
awk中的"匹配"与"不匹配"
~ 匹配正则
!~ 不匹配正则
== 等于
!= 不等于
提取文件后四行
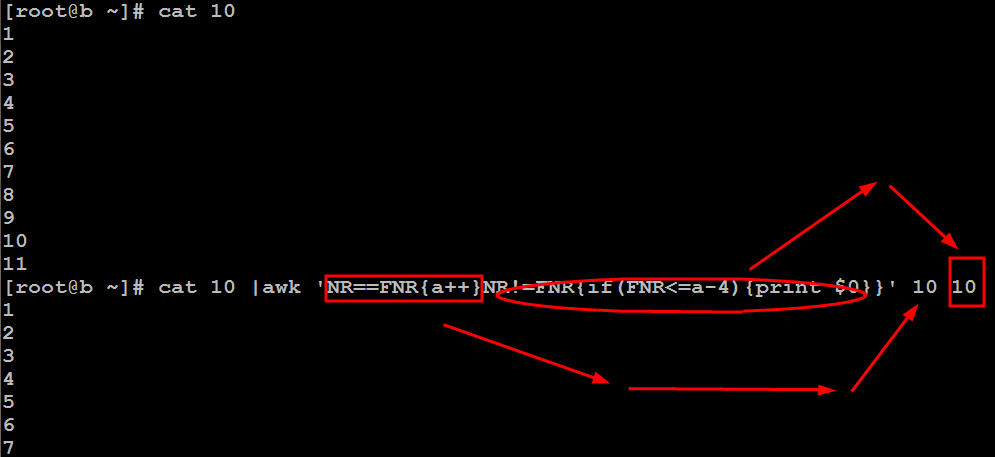
注释:NR==FNR表示第一个文件,执行{a++},计算出第一个文件10的行数,NR!=FNR表示第二个文件10,执行{if(FNR<=a-4){print $0}},打印出第二个文件的前6行。重点为计算出文件的行数。
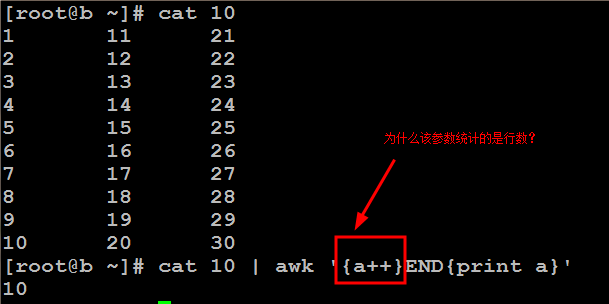
只查看文件前27行
[root@x112 linshi]# cat /etc/passwd | head -n -27
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@x112 linshi]#
[root@x112 linshi]# awk -F: 'NR==FNR{a++}NR!=FNR{if(FNR<a-27){print $0}}' /etc/passwd /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@x112 linshi]#
NR==FNR代表处理的是第一个文件,NR!=FNR代表处理的是第二个文件,二个文件可以是同一个文件。
LINUX-AWK-删除首行、删除尾行、删除首尾两行
删除原理如下:
利用awk按行遍历,依次执行body的特点, 如下面命令
awk 'NR>1 {print line} {line=$0}' 作用是去掉最后一行。
首轮先输出line(此时为空值,打印空行,所以用 NR>1 跳过此输出),再把首行赋值给line变量,
然后在第二轮输出了line(此时为第一行内容),循环到最后一行时,输出为倒数第二行内容。
最后把最后一行赋值给line,但循环已完,所以最后一行不会输出,即去掉最后一行。
按上面原理
如果想去掉首行,就设置 NR>2
如果想保留最后一行,可以在END输出line即可
删除首行
[root@x112 linshi]# awk 'NR>2{print line}{line=$0}END{print line}' a.txt
TEST.2 02
TEST.3 03
TEST.4 04
TEST.5 05
TEST.6 06
TEST.7 07
TEST.8 08
TEST.9 09
TEST.10 10
删除尾行
[root@x112 linshi]# awk 'NR>1{print line}{line=$0}' a.txt
TEST.1 01
TEST.2 02
TEST.3 03
TEST.4 04
TEST.5 05
TEST.6 06
TEST.7 07
TEST.8 08
TEST.9 09
删除首尾2行
[root@x112 linshi]# awk 'NR>2{print line}{line=$0}' a.txt
TEST.2 02
TEST.3 03
TEST.4 04
TEST.5 05
TEST.6 06
TEST.7 07
TEST.8 08
TEST.9 09
为者常成,行者常至
Give me five~!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号