Spark学习进度-RDD算子
RDD算子
深入RDD
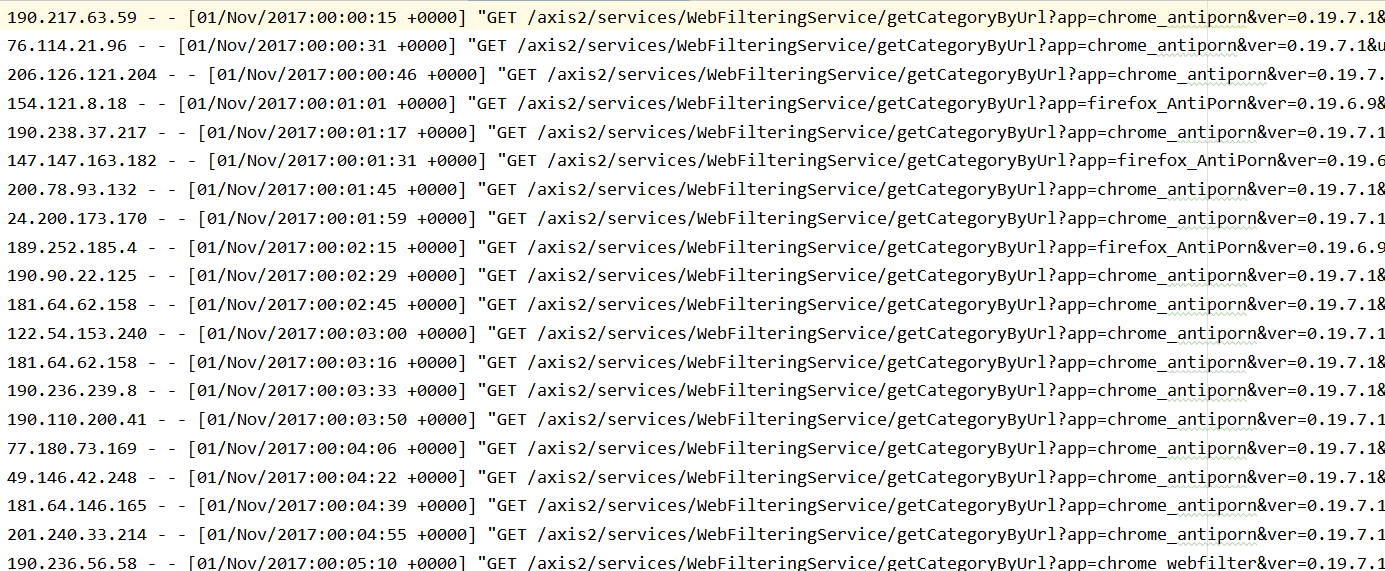
需求
-
给定一个网站的访问记录, 俗称 Access log
-
计算其中出现的独立 IP, 以及其访问的次数
代码:
@Test
def ipAGG(): Unit ={
//1.创建SparkContext
val conf=new SparkConf().setMaster("local[6]").setAppName("ip_agg")
val sc=new SparkContext(conf)
//2.读取文件,生成数据集
val sourceRDD=sc.textFile("dataset/access_log_sample.txt")
//3.取出IP,赋予出现次数为1
val ipRDD = sourceRDD.map(item => (item.split(" ")(0), 1))
//4.简单清洗
// 4.1去掉空数据
// 4.2去掉非法数据
// 4.3根据业务规整下数据
val cleanRDD = ipRDD.filter(item => StringUtils.isNotEmpty(item._1))
//5.根据IP出现次数进行聚合
val ipAggRDD = cleanRDD.reduceByKey((curr, agg) => curr + agg)
//6.根据IP出现的次数进行排序
val sortRDD = ipAggRDD.sortBy(item => item._2, ascending = false)
//7.取出结果,打印结果
sortRDD.take(10).foreach(item => println(item))
}
RDD解决迭代计算低效问题

在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
/ 线性回归
val points = sc.textFile(...)
.map(...)
.persist(...)
val w = randomValue
for (i <- 1 to 10000) {
val gradient = points.map(p => p.x * (1 / (1 + exp(-p.y * (w dot p.x))) - 1) * p.y)
.reduce(_ + _)
w -= gradient
}
在这个例子中, 进行了大致 10000 次迭代, 如果在 MapReduce 中实现, 可能需要运行很多 Job, 每个 Job 之间都要通过 HDFS 共享结果, 熟快熟慢一窥便知
RDD特点
RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子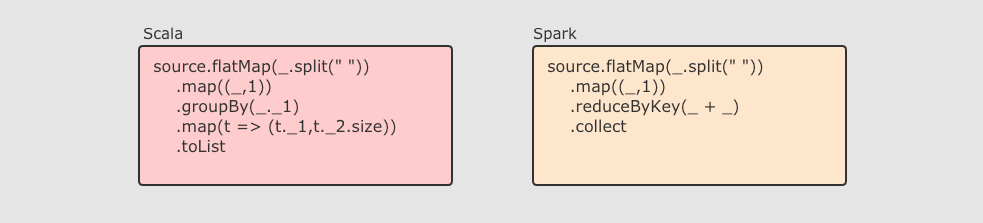
RDD 的算子大致分为两类:
- Transformation 转换操作, 例如 map flatMap filter 等
- Action 动作操作, 例如 reduce collect show 等
RDD 可以分区
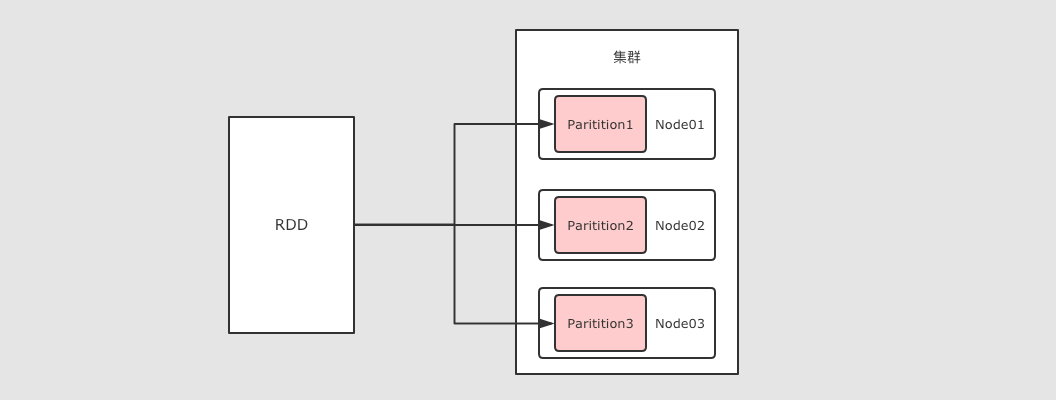
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
RDD 是可以容错的

RDD 的容错有两种方式
- 保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
- 直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
RDD算子
分类
RDD 中的算子从功能上分为两大类
- Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
- Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
- 针对基础类型(例如 String)处理的普通算子
- 针对 Key-Value 数据处理的 byKey 算子
- 针对数字类型数据处理的计算算子
特点
- Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
- 默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用 presist 方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
Transformations 算子
filter
算子的主要作用是过滤掉不需要的内容
/*
filter可以过滤掉数据集中的一部分元素
*/
@Test
def filter(): Unit ={
//1.定义集合
//2.过滤数据
//3.收集结果
sc.parallelize(Seq(1,2,3,4,56,7,8,9,10))
.filter( item => item%2 ==0)
.collect()
.foreach(item => println(item))
}
输出:全为偶数
mapPartitions
和 map 类似, 但是针对整个分区的数据转换
@Test
def mapPartitions2(): Unit ={
//1.数据生成
//2.数据处理
//3.获取结果
sc.parallelize(Seq(1,2,3,4,5,6),2)
.mapPartitions(iter => {
iter.map(iter => iter*10)
})
.collect()
.foreach(iter=>println(iter))
}

mapPartitionsWithIndex
和 mapPartitions 类似, 只是在函数中增加了分区的 Index
@Test
def mapPartitionsWithIndex(): Unit ={
//1.数据生成
//2.数据处理
//3.获取结果
sc.parallelize(Seq(1,2,3,4,5,6),2)
.mapPartitionsWithIndex((index,iter) =>{
println("index: "+index)
iter.foreach(iter => println(iter))
iter
})
.collect()
}

因为他是并行运算,所以index会都出来
sample
Sample 算子可以从一个数据集中抽样出来一部分, 常用作于减小数据集以保证运行速度, 并且尽可能少规律的损失
参数
- Sample 接受第一个参数为`withReplacement`, 意为是否取样以后是否还放回原数据集供下次使用, 简单的说, 如果这个参数的值为 true, 则抽样出来的数据集中可能会有重复
- Sample 接受第二个参数为`fraction`, 意为抽样的比例
- Sample 接受第三个参数为`seed`, 随机数种子, 用于 Sample 内部随机生成下标, 一般不指定, 使用默认值
@Test
def sample(): Unit ={
//1.定义集合
//2.过滤数据
//3.收集结果
val rdd1=sc.parallelize(Seq(1,2,3,4,5,6,7,8,9,10))
//true:会放回,false不会放回
val rdd2=rdd1.sample(true,0.6)
val result=rdd2.collect()
result.foreach(item => println(item))
}
mapValues
MapValues 只能作用于 Key-Value 型数据, 和 Map 类似, 也是使用函数按照转换数据, 不同点是 MapValues 只转换 Key-Value 中的 Value
@Test
def mapValues(): Unit ={
//map作用于整条数据,mapValue作用于Value
sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
.mapValues( item => item*10)
.collect()
.foreach(println(_))
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号