

mysql
1、数据库的基本概念
用来保存数据的仓库,在计算机中就是一个文件夹。在硬盘上使用文件来存放数据。
2、什么是数据库管理系统
用来管理数据库的软件系统,mysql,oracle,sql server,postgres
3、数据库结构(cs架构)
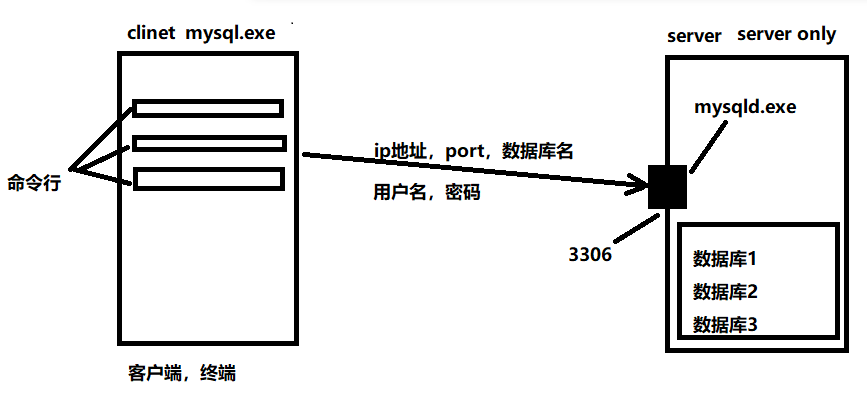
4、查看本地是否安装mysql服务
win+r,输入services.msc
5、操作数据库
1)连接数据库
- 使用客户端连接数据库,如navicat,cx_oracle
- 使用命令好连接数据库

#命令 mysql -uroot -p -h -P #连接本地数据库 mysql -uroot -p #连接本地非默认端口的数据库如3307 mysql -uroot -p -P3307 #连接远程服务器的数据库 mysql -uroot -p -h192.168.0.13 #连接远程服务器上非默认端口的数据库 mysql -uroot -p -h192.168.0.13 -P3307
启动mysql服务后,可能会出现的问题

原因:未配置环境变量
解决方案:
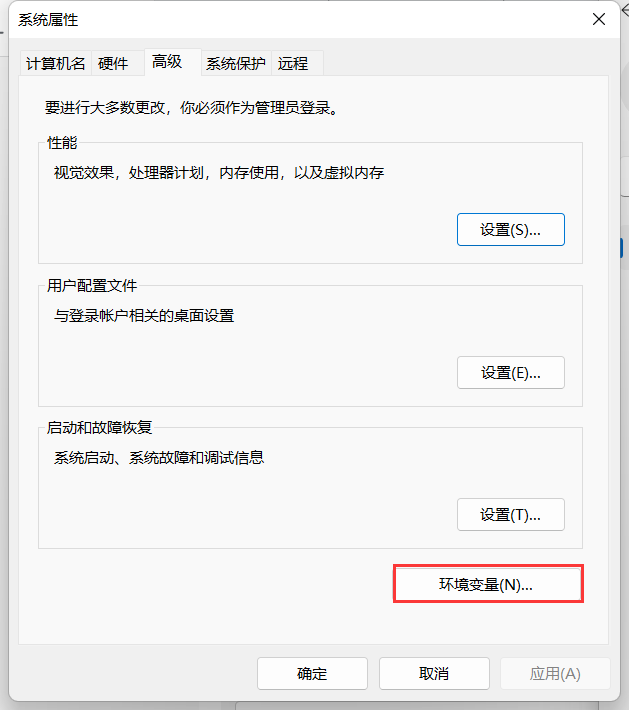
在我的电脑属性中,找到“高级系统设置”;
然后点击“环境变量”
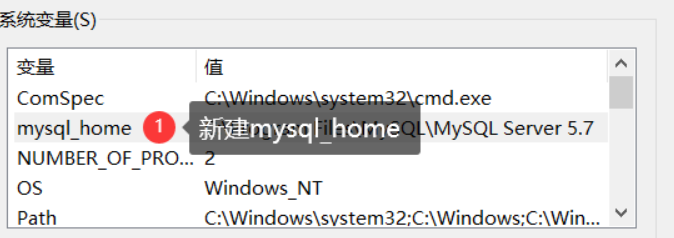
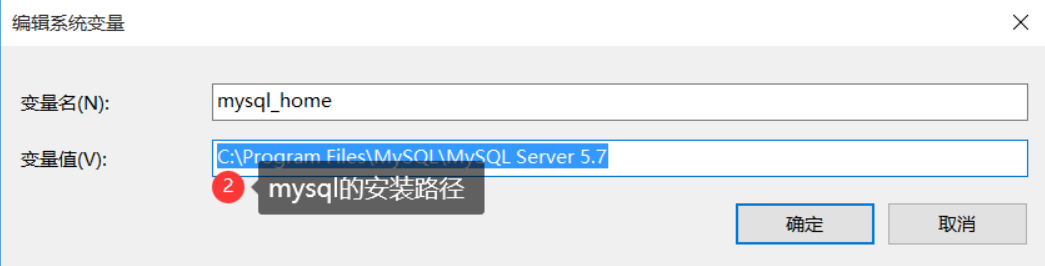
在系统变量中,新建一个mysql_home,路径填写mysql的安装路径
然后再在系统变量中的path下新增一个%mysql_home%\bin
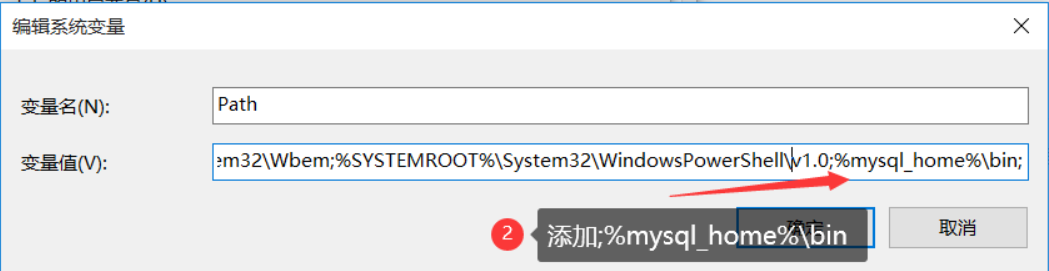
点击确定后,重新打开cmd输入命令
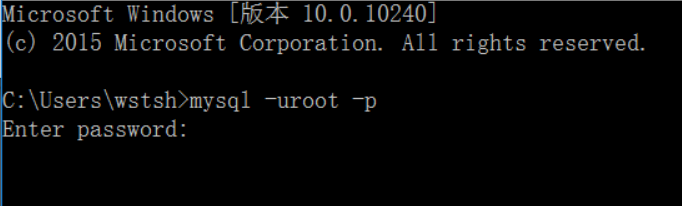
5、DDL:数据定义语言(data definition language):用于创建、修改、删除数据库对象
1)create:创建
a.创建数据库
#语法 create database [if not exists] 数据库名 [character set "utf8"]; #[]表示可选的内容,<>表示必填的内容 #sql语句对大小写不敏感
b.创建表
#语法 create table 表名( 字段名 数据类型 约束, 字段名 数据类型 约束 )[engine=engine_name] character set character_name; #所有的符号都是英文状态的 #engine表示数据库的引擎:innodb(支持事务),mysiam
c.什么是表?
在关系型数据库中用来存放数据的结构,也称为关系。关系包含:行(实体或记录)和列(属性或字段)。
d.数据类型
- 字符串(char,varchar...)
- 浮点数(float,double,decimal...)
#语法 #创建表时,直接在数据类型后面加上primary key #如果要使用多个字段作为主键,在定义表的最后一行使用primary key(字段1,字段2...) #如果表已经创建好了,使用命令alter table 表名 add primary key(字段1,字段2)
h.非空约束
概念:将一个字段定义为not null
作用:非空约束的字段在插入数据的时候不允许插入空值。
#语法 create table 表名( id int primary key, age int not null #将age字段设置为非空约束 )engine=innodb character set "utf8";
非空字段可以使用默认字段来避免插入空值数据时出现异常。
i.默认值约束
概念:给一个字段赋予默认值,当向表中插入数据的时候,如果该字段没有给值,那么mysql就会自动填入默认值。
#语法 create table 表名( id int primary key, age int not null, sex char(2) not null default "男" )engine=innodb character set "utf8";
j.自增长约束
概念:字段的值会自动增加
#语法 create table 表名( id int primary key auto_increment, age int )engine=innodb character set "utf8";
注意:自增长可以和主键一起使用;自增长的字段必须为整数;一个表只能有一个自增长约束。
k.唯一约束
概念:唯一约束可以使字段的值唯一,与同列的其他值区分开来
#语法 create table 表名( id int primary key, name varchar(20) not null, carid varchar(18) unique #身份证的长度必须唯一 )engine=innodb character set "utf8";
l.检查约束
概念:检查某个字段的值,是否是自己设置规定的值,如果不是则抛出异常。
#语法 create table 表名( id int primary key, age int not null, sex set("男","女") default "男" )engine=innodb character set "utf8";
m.外键约束
概念:从表中对应主表主键的列,被称为外键或引用键。
主表中的哪些变化会影响到外键?删除,更新(修改)
约束的方式?
- 禁止主表对主键进行删除或修改:restrict ,no action(innodb)
- 从表的外键跟随主表的主键同步变化:cascade
- 把从表的外键设置为空:set null,如果外键本身有非空约束,这个删除动作就会执行失败。
#语法 #在建表的时候创建外键 foreign key(外键字段名) references 主表名(主键字段名) [on update|delete cascade|no action|restrict|set null]; #表已经建好,再创建外键 alter table 表名 add constrint (外键约束名字) foreign key(外键字段名) references 主表名(主键字段名)[on update|delete cascade|restrict|set null|no action];
#删除外键约束,外键约束名在设计表中可以看到
alter table 表名 drop foreign key 外键约束名;
注意:如果不写on子句,默认为禁止删除restrict
2)alter:修改
a.修改数据库字符集
#语法 alter database 数据库名 character set character_name;
b.修改表
增加主键约束
#语法 alter table 表名 add primary key(字段名);
修改表的非空约束
#语法 alter table 表名 modify 字段名 数据类型 not null;
修改表的默认值约束
#语法 alter table 表名 modify 字段名 数据类型 not null default 默认值;
删除主键
#语法 alter table 表名 drop primary key;
修改表的自增长约束
#语法 alter table 表名 modify 字段名 数据类型 auto_increment;
修改表的检查约束
#语法 alter table 表名 modify 字段名 set("值") ;
修改字段名
#语法 alter table 表名 change 旧字段名 新字段名 数据类型;
3)drop:删除
删除数据库
drop database 数据库名;
6、DML:数据操作语言(data manipulation language):用于对数据表中的数据进行增加、更新(修改)、删除
1)insert :新增
#语法 #一次插入一条数据 insert into 表名([字段名列表]) values(<值列表>); #一次插入多条数据 insert into 表名([字段名列表]) values(<值列表>),(<值列表>),(<值列表>),...;
注意:
- 字段名列表的个数,顺序、数据类型要和值列表要一一对应
- 插入数据的时候要满足约束条件
2)update:更新
作用:更新表中的数据,以字段名为依据
#语法 update 表名 set 字段名=值,字段名=值,...[where子句];
注意:
- 只有一个set
- 多个字段修改,以逗号隔开
- 不加where子句会更新表中所有符合条件【字段名=值】的数据
- 推荐加上where子句。
3)delete:删除
作用:删除表中的数据
#语法 delete from 表名 [where];
注意:
- delete一次删除一行数据;
- delete删除数据后不可恢复;
- delete不加where子句会删除整张表
7、DCL:数据控制语言(data conrol language):用于控制数据库权限、用户管理
数据库权限:数据库操作权限,数据库结构权限,数据库管理权限
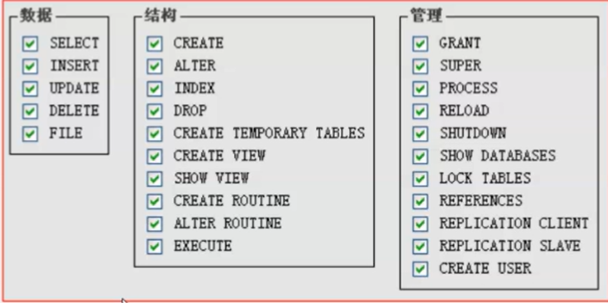
角色:拥有某一类权限的用户的统称。比如超级管理员,root,普通用户,匿名用户(访客)
用户:隶属于某一类角色的实际账号
注意:能够赋权的角色只有root。如果普通用户获得了grant权限,也可以在指定范围内给其他用户赋权。
1)grant:授权
#语法 grount <权限列表> on 数据库名.表名 to 用户名 identified by '密码';
权限列表:select,insert,all...
赋权后需要重新刷新权限或重启数据库服务
#语法 flush privileges;
2)revoke:收回权限
#语法 revoke 权限名1,权限名2... on 数据库.表名 from ‘用户名’@ ’允许其登录的地址;
8、DQL:数据查询语言(data query language):用于筛选数据表中的数据
1)单表查询
#语法 select <字段列表> [distinct] from <数据源> [where 子句] [group by 字段名] [having 条件表达式] [order by 字段名 ASC|DESC] [limit x,y]
a.模糊查询
#语法 字段名 like 表达式; 表达式:'%key_' %:通配符,任意个字符 _:通配符,任一个字符
b.排序:默认为升序
#语法 order by 字段名 desc|asc desc:降序 asc:升序
c.别名:字段或表的别称
#语法 select 字段名 as 别称1,字段名 别称2 from 数据源;
as作为关键字:student as s;
' '空格作为关键字:student s;
d.范围查询
#语法 select * from 表名 where 字段名>=最小值,字段名<=最大值;
e.集合操作
#语法 select * from table where 字段名 in|not in
f.分页查询
#语法 select * from table limit x,y; #x代表开始的位置,表示从那行开始,最小值为0,默认值是0,x可以省略不写 #y表示取的结果,y表示取的数量,y不能省略;
g.去重distinct,一般放在select后面(除先去重再计算的情况)
#先计算,再去重 select distinct * from table #先去重,再计算,需要用到统计函数 select count(distinc 字段名) from table
#查询姓名是张飞的学生信息 select * from student where sname="张飞"; #查询姓名是张飞,性别为男的学生信息 select * from student where sname="张飞" and sex=‘男’; #查询姓名是张飞或者刘备的学生性别 select sex from student where sname='张飞' or sname='刘备'; #查询身份证号以211开头的学生姓名 模糊查询 select sname from student where carid like '211%‘; #查询学生姓名是张某方的全部信息 select * from student where sname like'张_方‘; #查询身份证号包含21的学生信息 select * from student where carid like'%21%'; #查询年龄19岁身份证包含0234的学生信息 select * from student where age=19 and carid like '%0234%'; #查询身份证号包含023或者以5结尾的学生信息 select * from student where carid like '%023%' or carid like '%5'; #排序 #语法1. order by 字段名1 ASC,字段名2 ASC #2. order by DESC,字段名2 DESC #查询所有学生的成绩,降序 select * from score order by score desc; #查询所有学生的成绩,按照成绩降序,学号升序 select * from score order by score desc ,sid asc;#注意多字段排序不能交换位置 #范围查询 #查询成绩在60分到85分之间的学生号和成绩信息 select sid,score from score where score>=60 and score<=85; select sid,score from score where score between 60 and 85; #集合操作in |not in #查询张飞、刘备、赵云的身份证号码 select carid from student where sname in ('张飞','刘备','赵云'); #分页查询limit #查询班上成绩最好的3名同学的学号和科目编号 select sid,cid from student order by score desc limit 3; #去重 #select distinct * from table #先计算再去重 #select count(distinc 字段名) from table;# #先对某个字段去重再统计计算
2)聚合查询
常用的聚合函数
- AVG():返回结果集中所有值的平均值。
- COUNT():返回结果集中行的数目。
- MAX()返回结果集中所有值的最大值。
- MIN():返回结果集中所有值的最小值
- SUM():返回结果集中的所有值的总和。
- round(值,x):x代表保留小数的位数。
- ifnull(值,i):如果字段的值=NULL,则使用I来代替
#语法 #统计学生的平均分 select round(AVG(score),0) from score; #统计学生的最高分、最低分、平均分 select MAX(ifnull(score),0),MIN(score),AVG(score) from score;
3)分组查询
概念:按照某个字段对符合某个条件的结果进行统计
关键字:group by
#语法 select 聚合函数 from 表名 group by 字段名 [having 条件表达式];
#统计班上男女生的人数 select sex,count(sid) from student group by sex; #统计每个学生的平均分 select sid,AVG(score) from score group by sid; #统计平均分超过75的学生学号和成绩 select sid,avg(score) a from score group by sid having a>75;
注意:
- 凡是提到根据某个字段的值去求和、统计数量、求平均值都要考虑分组查询;
- 分组查询后面只能用having而不能用where
- where和having的区别:where只能用在group by的前面;having是对分组后的结果进行筛选,只能用在group by的后面;
4)多表查询
a.子查询
概念:嵌入到其他的sql语句中select语句(可以作用为字段列表,可以用在from后面,也可以用在where后面)
2.作用:
1.当sql语句中需要用到可变的数据来进行条件表达式的运算的时候,需要采用子查询来获取值;
2.需要某些临时数据作为数据源来使用的时候,也需要采用子查询(所有select语句的返回结果都是一个虚拟表)
3.涉及到的关键字:
1.all:取子查询返回结果中的最大值
#all(子查询语句)
#获取子查询返回结果中的最大值
select * from table where degree>all(select degree from table2 where sid=18);
#针对all的运算只有大于或者小于
#如果子查询返回结果为68,70,80,那么主查询结果至少应该为81
2.any
#any(子查询语句),和子查询返回结果中的任意一个值进行比较
#如果子查询返回结果为68,70,80,那么主查询结果至少应该为69
select * from table where degree>any(select degree from table2 where sid=18);
3.in:
#in(子查询),和子查询中任意一个数据进行匹配
select * from table where snum in (select snum from table2 where degree>=60);
#如果子查询返回结果为68,70,80,那么主查询结果
4.exists:
#exists(子查询),判断子查询是否存在结果,如果存在,则返回True,否则返回False
select * from table1 where exists (select snum from table2 where degree>=60 and table1.snum=snum);
注意:in和exists的区别:
1.in的执行顺序
-
首先查询子查询的表;
-
将内表和外表做一个笛卡尔积;
-
使用where条件进行筛选
所以相对而言,内表(子查询的表,例子中的table2)比较小的时候,in的速度较快。
2.exists的执行顺序:
-
查询外表,遍历循环外表(table1);
-
将外表的数据带入到子查询中,判断子查询返回True还是False;
-
如果返回True,则外表循环的数据加入到返回结果集中,否则不能加入
-
最后,将结果集数据返回给用户
所以相对而言,内表table2比较多时,exists查询的速度较快
b.连接查询(关联查询)
概念:多个表通过主外键关联,形成一个新的表进行查询。
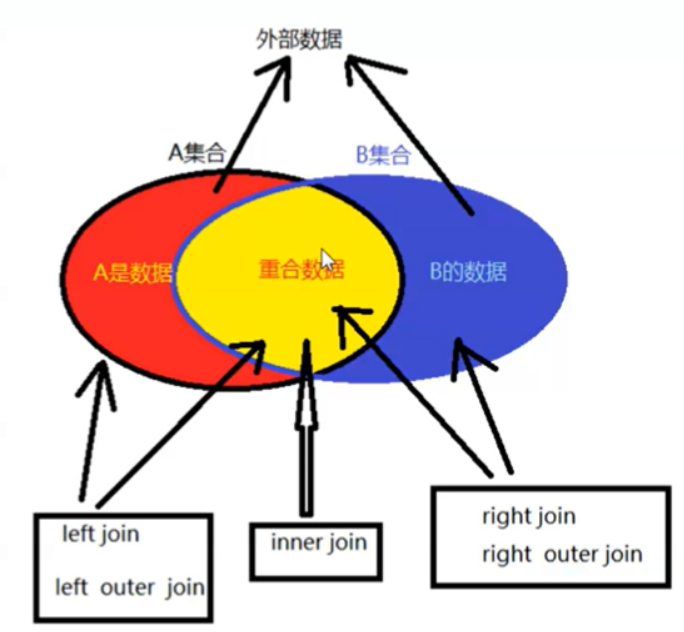
内连接:两张表通过主外键关系一一对应进行连接,也称为:全连接
#语法 #标准格式 #select * from 表名1 inner join 表名2 on 表名1.pk=表名2.fk; #简单版 #select * from 表名1,表名2 where 表名1.pk=表名2.fk; #中配版 #select * from table1 join table2 on table1.pk=table2.fk;
注意事项:
三种连接方式都可以用,但是连接条件必须要有table1.pk = tabel2.fk
外连接:
1.左外连接
#语法 select * from table1 left join table2 on table1.pk=table2.fk;
特点:以左表数据为主,右表匹配上的数据就显示,没有匹配上的数据就显示为NULL
2.右外连接
#语法 #select * from table1 right join table2 on table1.pk=table2.fk;
特点:以右表数据为主,左表匹配上的数据就显示,没有匹配上的数据就显示为NULL
注意事项:1.如何区分左表和右表???
跟join有关,在join左边的就是左表,在join右边的就是右表
2.怎么区分什么时候用内连接,什么时候用外连接??????
1通常使用连接查询的都是内连接;
2需要保留一部分未匹配数据的时候,就需要用到外连接。比如:查询所有学生的成绩
使用连接查询的方法
1.先看需要显示的字段有哪些;
2.再看这些字段在哪些表中,确定哪些表进行关联;
3.如果这些表没有主外键关联,就要考虑使用一个关系表来连接这两张表;
4.先连表,再筛选
c.组合查询
9、三大范式
范式:NF(normal format),关系型数据库中使用的标准格式。
目前有6大范式:第一范式,第二范式,第三范式...
范式的作用:
第一范式:保证表中字段原子性,字段不可再分;
第二范式:表中的每行必须唯一(必须建立主键),非主键必须完全依赖于主键;
第三范式:每列和主键都必须直接相关,而不是间接相关
10.存储过程
2.结构语句
1.分支结构
1.if ...then...else if...then...else...end;
2.case语句
开关语句
delimiter //
drop procedure if exists day;
create procedure if not exists day(in work_day varchar(5),out msg varchar(10))
begin
case work_day
when '周六' then
set msg='休息日';
when '周日' then
set msg='休息日';
when '' then
set msg='对不起,您的输入有误';
else
set msg='工作日';
end case;
end //
delimiter ;
2.循环结构 while和repeat
1.while语法
#while
[label:] while 条件表达式 do
语句块;
end while[label:]
label:标签,用于标识循环的入口,如果需要中途跳出循环,就必然会用到这个标记
#需求:用户输入一个整数作为上限,程序返回从1加到该整数的结果
delimiter &&
drop procedure if exists for_add;
create procedure if not exists for_add(in input_num int,out result int)
begin
#初始化result
declare i int default 0;#定义一个累加变量,默认为0
set @result =0;
if input_num >1 then
while i <=input_num do
set result=result+i;#求和
set i=i+1 ;#累加
end while
else if input_num=1 then
set result=1;
else
set result = "您的输入有误!";
end &&
delimiter;
set @input_num=10;
call for_add(@input_num,@result);
select @result;
#
#需求:用户输入一个整数,程序返回该整数的阶乘
delimiter &&
drop procedure if exists mul;
create procedure if not exists mul(in num int,out mul_num int)
begin
#定义一个累乘变量x
declare x int default 1;
#初始化mul_num=1
set @mul_num=1;
while x<=num do
set mul_num=mul_num*x;
set x=x+1;
end while
end &&
delimiter;
set @num =10;
call mul(@num,@mul_num);
select @mul_num;
2.repeat循环
#语法
[label:]repeat
语句块;
until 条件表达式
end repeat label;
和while循环的区别是,满足的条件相反
#需求:用户输入一个整数,程序返回该整数的阶乘
delimiter &&
drop procedure if exists mul;
create procedure if not exists mul(in num int,out mul_num int)
begin
#定义一个累乘变量x
declare x int default 1;
#初始化mul_num=1
set @mul_num=1;
repeat
set mul_num=mul_num*x;
set x=x+1;
until x>num
end repeat label;
end &&
delimiter;
set @num =10;
call mul(@num,@mul_num);
select @mul_num;
3.跳出循环
1.关键字
1.iterate 迭代:重新开始执行循环语句,类似python的continue
2.leave 跳出循环,类似python的break
2.函数
1.概念:一段SQL用于实现一个独立功能的代码,具有返回数据结果的能力。
2.语法:
#函数
create function 函数名([参数列表]) return 返回类型
begin
语句块;
return 结果;
end
#调用方式
#1.直接调用
data_sub(x,y)
#2.赋值给变量
set @rlt=date_sub(x,y)
3.函数和存储过程的区别
3.事务
1.定义:
一个具有明确开始,结束标记的,并且有序的一段执行过程。
2.作用:
主要解决多个操作作为一个整体向系统提交时,要么执行,要么都不执行,事务是一个不可分割的逻辑单元。
3.事务具有以下特性:
1.原子性:事务执行的步骤是不可或缺的;
2.一致性:事务执行结果,这个变化在执行前和执行后是一致的;
3.隔离性:事务和事务之间是相互隔离的,互不影响;
4.持久性:事务执行的结果,其效果是持久的。怎么操作才会让数据持久保持?就是把数据写到硬盘上。
4.事务控制语句
1.begin /start transaction:显式的开启一个事务。
2.commit:也可以使用commit work,不过二者是等价的。commit会提交事务,并使已对数据库进行的所有修改称为永久性的。
3.rollback:也可以使用rollback work,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
4.savepoint identifier :savepoint允许在事务中创建一个保存点,一个事务可以有多个savepoint。
5.release savepoint identifier:删除一个事务保存点,当没有指定的保存点时,执行语句会抛出一个异常。
6.rollback to identifier:把事务回滚到标记点。
7.set transaction:用来设置事务的隔离级别。innodb存储引擎提供事务的隔离级别有read uncommitted、read committedrepeatable read和serializable
5.事务的两种处理方式
6.概念
1.存盘点:savepoint 名称;
2.回滚:rollback 恢复以前执行过的操作,比如:原来删除了一行数据,现在就把数据恢复回来。发生在事务提交失败之后;
3.回滚到存盘点:rollback to 名称;主要针对某些执行时间较长的步骤;
4.提交:commit 把事务执行的结果持久化。
4.视图
1.概念:视图可以看作定义在mysql的虚拟表,视图正如其名字的含义 一样,是另一种查看数据的入口。常规的视图并不存储数据,只是存储一个select语句和所涉及表的metadata。
2.与视图相关的命令
#创建视图
create view 视图名 as select 字段名列表 from 表名;
#删除视图
drop view 视图名;
#查询视图,当成普通的数据表来操作
select * from 视图名;
3.视图的作用
1.保护数据,将敏感数据隐藏起来。
2.数据安全,对外使用视图,即使字段名泄露,也不影响到真实数据表。
3.提高查询效率,某些统计数据需要耗时比较久,就把统计好的数据生成一个视图,提供给用户查询,避免每次查询统计。
5.索引
1.概念
索引的本质就是通过特定的算法,将数据进行排序处理,进而能够更加快速的找到对应的数据。
2.作用
提高数据查询的效率
3.分类
MySQL索引主要有两种结构:B+Tree索引和Hash索引。
4.常见的索引类型
1.primary key(主键索引):alter table 表名 add primary key(列名)
2.unique(唯一索引):alter table 表名 add unique(列名)
3.index(普通索引):alter table 表名 add index index_name(列名)
4.fulltext(全文索引):alter table 表名 add fulltext(列名)
5.组合索引 :alter table 表名 add index index_name(列1,列2....)
6.触发器
1.概念
是与 表事件相关的特殊的存储过程。
2.机制
不是手工启动的,由事件来触发,如:对数据表进行操作(insert 、delete、update)
3.创建触发器
create trigger 触发器名 触发时机 on 表名 for each row
begin
语句块;
end
解释:
触发器名:和存储过程的名称命名规范一样
触发时机:before、after
触发事件:insert、update、delete
构成6种触发器:before insert、before update、before delete、after insert、after update、after delete
4.触发器特有的关键字
1.new:代表新的数据记录;
2.old:代表数据表中原来的数据记录
-
insert事件具有new记录,没有old记录
-
update事件具有new和old记录(更新之前的那条记录)
-
delete事件具有old记录(被删除的那条记录)
3.new和old的本质一行记录,一个实体。可以通过new字段名 来获取记录中对应的字段的值
#需求:在新增学生数据的时候,要求年龄不能大于20岁,不能小于17岁
drop trigger age_add;
create trigger age_add before insert on student for each row
begin
if new.sage<=20 and new.sage>=17 then
insert into student(sno,sname,ssex,sbirthday,class,sage) values(new.sno,new.sname,new.ssex,new.sbirthday,new.class,new.sage);
else
new='';
end if;
end


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通