前端一面react面试题指南
React 事件机制
<div onClick={this.handleClick.bind(this)}>点我</div>
React并不是将click事件绑定到了div的真实DOM上,而是在document处监听了所有的事件,当事件发生并且冒泡到document处的时候,React将事件内容封装并交由真正的处理函数运行。这样的方式不仅仅减少了内存的消耗,还能在组件挂在销毁时统一订阅和移除事件。
除此之外,冒泡到document上的事件也不是原生的浏览器事件,而是由react自己实现的合成事件(SyntheticEvent)。因此如果不想要是事件冒泡的话应该调用event.preventDefault()方法,而不是调用event.stopProppagation()方法。 JSX 上写的事件并没有绑定在对应的真实 DOM 上,而是通过事件代理的方式,将所有的事件都统一绑定在了 document 上。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。
另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件(SyntheticEvent)。因此我们如果不想要事件冒泡的话,调用 event.stopPropagation 是无效的,而应该调用 event.preventDefault。
实现合成事件的目的如下:
- 合成事件首先抹平了浏览器之间的兼容问题,另外这是一个跨浏览器原生事件包装器,赋予了跨浏览器开发的能力;
- 对于原生浏览器事件来说,浏览器会给监听器创建一个事件对象。如果你有很多的事件监听,那么就需要分配很多的事件对象,造成高额的内存分配问题。但是对于合成事件来说,有一个事件池专门来管理它们的创建和销毁,当事件需要被使用时,就会从池子中复用对象,事件回调结束后,就会销毁事件对象上的属性,从而便于下次复用事件对象。
connect原理
- 首先
connect之所以会成功,是因为Provider组件: - 在原应用组件上包裹一层,使原来整个应用成为
Provider的子组件 接收Redux的store作为props,通过context对象传递给子孙组件上的connect
connect做了些什么。它真正连接Redux和React,它包在我们的容器组件的外一层,它接收上面Provider提供的store里面的state和dispatch,传给一个构造函数,返回一个对象,以属性形式传给我们的容器组件
connect是一个高阶函数,首先传入mapStateToProps、mapDispatchToProps,然后返回一个生产Component的函数(wrapWithConnect),然后再将真正的Component作为参数传入wrapWithConnect,这样就生产出一个经过包裹的Connect组件,
该组件具有如下特点
- 通过
props.store获取祖先Component的store props包括stateProps、dispatchProps、parentProps,合并在一起得到nextState,作为props传给真正的Component componentDidMount时,添加事件this.store.subscribe(this.handleChange),实现页面交互 shouldComponentUpdate时判断是否有避免进行渲染,提升页面性能,并得到nextStatecomponentWillUnmount时移除注册的事件this.handleChange
由于
connect的源码过长,我们只看主要逻辑
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}) {
return function wrapWithConnect(WrappedComponent) {
class Connect extends Component {
constructor(props, context) {
// 从祖先Component处获得store
this.store = props.store || context.store
this.stateProps = computeStateProps(this.store, props)
this.dispatchProps = computeDispatchProps(this.store, props)
this.state = { storeState: null }
// 对stateProps、dispatchProps、parentProps进行合并
this.updateState()
}
shouldComponentUpdate(nextProps, nextState) {
// 进行判断,当数据发生改变时,Component重新渲染
if (propsChanged || mapStateProducedChange || dispatchPropsChanged) {
this.updateState(nextProps)
return true
}
}
componentDidMount() {
// 改变Component的state
this.store.subscribe(() = {
this.setState({
storeState: this.store.getState()
})
})
}
render() {
// 生成包裹组件Connect
return (
<WrappedComponent {...this.nextState} />
)
}
}
Connect.contextTypes = {
store: storeShape
}
return Connect;
}
}
在哪个生命周期中你会发出Ajax请求?为什么?
Ajax请求应该写在组件创建期的第五个阶段,即 componentDidMount生命周期方法中。原因如下。
在创建期的其他阶段,组件尚未渲染完成。而在存在期的5个阶段,又不能确保生命周期方法一定会执行(如通过 shouldComponentUpdate方法优化更新等)。在销毀期,组件即将被销毁,请求数据变得无意义。因此在这些阶段发岀Ajax请求显然不是最好的选择。
在组件尚未挂载之前,Ajax请求将无法执行完毕,如果此时发出请求,将意味着在组件挂载之前更新状态(如执行 setState),这通常是不起作用的。
在 componentDidMount方法中,执行Ajax即可保证组件已经挂载,并且能够正常更新组件。
调用 setState 之后发生了什么
在代码中调用 setState 函数之后,React 会将传入的参数与之前的状态进行合并,然后触发所谓的调和过程(Reconciliation)。经过调和过程,React 会以相对高效的方式根据新的状态构建 React 元素树并且着手重新渲染整个 UI 界面。在 React 得到元素树之后,React 会计算出新的树和老的树之间的差异,然后根据差异对界面进行最小化重新渲染。通过 diff 算法,React 能够精确制导哪些位置发生了改变以及应该如何改变,这就保证了按需更新,而不是全部重新渲染。
- 在 setState 的时候,React 会为当前节点创建一个 updateQueue 的更新列队。
- 然后会触发 reconciliation 过程,在这个过程中,会使用名为 Fiber 的调度算法,开始生成新的 Fiber 树, Fiber 算法的最大特点是可以做到异步可中断的执行。
- 然后 React Scheduler 会根据优先级高低,先执行优先级高的节点,具体是执行 doWork 方法。
- 在 doWork 方法中,React 会执行一遍 updateQueue 中的方法,以获得新的节点。然后对比新旧节点,为老节点打上 更新、插入、替换 等 Tag。
- 当前节点 doWork 完成后,会执行 performUnitOfWork 方法获得新节点,然后再重复上面的过程。
- 当所有节点都 doWork 完成后,会触发 commitRoot 方法,React 进入 commit 阶段。
- 在 commit 阶段中,React 会根据前面为各个节点打的 Tag,一次性更新整个 dom 元素
讲讲什么是 JSX ?
当 Facebook 第一次发布 React 时,他们还引入了一种新的 JS 方言 JSX,将原始 HTML 模板嵌入到 JS 代码中。JSX 代码本身不能被浏览器读取,必须使用Babel和webpack等工具将其转换为传统的JS。很多开发人员就能无意识使用 JSX,因为它已经与 React 结合在一直了。
class MyComponent extends React.Component {
render() {
let props = this.props;
return (
<div className="my-component">
<a href={props.url}>{props.name}</a>
</div>
);
}
}
React怎么做数据的检查和变化
Model改变之后(可能是调用了setState),触发了virtual dom的更新,再用diff算法来把virtual DOM比较real DOM,看看是哪个dom节点更新了,再渲染real dom
参考 前端进阶面试题详细解答
在 ReactNative中,如何解决 adb devices找不到连接设备的问题?
在使用 Genymotion时,首先需要在SDK的 platform-tools中加入环境变量,然后在 Genymotion中单击 Setting,选择ADB选项卡,单击 Use custom Android SDK tools,浏览本地SDK的位置,单击OK按钮就可以了。启动虛拟机后,在cmd中输入 adb devices可以查看设备。
react diff 算法
我们知道React会维护两个虚拟DOM,那么是如何来比较,如何来判断,做出最优的解呢?这就用到了diff算法
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将
O(n^3)杂度 转化为O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计
- 同级比较,既然DOM 节点跨层级的移动操作少到可以忽略不计,那么React通过updateDepth 对 Virtual DOM 树进行层级控制,也就是同一层,在对比的过程中,如果发现节点不在了,会完全删除不会对其他地方进行比较,这样只需要对树遍历一次就OK了
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
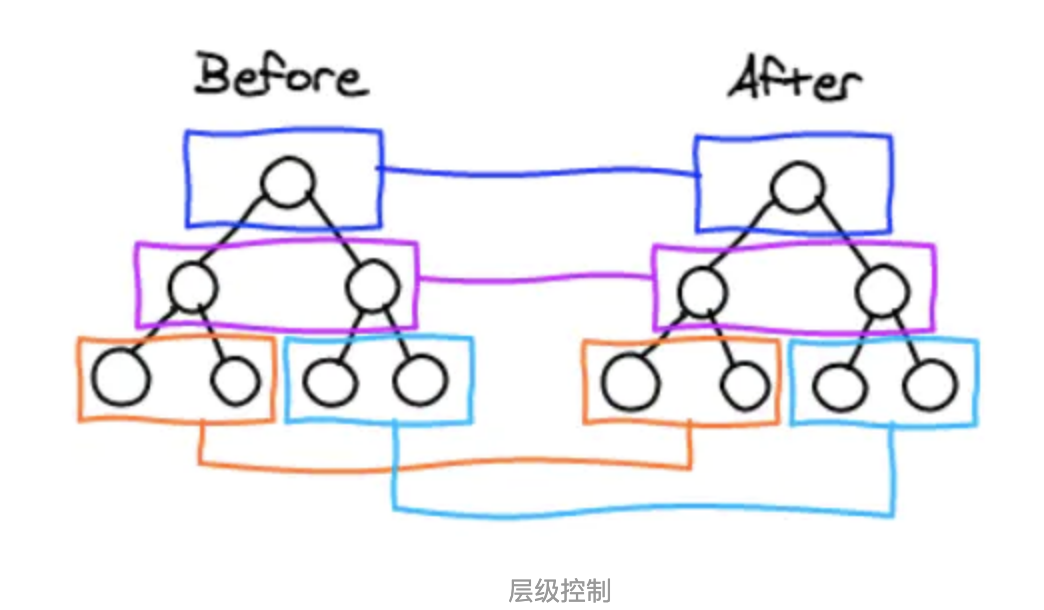
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
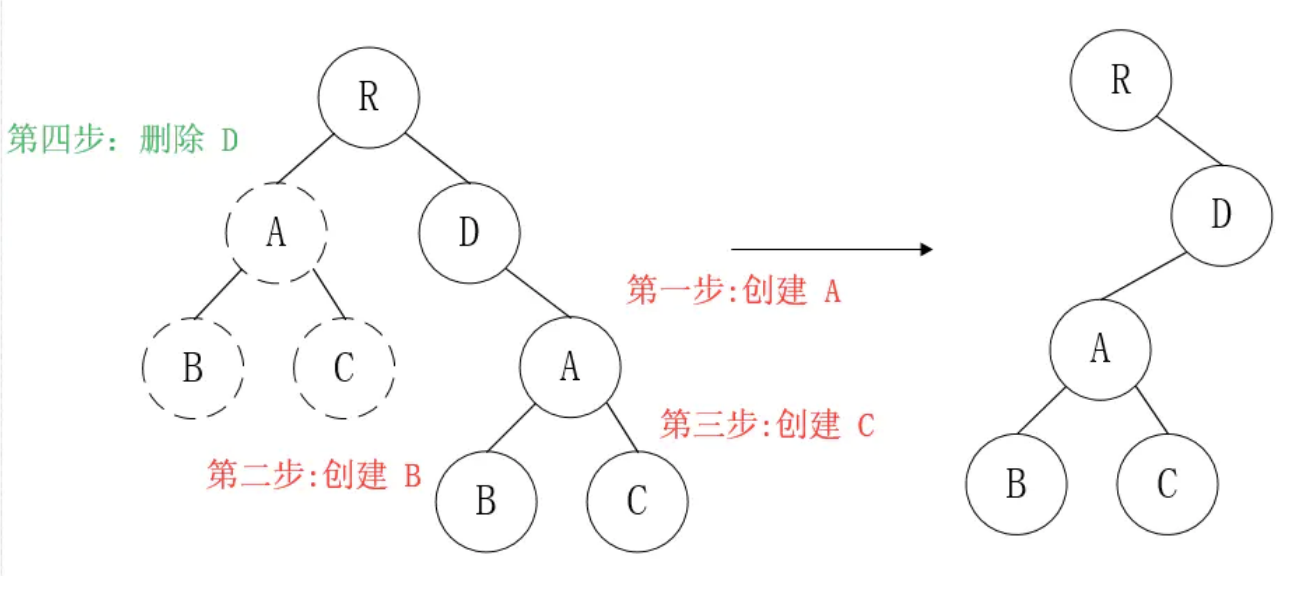
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
element diff
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
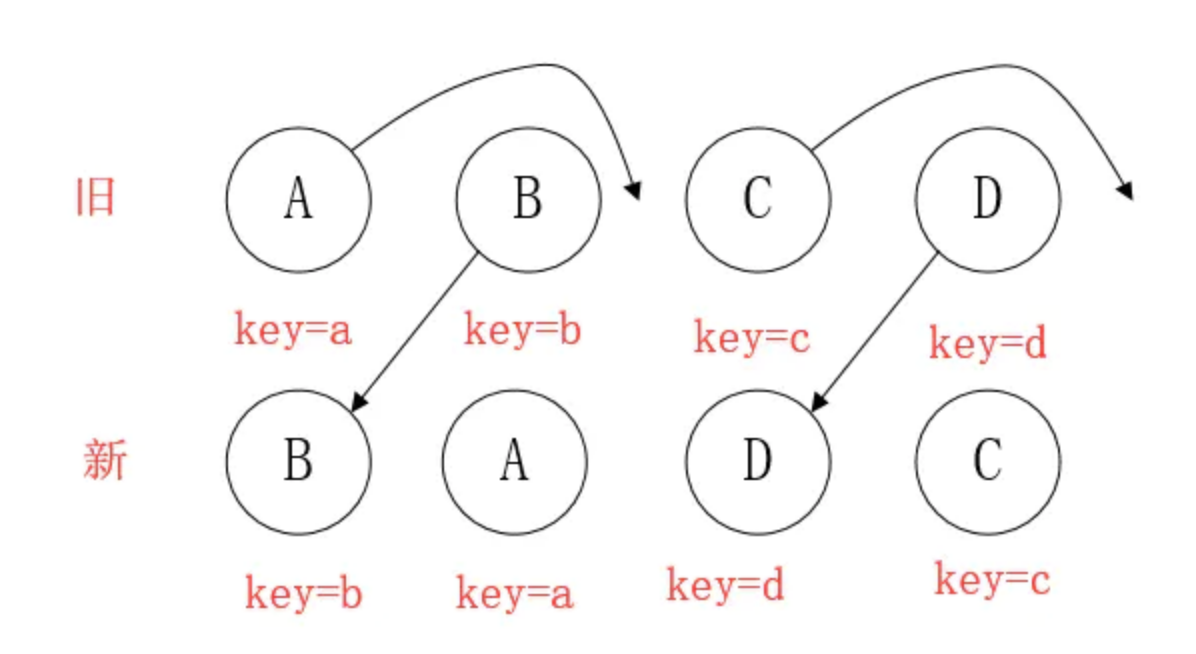
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即可。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
在使用 React Router时,如何获取当前页面的路由或浏览器中地址栏中的地址?
在当前组件的 props中,包含 location属性对象,包含当前页面路由地址信息,在 match中存储当前路由的参数等数据信息。可以直接通过 this .props使用它们。
diff算法?
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
setState 是同步的还是异步的
有时表现出同步,有时表现出异步
- setState 只有在 React 自身的合成事件和钩子函数中是异步的,在原生事件和 setTimeout 中都是同步的
- setState 的异步并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的异步。当然可以通过 setState 的第二个参数中的 callback 拿到更新后的结果
- setState 的批量更新优化也是建立在异步(合成事件、钩子函数)之上的,在原生事件和 setTimeout 中不会批量更新,在异步中如果对同一个值进行多次 setState,setState 的批量更新策略会对其进行覆盖,去最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新
- 合成事件中是异步
- 钩子函数中的是异步
- 原生事件中是同步
- setTimeout中是同步
React 中 keys 的作用是什么?
Keys是React用于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识
- 在开发过程中,我们需要保证某个元素的
key在其同级元素中具有唯一性。在React Diff算法中React会借助元素的Key值来判断该元素是新近创建的还是被移动而来的元素,从而减少不必要的元素重渲染。此外,React 还需要借助Key值来判断元素与本地状态的关联关系,因此我们绝不可忽视转换函数中Key的重要性
setState到底是异步还是同步?
先给出答案: 有时表现出异步,有时表现出同步
setState只在合成事件和钩子函数中是“异步”的,在原生事件和setTimeout中都是同步的setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的“异步”,当然可以通过第二个参数setState(partialState, callback)中的callback拿到更新后的结果setState的批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout中不会批量更新,在“异步”中如果对同一个值进行多次setState,setState的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时setState多个不同的值,在更新时会对其进行合并批量更新
react性能优化方案
- 重写
shouldComponentUpdate来避免不必要的dom操作 - 使用
production版本的react.js - 使用
key来帮助React识别列表中所有子组件的最小变化
diff 算法?
- 把树形结构按照层级分解,只比较同级元素
- 给列表结构的每个单元添加唯一的 key 属性,方便比较
- React 只会匹配相同 class 的 component(这里面的 class 指的是组件的名字)
- 合并操作,调用 component 的 setState 方法的时候, React 将其标记为 dirty.到每一个 事件循环结束, React 检查所有标记 dirty 的 component 重新绘制.
- 选择性子树渲染。开发人员可以重写 shouldComponentUpdate 提高 diff 的性能。
react性能优化是哪个周期函数
shouldComponentUpdate这个方法用来判断是否需要调用render方法重新描绘dom。因为dom的描绘非常消耗性能,如果我们能在shouldComponentUpdate方法中能够写出更优化的dom diff算法,可以极大的提高性能
Diff 的瓶颈以及 React 的应对
由于 diff 操作本身会带来性能上的损耗,在 React 文档中提到过,即使最先进的算法中,将前后两棵树完全比对的算法复杂度为O(n3),其中 n 为树中元素的数量。
如果 React 使用了该算法,那么仅仅一千个元素的页面所需要执行的计算量就是十亿的量级,这无疑是无法接受的。
为了降低算法的复杂度,React 的 diff 会预设三个限制:
- 只对同级元素进行 diff 比对。如果一个元素节点在前后两次更新中跨越了层级,那么 React 不会尝试复用它
- 两个不同类型的元素会产生出不同的树。如果元素由 div 变成 p,React 会销毁 div 及其子孙节点,并新建 p 及其子孙节点
- 开发者可以通过 key 来暗示哪些子元素在不同的渲染下能保持稳定
React的生命周期有哪些?
React 通常将组件生命周期分为三个阶段:
- 装载阶段(Mount),组件第一次在DOM树中被渲染的过程;
- 更新过程(Update),组件状态发生变化,重新更新渲染的过程;
- 卸载过程(Unmount),组件从DOM树中被移除的过程;
1)组件挂载阶段
挂载阶段组件被创建,然后组件实例插入到 DOM 中,完成组件的第一次渲染,该过程只会发生一次,在此阶段会依次调用以下这些方法:
- constructor
- getDerivedStateFromProps
- render
- componentDidMount
(1)constructor
组件的构造函数,第一个被执行,若没有显式定义它,会有一个默认的构造函数,但是若显式定义了构造函数,我们必须在构造函数中执行 super(props),否则无法在构造函数中拿到this。
如果不初始化 state 或不进行方法绑定,则不需要为 React 组件实现构造函数Constructor。
constructor中通常只做两件事:
- 初始化组件的 state
- 给事件处理方法绑定 this
constructor(props) {
super(props);
// 不要在构造函数中调用 setState,可以直接给 state 设置初始值
this.state = { counter: 0 }
this.handleClick = this.handleClick.bind(this)
}
(2)getDerivedStateFromProps
static getDerivedStateFromProps(props, state)
这是个静态方法,所以不能在这个函数里使用 this,有两个参数 props 和 state,分别指接收到的新参数和当前组件的 state 对象,这个函数会返回一个对象用来更新当前的 state 对象,如果不需要更新可以返回 null。
该函数会在装载时,接收到新的 props 或者调用了 setState 和 forceUpdate 时被调用。如当接收到新的属性想修改 state ,就可以使用。
// 当 props.counter 变化时,赋值给 state
class App extends React.Component {
constructor(props) {
super(props)
this.state = {
counter: 0
}
}
static getDerivedStateFromProps(props, state) {
if (props.counter !== state.counter) {
return {
counter: props.counter
}
}
return null
}
handleClick = () => {
this.setState({
counter: this.state.counter + 1
})
}
render() {
return (
<div>
<h1 onClick={this.handleClick}>Hello, world!{this.state.counter}</h1>
</div>
)
}
}
现在可以显式传入 counter ,但是这里有个问题,如果想要通过点击实现 state.counter 的增加,但这时会发现值不会发生任何变化,一直保持 props 传进来的值。这是由于在 React 16.4^ 的版本中 setState 和 forceUpdate 也会触发这个生命周期,所以当组件内部 state 变化后,就会重新走这个方法,同时会把 state 值赋值为 props 的值。因此需要多加一个字段来记录之前的 props 值,这样就会解决上述问题。具体如下:
// 这里只列出需要变化的地方
class App extends React.Component {
constructor(props) {
super(props)
this.state = {
// 增加一个 preCounter 来记录之前的 props 传来的值
preCounter: 0,
counter: 0
}
}
static getDerivedStateFromProps(props, state) {
// 跟 state.preCounter 进行比较
if (props.counter !== state.preCounter) {
return {
counter: props.counter,
preCounter: props.counter
}
}
return null
}
handleClick = () => {
this.setState({
counter: this.state.counter + 1
})
}
render() {
return (
<div>
<h1 onClick={this.handleClick}>Hello, world!{this.state.counter}</h1>
</div>
)
}
}
(3)render
render是React 中最核心的方法,一个组件中必须要有这个方法,它会根据状态 state 和属性 props 渲染组件。这个函数只做一件事,就是返回需要渲染的内容,所以不要在这个函数内做其他业务逻辑,通常调用该方法会返回以下类型中一个:
- React 元素:这里包括原生的 DOM 以及 React 组件;
- 数组和 Fragment(片段):可以返回多个元素;
- Portals(插槽):可以将子元素渲染到不同的 DOM 子树种;
- 字符串和数字:被渲染成 DOM 中的 text 节点;
- 布尔值或 null:不渲染任何内容。
(4)componentDidMount()
componentDidMount()会在组件挂载后(插入 DOM 树中)立即调。该阶段通常进行以下操作:
- 执行依赖于DOM的操作;
- 发送网络请求;(官方建议)
- 添加订阅消息(会在componentWillUnmount取消订阅);
如果在 componentDidMount 中调用 setState ,就会触发一次额外的渲染,多调用了一次 render 函数,由于它是在浏览器刷新屏幕前执行的,所以用户对此是没有感知的,但是我应当避免这样使用,这样会带来一定的性能问题,尽量是在 constructor 中初始化 state 对象。
在组件装载之后,将计数数字变为1:
class App extends React.Component {
constructor(props) {
super(props)
this.state = {
counter: 0
}
}
componentDidMount () {
this.setState({
counter: 1
})
}
render () {
return (
<div className="counter">
counter值: { this.state.counter } </div>
)
}
}
2)组件更新阶段
当组件的 props 改变了,或组件内部调用了 setState/forceUpdate,会触发更新重新渲染,这个过程可能会发生多次。这个阶段会依次调用下面这些方法:
- getDerivedStateFromProps
- shouldComponentUpdate
- render
- getSnapshotBeforeUpdate
- componentDidUpdate
(1)shouldComponentUpdate
shouldComponentUpdate(nextProps, nextState)
在说这个生命周期函数之前,来看两个问题:
- setState 函数在任何情况下都会导致组件重新渲染吗?例如下面这种情况:
this.setState({number: this.state.number})
- 如果没有调用 setState,props 值也没有变化,是不是组件就不会重新渲染?
第一个问题答案是 会 ,第二个问题如果是父组件重新渲染时,不管传入的 props 有没有变化,都会引起子组件的重新渲染。
那么有没有什么方法解决在这两个场景下不让组件重新渲染进而提升性能呢?这个时候 shouldComponentUpdate 登场了,这个生命周期函数是用来提升速度的,它是在重新渲染组件开始前触发的,默认返回 true,可以比较 this.props 和 nextProps ,this.state 和 nextState 值是否变化,来确认返回 true 或者 false。当返回 false 时,组件的更新过程停止,后续的 render、componentDidUpdate 也不会被调用。
注意: 添加 shouldComponentUpdate 方法时,不建议使用深度相等检查(如使用 JSON.stringify()),因为深比较效率很低,可能会比重新渲染组件效率还低。而且该方法维护比较困难,建议使用该方法会产生明显的性能提升时使用。
(2)getSnapshotBeforeUpdate
getSnapshotBeforeUpdate(prevProps, prevState)
这个方法在 render 之后,componentDidUpdate 之前调用,有两个参数 prevProps 和 prevState,表示更新之前的 props 和 state,这个函数必须要和 componentDidUpdate 一起使用,并且要有一个返回值,默认是 null,这个返回值作为第三个参数传给 componentDidUpdate。
(3)componentDidUpdate
componentDidUpdate() 会在更新后会被立即调用,首次渲染不会执行此方法。 该阶段通常进行以下操作:
- 当组件更新后,对 DOM 进行操作;
- 如果你对更新前后的 props 进行了比较,也可以选择在此处进行网络请求;(例如,当 props 未发生变化时,则不会执行网络请求)。
componentDidUpdate(prevProps, prevState, snapshot){}
该方法有三个参数:
- prevProps: 更新前的props
- prevState: 更新前的state
- snapshot: getSnapshotBeforeUpdate()生命周期的返回值
3)组件卸载阶段
卸载阶段只有一个生命周期函数,componentWillUnmount() 会在组件卸载及销毁之前直接调用。在此方法中执行必要的清理操作:
- 清除 timer,取消网络请求或清除
- 取消在 componentDidMount() 中创建的订阅等;
这个生命周期在一个组件被卸载和销毁之前被调用,因此你不应该再这个方法中使用 setState,因为组件一旦被卸载,就不会再装载,也就不会重新渲染。
4)错误处理阶段
componentDidCatch(error, info),此生命周期在后代组件抛出错误后被调用。 它接收两个参数∶
- error:抛出的错误。
- info:带有 componentStack key 的对象,其中包含有关组件引发错误的栈信息
React常见的生命周期如下: React常见生命周期的过程大致如下:
- 挂载阶段,首先执行constructor构造方法,来创建组件
- 创建完成之后,就会执行render方法,该方法会返回需要渲染的内容
- 随后,React会将需要渲染的内容挂载到DOM树上
- 挂载完成之后就会执行componentDidMount生命周期函数
- 如果我们给组件创建一个props(用于组件通信)、调用setState(更改state中的数据)、调用forceUpdate(强制更新组件)时,都会重新调用render函数
- render函数重新执行之后,就会重新进行DOM树的挂载
- 挂载完成之后就会执行componentDidUpdate生命周期函数
- 当移除组件时,就会执行componentWillUnmount生命周期函数
React主要生命周期总结:
- getDefaultProps:这个函数会在组件创建之前被调用一次(有且仅有一次),它被用来初始化组件的 Props;
- getInitialState:用于初始化组件的 state 值;
- componentWillMount:在组件创建后、render 之前,会走到 componentWillMount 阶段。这个阶段我个人一直没用过、非常鸡肋。后来React 官方已经不推荐大家在 componentWillMount 里做任何事情、到现在 React16 直接废弃了这个生命周期,足见其鸡肋程度了;
- render:这是所有生命周期中唯一一个你必须要实现的方法。一般来说需要返回一个 jsx 元素,这时 React 会根据 props 和 state 来把组件渲染到界面上;不过有时,你可能不想渲染任何东西,这种情况下让它返回 null 或者 false 即可;
- componentDidMount:会在组件挂载后(插入 DOM 树中后)立即调用,标志着组件挂载完成。一些操作如果依赖获取到 DOM 节点信息,我们就会放在这个阶段来做。此外,这还是 React 官方推荐的发起 ajax 请求的时机。该方法和 componentWillMount 一样,有且仅有一次调用。
React-Router的实现原理是什么?
客户端路由实现的思想:
- 基于 hash 的路由:通过监听
hashchange事件,感知 hash 的变化- 改变 hash 可以直接通过 location.hash=xxx
- 基于 H5 history 路由:
- 改变 url 可以通过 history.pushState 和 resplaceState 等,会将URL压入堆栈,同时能够应用
history.go()等 API - 监听 url 的变化可以通过自定义事件触发实现
- 改变 url 可以通过 history.pushState 和 resplaceState 等,会将URL压入堆栈,同时能够应用
react-router 实现的思想:
- 基于
history库来实现上述不同的客户端路由实现思想,并且能够保存历史记录等,磨平浏览器差异,上层无感知 - 通过维护的列表,在每次 URL 发生变化的回收,通过配置的 路由路径,匹配到对应的 Component,并且 render
React的事件和普通的HTML事件有什么不同?
区别:
- 对于事件名称命名方式,原生事件为全小写,react 事件采用小驼峰;
- 对于事件函数处理语法,原生事件为字符串,react 事件为函数;
- react 事件不能采用 return false 的方式来阻止浏览器的默认行为,而必须要地明确地调用
preventDefault()来阻止默认行为。
合成事件是 react 模拟原生 DOM 事件所有能力的一个事件对象,其优点如下:
- 兼容所有浏览器,更好的跨平台;
- 将事件统一存放在一个数组,避免频繁的新增与删除(垃圾回收)。
- 方便 react 统一管理和事务机制。
事件的执行顺序为原生事件先执行,合成事件后执行,合成事件会冒泡绑定到 document 上,所以尽量避免原生事件与合成事件混用,如果原生事件阻止冒泡,可能会导致合成事件不执行,因为需要冒泡到document 上合成事件才会执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号