机器学习3-分类算法
数据集介绍与划分
数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
API
- sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return ,测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
sklearn转换器和估计器
转换器和估计器
转换器
想一下之前做的特征工程的步骤?
- 1、实例化 (实例化的是一个转换器类(Transformer))
- 2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式
- fit_transform
- fit
- transform
估计器(sklearn机器学习算法的实现)
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
- 1、用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
- 2、用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
- 3、用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
估计器工作流程
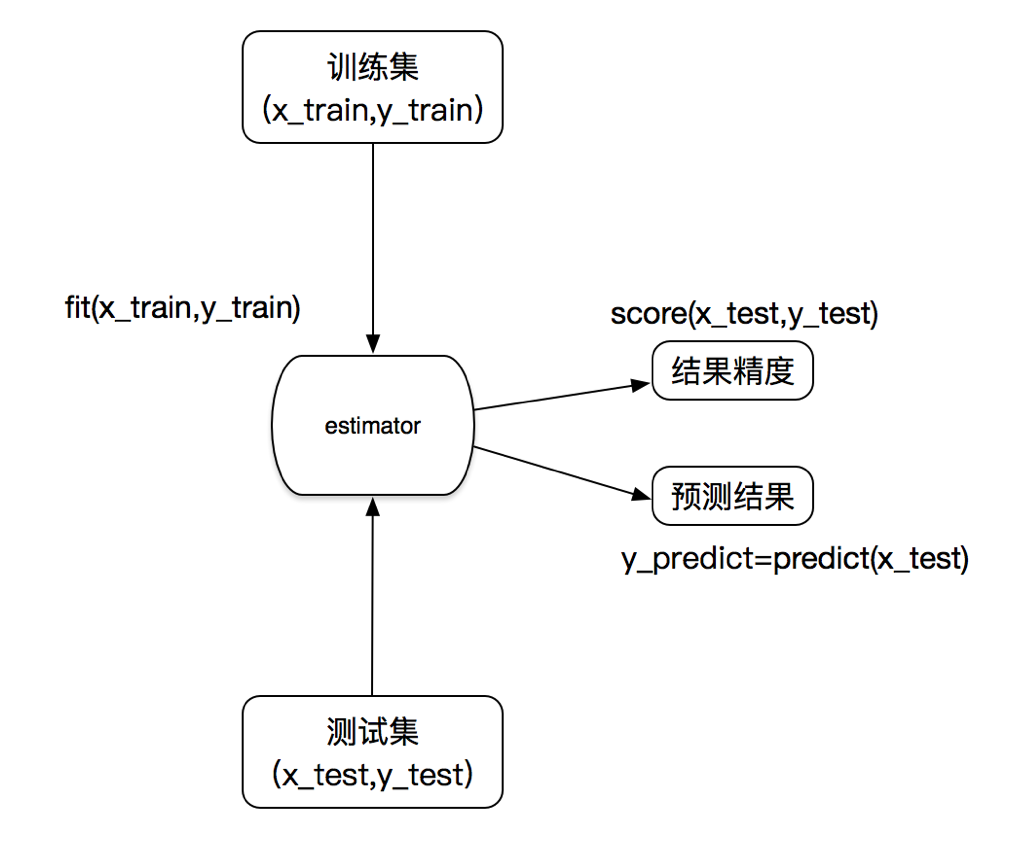
K-近邻算法
1、K-近邻算法(KNN)
1.1 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
1.2 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
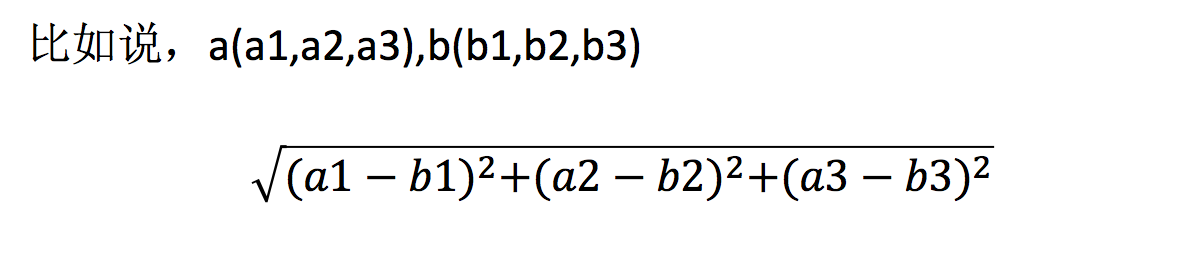
2、电影类型分析
假设我们有现在几部电影
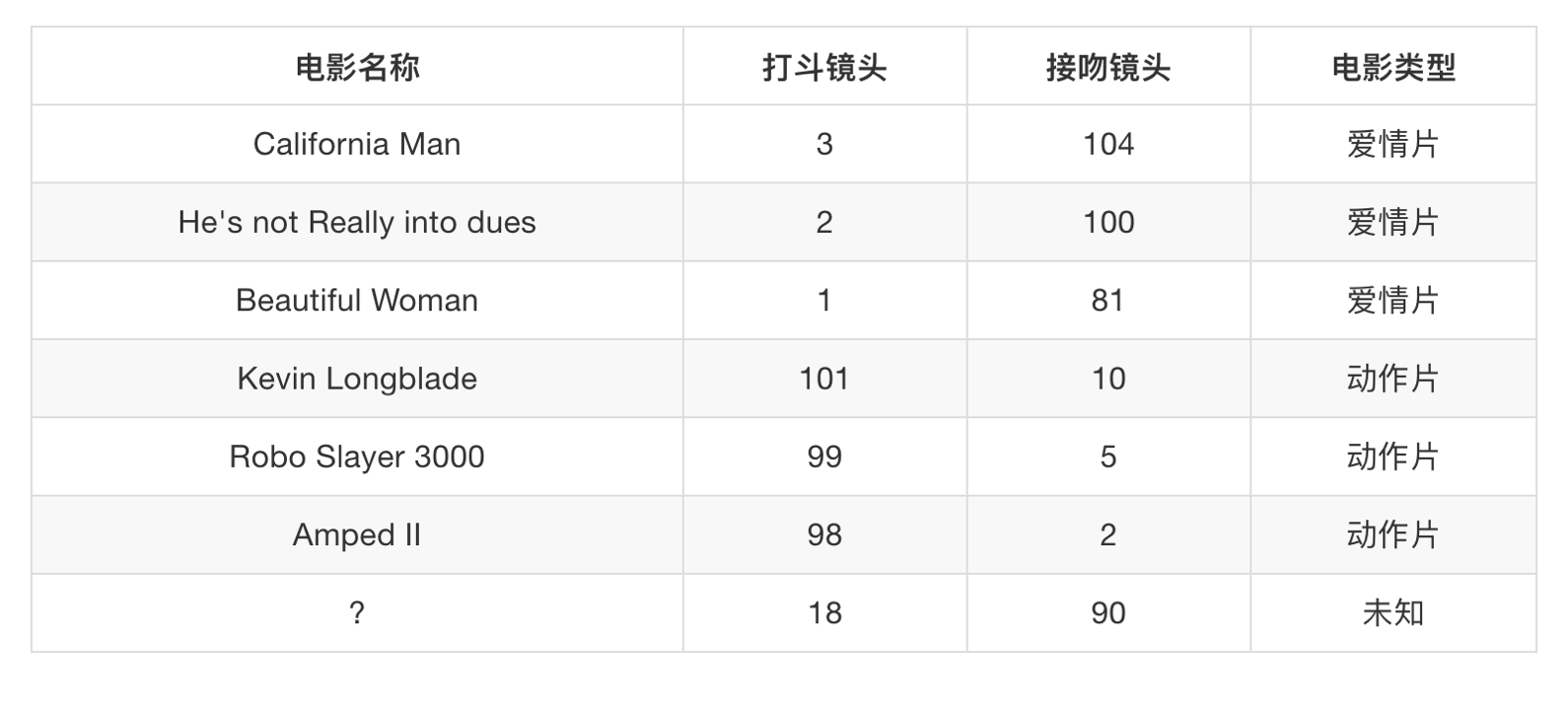
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
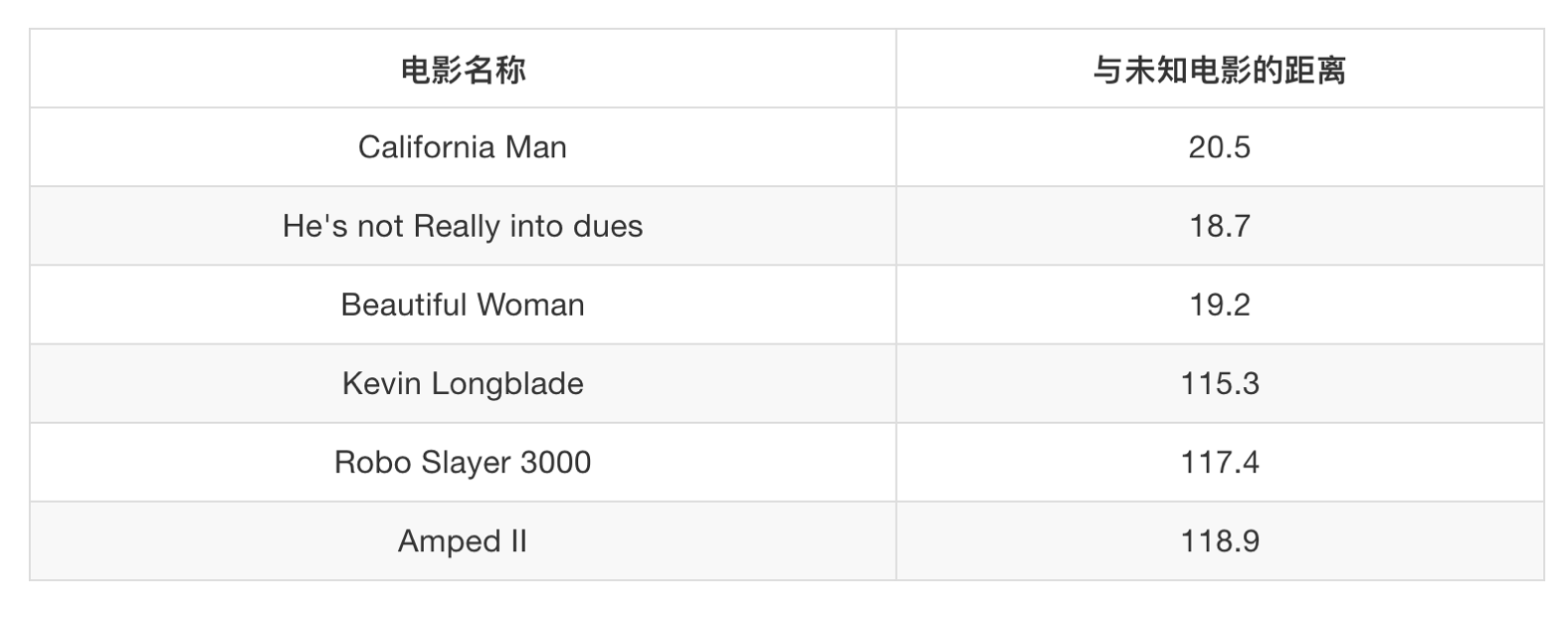
2.1 问题
- 如果取的最近的电影数量不一样?会是什么结果?
2.2 K-近邻算法数据的特征工程处理
- 结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
3、K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
def knn_iris():
"""
KNN算法对鸢尾花进行分类
"""
#获取数据
iris=load_iris()
#划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=3)
#特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#KNN算法预估器
estimator=KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
#模型评估
#方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test==y_predict)
#方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\n",score)
return None
结果为:

4.3 结果分析
准确率: 分类算法的评估之一
- 1、k值取多大?有什么影响?
k值取很小:容易受到异常点的影响
k值取很大:受到样本均衡的问题
- 2、性能问题?
距离计算上面,时间复杂度高
5、K-近邻总结
- 优点:
- 简单,易于理解,易于实现,无需训练
- 缺点:使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
模型选择与调优
1、为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
2、什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
2.1 分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
3、超参数搜索-网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3.1 模型选择与调优
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore:在交叉验证中验证的最好结果_
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
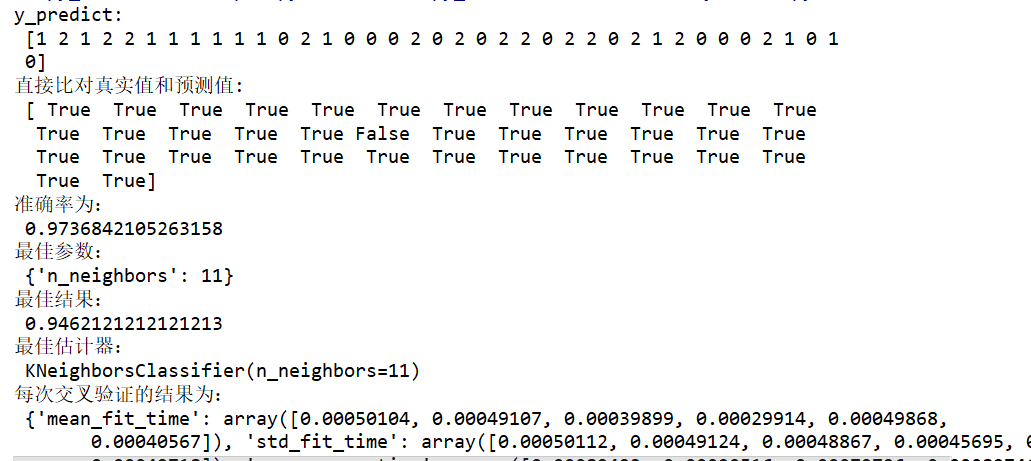
def knn_iris_gscv():
"""
KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
"""
#获取数据
iris=load_iris()
#划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=36)
#特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#KNN算法预估器
estimator=KNeighborsClassifier()
#加上网格搜索与交叉验证
param_dict={"n_neighbors":[1,3,5,7,9,11]}
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)
estimator.fit(x_train,y_train)
#模型评估
#方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test==y_predict)
#方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\n",score)
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳估计器:\n", estimator.best_estimator_)
print("每次交叉验证的结果为:\n", estimator.cv_results_)
return None
结果为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号