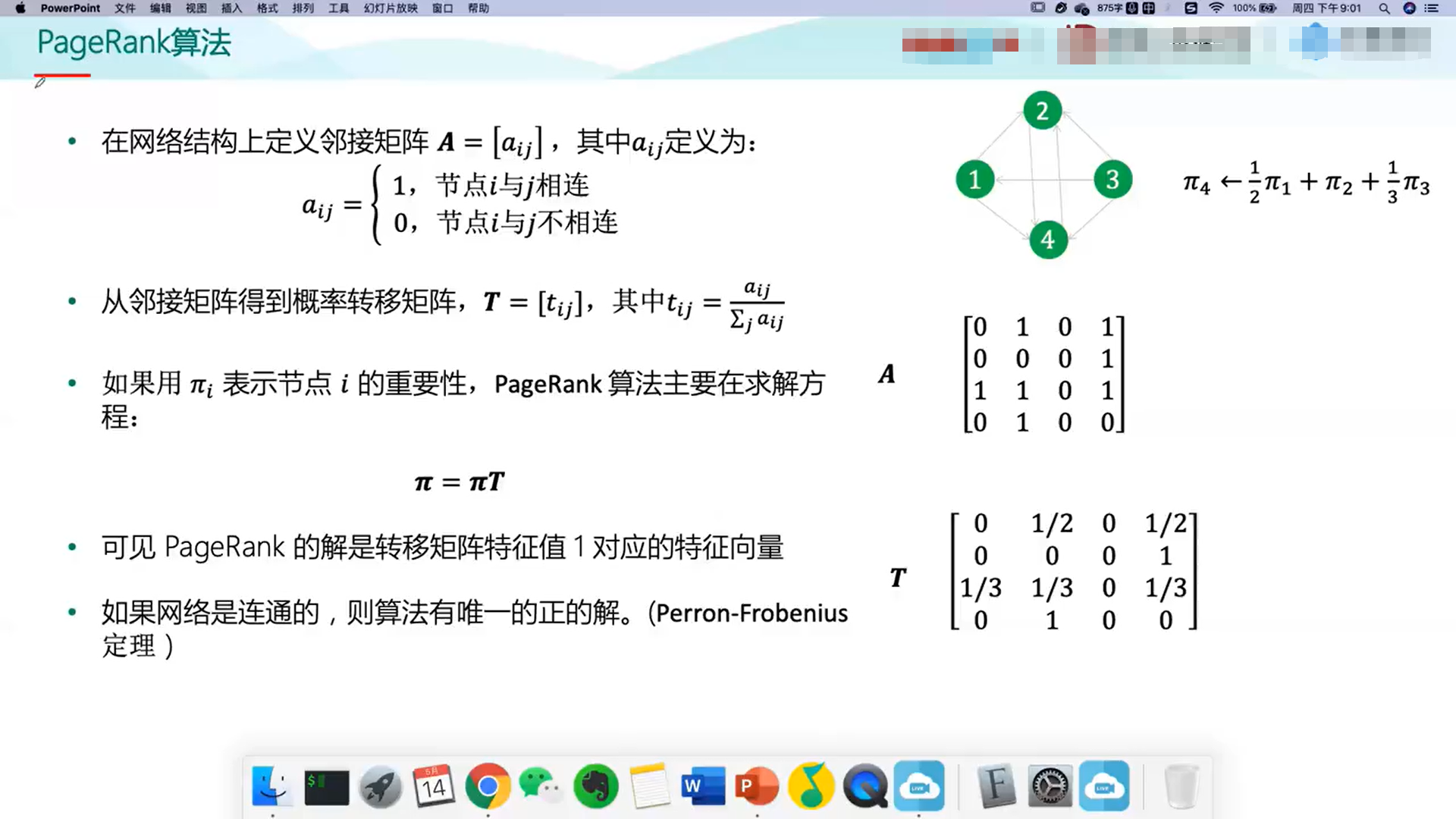
计算所用的算法如下:
代数结构
将数据看作向量、矩阵或更高阶的张量。
几何结构
流形、对称性等
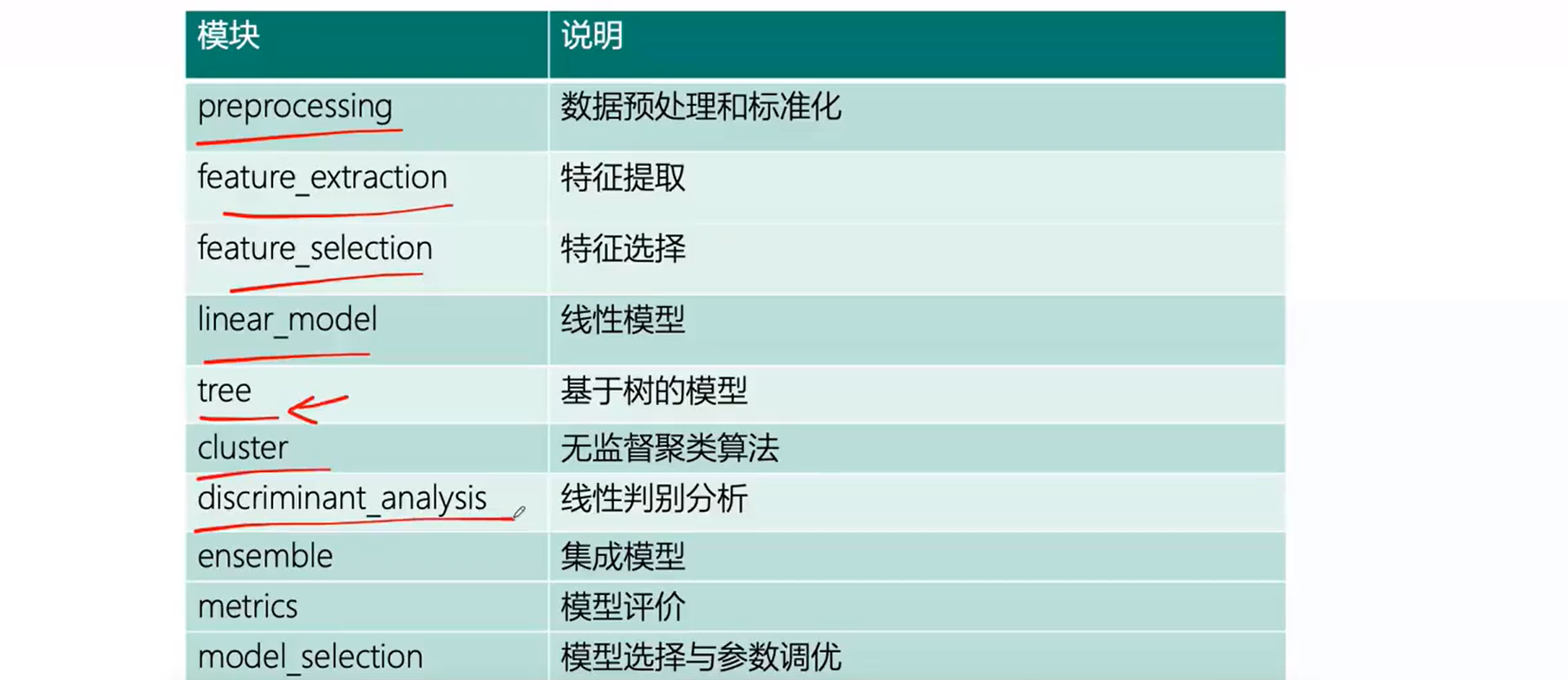
Scikit-learn
常用函数

主要模块
总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号