Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建
下载包
所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2.2.0/
Spark 集群高可用搭建
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用
-
使用 Zookeeper 实现 Masters 的主备切换
-
使用文件系统做主备切换
Step 1 停止 Spark 集群
cd /export/servers/spark
sbin/stop-all.shStep 2 修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
-
进入
spark-env.sh所在目录, 打开 vi 编辑cd /export/servers/spark/conf vi spark-env.sh -
编辑
spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址
# 指定 Java Home export JAVA_HOME=/export/servers/jdk1.8.0_141 # 指定 Spark Master 地址 # export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 # 指定 Spark History 运行参数 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" # 指定 Spark 运行时参数 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
Step 3 分发配置文件到整个集群
cd /export/servers/spark/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWDStep 4 启动
-
在
node01上启动整个集群cd /export/servers/spark sbin/start-all.sh sbin/start-history-server.sh -
在
node02上单独再启动一个 Mastercd /export/servers/spark sbin/start-master.sh
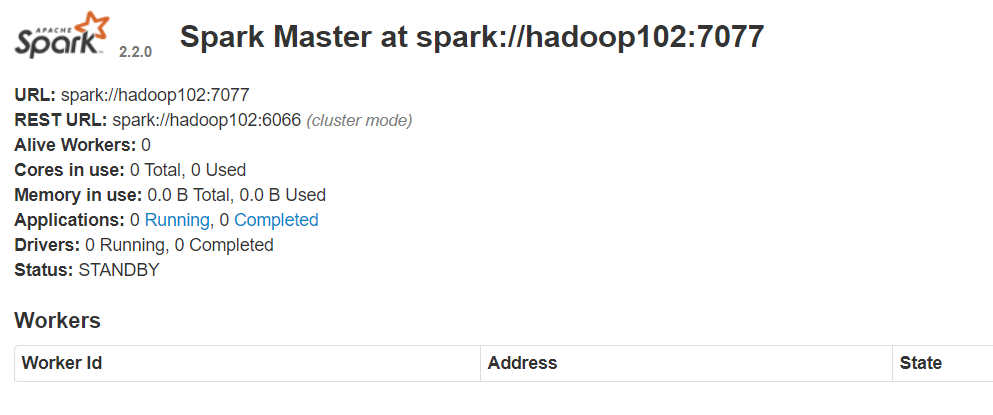
Step 5 查看 node01 master 和 node02 master 的 WebUI
-
你会发现一个是
ALIVE(主), 另外一个是STANDBY(备)

Spark shell
简单介绍
Spark shell 是 Spark 提供的一个基于 Scala 语言的交互式解释器, 类似于 Scala 提供的交互式解释器, Spark shell 也可以直接在 Shell 中编写代码执行
这种方式也比较重要, 因为一般的数据分析任务可能需要探索着进行, 不是一蹴而就的, 使用 Spark shell 先进行探索, 当代码稳定以后, 使用独立应用的方式来提交任务, 这样是一个比较常见的流程
Spark shell 的方式编写 WordCount
|
Spark shell 简介
|
|
Master地址的设置
Master 的地址可以有如下几种设置方式
|
Step 1 准备文件
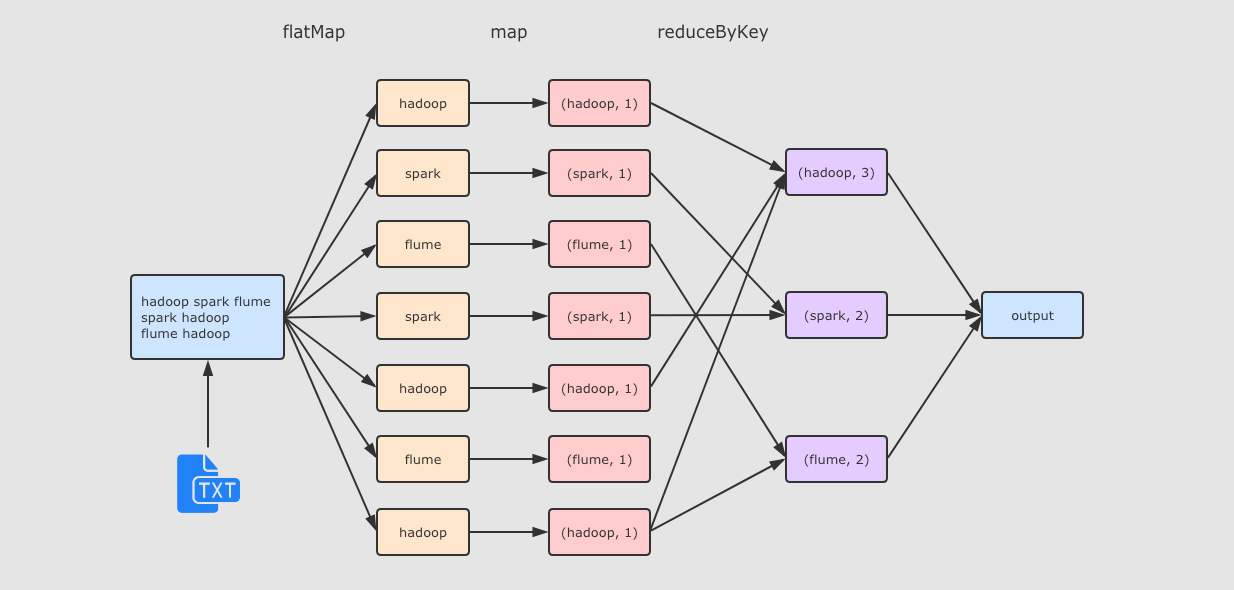
在 hadoop01 中创建文件 /export/data/wordcount.txt,文件内容如下
hadoop spark flume
spark hadoop
flume hadoopStep 2 启动 Spark shell
cd /export/servers/spark
bin/spark-shell --master local[2]Step 3 执行如下代码

运行流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号