
Mysql分库分表
分库分表
当一张表的数据达到几千万时,你查询一次所花的时间会变多。分表的目的就在于此,减小数据库的负担,缩短查询时间。
MySQL垂直分区
把不同业务的数据放到不同的数据库服务器,起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
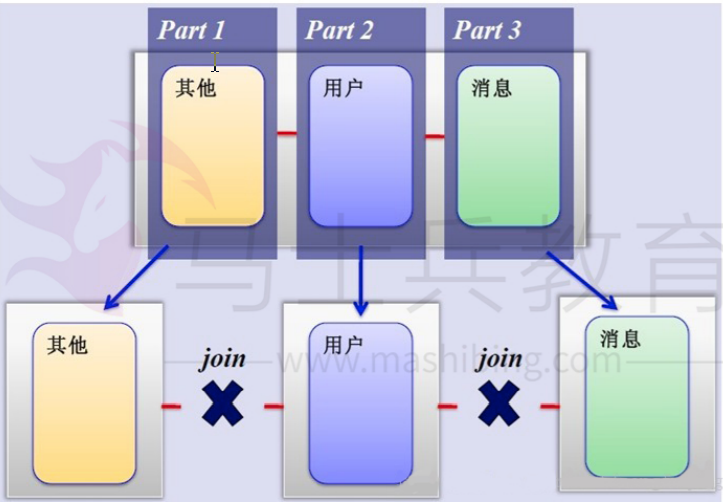
缺点: ①JDBC不支持分布式事物,只有使用JTA实现分布式事物控制;②不能解决单张表数据量暴涨的问题。
MySQL水平分片
将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,原理图如下:
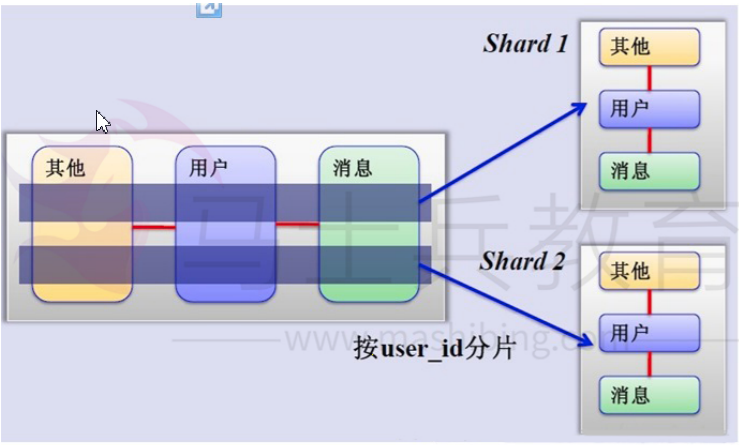
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
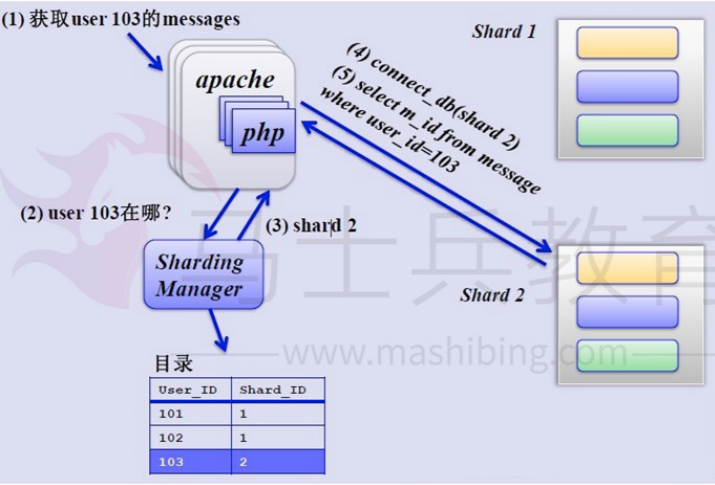
除了水平分片和垂直分区解决数据库数据量大导致查询慢的问题,还有数据库的读写分离也可以在一定程度上提高读写的效率。
XFS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号