面试题-Redis篇
WhyRedis
速度快,完全基于内存,使用C语言实现,网络层使用epoll解决高并发问题,单线程模型避免了不必要的上下文切换及竞争条件;
| GuavaCache | Tair | EVCache | Aerospike | |
|---|---|---|---|---|
| 类别 | 本地JVM缓存 | 分布式缓存 | 分布式缓存 | 分布式nosql数据库 |
| 应用 | 本地缓存 | 淘宝 | Netflix、AWS | 广告 |
| 性能 | 非常高 | 较高 | 很高 | 较高 |
| 持久化 | 无 | 有 | 有 | 有 |
| 集群 | 无 | 灵活配置 | 有 | 自动扩容 |
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
1、简单高效
1)完全基于内存,绝大部分请求是纯粹的内存操作。数据存在内存中,类似于 HashMap,查找和操作的时间复杂度都是O(1);
2)数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3)采用单线程,避免了多线程不必要的上下文切换和竞争条件,不存在加锁释放锁操作,减少了因为锁竞争导致的性能消耗;(6.0以后多线程)
4)使用EPOLL多路 I/O 复用模型,非阻塞 IO;
5)使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
2、Memcache
| redis | Memcached |
|---|---|
| 内存高速数据库 | 高性能分布式内存缓存数据库 |
| 支持hash、list、set、zset、string结构 | 只支持key-value结构 |
| 将大部分数据放到内存 | 全部数据放到内存中 |
| 支持持久化、主从复制备份 | 不支持数据持久化及数据备份 |
| 数据丢失可通过AOF恢复 | 挂掉后,数据不可恢复 |
| 单线程(2~4万TPS) | 多线程(20-40万TPS) |
使用场景:
1、如果有持久方面的需求或对数据类型和处理有要求的应该选择redis。
2、如果简单的key/value 存储应该选择memcached。
3、Tair
Tair(Taobao Pair)是淘宝开发的分布式Key-Value存储引擎,既可以做缓存也可以做数据源(三种引擎切换)
- MDB(Memcache)属于内存型产品,支持kv和类hashMap结构,性能最优
- RDB(Redis)支持List.Set.Zset等复杂的数据结构,性能次之,可提供缓存和持久化存储两种模式
- LDB(levelDB)属于持久化产品,支持kv和类hashmap结构,性能较前两者稍低,但持久化可靠性最高
分布式缓存
大访问少量临时数据的存储(kb左右)
用于缓存,降低对后端数据库的访问压力
session场景
高速访问某些数据结构的应用和计算(rdb)
数据源存储
快速读取数据(fdb)
持续大数据量的存入读取(ldb),交易快照
高频度的更新读取(ldb),库存
痛点:redis集群中,想借用缓存资源必须得指明redis服务器地址去要。这就增加了程序的维护复杂度。因为redis服务器很可能是需要频繁变动的。所以人家淘宝就想啊,为什么不能像操作分布式数据库或者hadoop那样。增加一个中央节点,让他去代理所有事情。在tair中程序只要跟tair中心节点交互就OK了。同时tair里还有配置服务器概念。又免去了像操作hadoop那样,还得每台hadoop一套一模一样配置文件。改配置文件得整个集群都跟着改。
4、Guava
分布式缓存一致性更好一点,用于集群环境下多节点使用同一份缓存的情况;有网络IO,吞吐率与缓存的数据大小有较大关系;
本地缓存非常高效,本地缓存会占用堆内存,影响垃圾回收、影响系统性能。
本地缓存设计:
以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况,每个实例都需要各自保存一份缓存,缓存不具有一致性。
解决缓存过期:
1、将缓存过期时间调为永久
2、将缓存失效时间分散开,不要将缓存时间长度都设置成一样;比如我们可以在原有的失效时间基础上增加一个随机值,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
解决内存溢出:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
Google Guava Cache
自己设计本地缓存痛点:
- 不能按照一定的规则淘汰数据,如 LRU,LFU,FIFO 等。
- 清除数据时的回调通知
- 并发处理能力差,针对并发可以使用CurrentHashMap,但缓存的其他功能需要自行实现
- 缓存过期处理,缓存数据加载刷新等都需要手工实现
Guava Cache 的场景:
- 对性能有非常高的要求
- 不经常变化,占用内存不大
- 有访问整个集合的需求
- 数据允许不实时一致
Guava Cache 的优势:
- 缓存过期和淘汰机制
在GuavaCache中可以设置Key的过期时间,包括访问过期和创建过期。GuavaCache在缓存容量达到指定大小时,采用LRU的方式,将不常使用的键值从Cache中删除
- 并发处理能力
GuavaCache类似CurrentHashMap,是线程安全的。提供了设置并发级别的api,使得缓存支持并发的写入和读取,采用分离锁机制,分离锁能够减小锁力度,提升并发能力,分离锁是分拆锁定,把一个集合看分成若干partition, 每个partiton一把锁。更新锁定
- 防止缓存击穿
一般情况下,在缓存中查询某个key,如果不存在,则查源数据,并回填缓存。(Cache Aside Pattern)在高并发下会出现,多次查源并重复回填缓存,可能会造成源的宕机(DB),性能下降 GuavaCache可以在CacheLoader的load方法中加以控制,对同一个key,只让一个请求去读源并回填缓存,其他请求阻塞等待。(相当于集成数据源,方便用户使用)
- 监控缓存加载/命中情况
统计
问题:
OOM->设置过期时间、使用弱引用、配置过期策略
5、EVCache
EVCache是一个Netflflix(网飞)公司开源、快速的分布式缓存,是基于Memcached的内存存储实现的,用以构建超大容量、高性能、低延时、跨区域的全球可用的缓存数据层。
E:Ephemeral:数据存储是短暂的,有自身的存活时间
V:Volatile:数据可以在任何时候消失
EVCache典型地适合对强一致性没有必须要求的场合
典型用例:Netflflix向用户推荐用户感兴趣的电影

EVCache集群在峰值每秒可以处理200kb的请求,
Netflflix生产系统中部署的EVCache经常要处理超过每秒3000万个请求,存储数十亿个对象,
跨数千台memcached服务器。整个EVCache集群每天处理近2万亿个请求。
EVCache集群响应平均延时大约是1-5毫秒,最多不会超过20毫秒。
EVCache集群的缓存命中率在99%左右。
典型部署
EVCache 是线性扩展的,可以在一分钟之内完成扩容,在几分钟之内完成负载均衡和缓存预热。

1、集群启动时,EVCache向服务注册中心(Zookeeper、Eureka)注册各个实例
2、在web应用启动时,查询命名服务中的EVCache服务器列表,并建立连接。
3、客户端通过key使用一致性hash算法,将数据分片到集群上。
6、ETCD
和Zookeeper一样,CP模型追求数据一致性,越来越多的系统开始用它保存关键数据。比如,秒杀系统经常用它保存各节点信息,以便控制消费 MQ 的服务数量。还有些业务系统的配置数据,也会通过 etcd 实时同步给业务系统的各节点,比如,秒杀管理后台会使用 etcd 将秒杀活动的配置数据实时同步给秒杀 API 服务各节点。

Redis底层
1、redis数据类型
| 类型 | 底层 | 应用场景 | 编码类型 |
|---|---|---|---|
| String | SDS数组 | 帖子、评论、热点数据、输入缓冲 | RAW << EMBSTR << INT |
| List | QuickList | 评论列表、商品列表、发布与订阅、慢查询、监视器 | LINKEDLIST << ZIPLIST |
| Set | intSet | 适合交集、并集、查集操作,例如朋友关系 | HT << INSET |
| Zset | 跳跃表 | 去重后排序,适合排名场景 | SKIPLIST << ZIPLIST |
| Hash | 哈希 | 结构化数据,比如存储对象 | HT << ZIPLIST |
| Stream | 紧凑列表 | 消息队列 |
2、相关API
| String | SET | SETNX | SETEX | GET | GETSET | INCR | DECR | MSET | MGET |
| Hash | HSET | HSETNX | HGET | HDEL | HLEN | HMSET | HMGET | HKEYS | HGETALL |
| LIST | LPUSH | LPOP | RPUSH | RPOP | LINDEX | LREM | LRANGE | LLEN | RPOPLPUSH |
| ZSET | ZADD | ZREM | ZSCORE | ZCARD | ZRANGE | ZRANK | ZREVRANK | ZREVRANGE | |
| SET | SADD | SREM | SISMEMBER | SCARD | SINTER | SUNION | SDIFF | SPOP | SMEMBERS |
| 事务 | MULTI | EXEC | DISCARD | WATCH | UNWATCH |
3、redis底层结构
SDS数组结构,用于存储字符串和整型数据及输入缓冲。
struct sdshdr{ int len;//记录buf数组中已使用字节的数量 int free; //记录 buf 数组中未使用字节的数量 char buf[];//字符数组,用于保存字符串}
跳跃表:将有序链表中的部分节点分层,每一层都是一个有序链表。
1、可以快速查找到需要的节点 O(logn) ,额外存储了一倍的空间
2、可以在O(1)的时间复杂度下,快速获得跳跃表的头节点、尾结点、长度和高度。
字典dict: 又称散列表(hash),是用来存储键值对的一种数据结构。
Redis整个数据库是用字典来存储的(K-V结构) —Hash+数组+链表
Redis字典实现包括:**字典(dict)、Hash表(dictht)、Hash表节点(dictEntry)**。
字典达到存储上限(阈值 0.75),需要rehash(扩容)
1、初次申请默认容量为4个dictEntry,非初次申请为当前hash表容量的一倍。
2、rehashidx=0表示要进行rehash操作。
3、新增加的数据在新的hash表h[1] 、修改、删除、查询在老hash表h[0]
4、将老的hash表h[0]的数据重新计算索引值后全部迁移到新的hash表h[1]中,这个过程称为 rehash。
渐进式rehash
由于当数据量巨大时rehash的过程是非常缓慢的,所以需要进行优化。 可根据服务器空闲程度批量rehash部分节点压缩列表zipList
压缩列表(ziplist)是由一系列特殊编码的连续内存块组成的顺序型数据结构,节省内容
sorted-set和hash元素个数少且是小整数或短字符串(直接使用)
list用快速链表(quicklist)数据结构存储,而快速链表是双向列表与压缩列表的组合。(间接使用)
整数集合intSet
整数集合(intset)是一个有序的(整数升序)、存储整数的连续存储结构。
当Redis集合类型的元素都是整数并且都处在64位有符号整数范围内(2^64),使用该结构体存储。
快速列表quickList
快速列表(quicklist)是Redis底层重要的数据结构。是Redis3.2列表的底层实现。
(在Redis3.2之前,Redis采 用双向链表(adlist)和压缩列表(ziplist)实现。)
Redis Stream的底层主要使用了listpack(紧凑列表)和Rax树(基数树)。
listpack表示一个字符串列表的序列化,listpack可用于存储字符串或整数。用于存储stream的消息内 容。
Rax树是一个有序字典树 (基数树 Radix Tree),按照 key 的字典序排列,支持快速地定位、插入和删除操 作。
4、Zset底层实现
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度
Zset数据量少的时候使用压缩链表ziplist实现,有序集合使用紧挨在一起的压缩列表节点来保存,第一个节点保存member,第二个保存score。ziplist内的集合元素按score从小到大排序,score较小的排在表头位置。 数据量大的时候使用跳跃列表skiplist和哈希表hash_map结合实现,查找删除插入的时间复杂度都是O(longN)
Redis使用跳表而不使用红黑树,是因为跳表的索引结构序列化和反序列化更加快速,方便持久化。
搜索
跳跃表按 score 从小到大保存所有集合元素,查找时间复杂度为平均 O(logN),最坏 O(N) 。
插入
选用链表作为底层结构支持,为了高效地动态增删。因为跳表底层的单链表是有序的,为了维护这种有序性,在插入前需要遍历链表,找到该插入的位置,单链表遍历查找的时间复杂度是O(n),同理可得,跳表的遍历也是需要遍历索引数,所以是O(logn)。
删除
如果该节点还在索引中,删除时不仅要删除单链表中的节点,还要删除索引中的节点;单链表在知道删除的节点是谁时,时间复杂度为O(1),但针对单链表来说,删除时都需要拿到前驱节点O(logN)才可改变引用关系从而删除目标节点。
Redis可用性
1、redis持久化
持久化就是把内存中的数据持久化到本地磁盘,防止服务器宕机了内存数据丢失
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制,Redis4.0以后采用混合持久化,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
优点:
1)只有一个文件 dump.rdb,方便持久化;
2)容灾性好,一个文件可以保存到安全的磁盘。
3)性能最大化,fork 子进程来进行持久化写操作,让主进程继续处理命令,只存在毫秒级不响应请求。
4)相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低,RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。
AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
优点:
1)数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
2)通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
缺点:
1)AOF 文件比 RDB 文件大,且恢复速度慢。
2)数据集大的时候,比 rdb 启动效率低。
2、redis事务
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
Redis事务的概念
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis的事务总是具有ACID中的一致性和隔离性,其他特性是不支持的。当服务器运行在AOF持久化模式下,并且appendfsync选项的值为always时,事务也具有耐久性。
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的
事务命令:
MULTI:用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值 nil 。
WATCH :是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。(秒杀场景)
DISCARD:调用该命令,客户端可以清空事务队列,并放弃执行事务,且客户端会从事务状态中退出。
UNWATCH:命令可以取消watch对所有key的监控。
3、redis失效策略
内存淘汰策略
1)全局的键空间选择性移除
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(字典库常用)
allkeys-lru:在键空间中,移除最近最少使用的key。(缓存常用)
allkeys-random:在键空间中,随机移除某个key。
2)设置过期时间的键空间选择性移除
volatile-lru:在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,有更早过期时间的key优先移除。
缓存失效策略
定时清除:针对每个设置过期时间的key都创建指定定时器
惰性清除:访问时判断,对内存不友好
定时扫描清除:定时100ms随机20个检查过期的字典,若存在25%以上则继续循环删除。
4、redis读写模式
CacheAside旁路缓存
写请求更新数据库后删除缓存数据。读请求不命中查询数据库,查询完成写入缓存
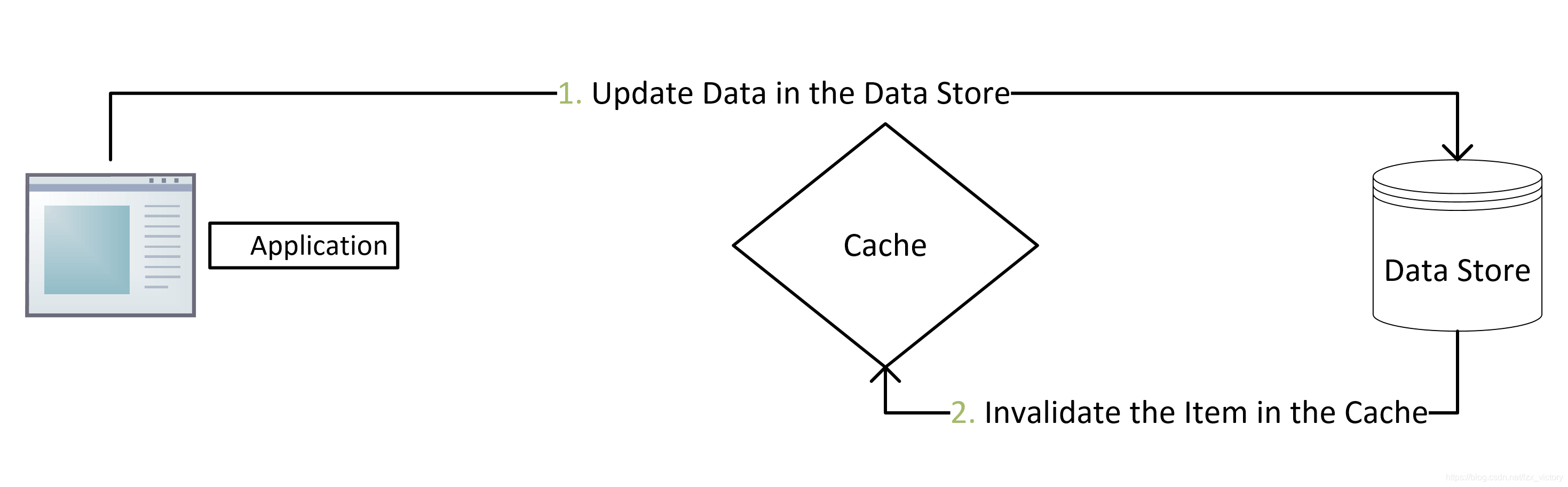

业务端处理所有数据访问细节,同时利用 Lazy 计算的思想,更新 DB 后,直接删除 cache 并通过 DB 更新,确保数据以 DB 结果为准,则可以大幅降低 cache 和 DB 中数据不一致的概率
如果没有专门的存储服务,同时是对数据一致性要求比较高的业务,或者是缓存数据更新比较复杂的业务,适合使用 Cache Aside 模式。如微博发展初期,不少业务采用这种模式
// 延迟双删,用以保证最终一致性,防止小概率旧数据读请求在第一次删除后更新数据库public void write(String key,Object data){ redis.delKey(key); db.updateData(data); Thread.sleep(1000); redis.delKey(key);}高并发下保证绝对的一致,先删缓存再更新数据,需要用到内存队列做异步串行化。非高并发场景,先更新数据再删除缓存,延迟双删策略基本满足了
- 先更新db后删除redis:删除redis失败则出现问题
- 先删redis后更新db:删除redis瞬间,旧数据被回填redis
- 先删redis后更新db休眠后删redis:同第二点,休眠后删除redis 可能宕机
- java内部jvm队列:不适用分布式场景且降低并发
Read/Write Though(读写穿透)
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据.
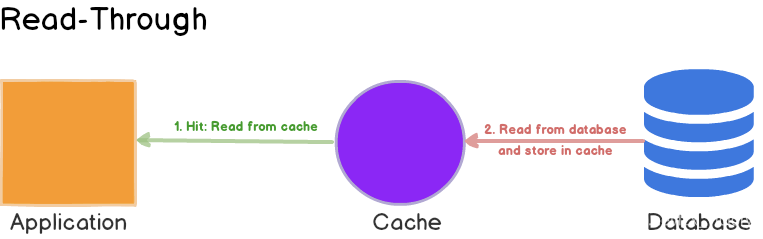
先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中。
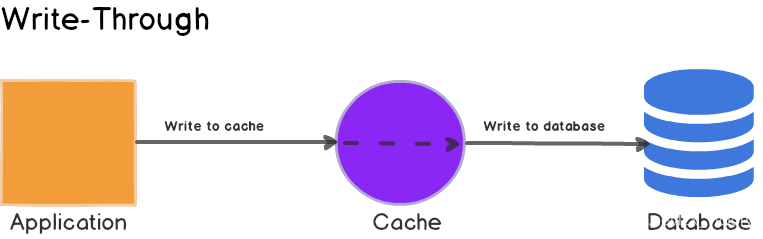
用户读操作较多.相较于Cache aside而言更适合缓存一致的场景。使用简单屏蔽了底层数据库的操作,只是操作缓存.
场景:
微博 Feed 的 Outbox Vector(即用户最新微博列表)就采用这种模式。一些粉丝较少且不活跃的用户发表微博后,Vector 服务会首先查询 Vector Cache,如果 cache 中没有该用户的 Outbox 记录,则不写该用户的 cache 数据,直接更新 DB 后就返回,只有 cache 中存在才会通过 CAS 指令进行更新。
Write Behind Caching(异步缓存写入)

比如对一些计数业务,一条 Feed 被点赞 1万 次,如果更新 1万 次 DB 代价很大,而合并成一次请求直接加 1万,则是一个非常轻量的操作。但这种模型有个显著的缺点,即数据的一致性变差,甚至在一些极端场景下可能会丢失数据。
5、多级缓存
浏览器本地内存缓存:专题活动,一旦上线,在活动期间是不会随意变更的。
浏览器本地磁盘缓存:Logo缓存,大图片懒加载
服务端本地内存缓存:由于没有持久化,重启时必定会被穿透
服务端网络内存缓存:Redis等,针对穿透的情况下可以继续分层,必须保证数据库不被压垮
为什么不是使用服务器本地磁盘做缓存?
当系统处理大量磁盘 IO 操作的时候,由于 CPU 和内存的速度远高于磁盘,可能导致 CPU 耗费太多时间等待磁盘返回处理的结果。对于这部分 CPU 在 IO 上的开销,我们称为 iowait
Redis七大经典问题
1、缓存雪崩
指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
-
Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃
-
本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死
-
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
-
逻辑上永不过期给每一个缓存数据增加相应的缓存标记,缓存标记失效则更新数据缓存
-
多级缓存,失效时通过二级更新一级,由第三方插件更新二级缓存。
2、缓存穿透
https://blog.csdn.net/lin777lin/article/details/105666839
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
1)接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2)从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒。这样可以防止攻击用户反复用同一个id暴力攻击;
3)采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。(宁可错杀一千不可放过一人)
3、缓存击穿
这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
解决方案:
1)设置热点数据永远不过期,异步线程处理。
2)加写回操作加互斥锁,查询失败默认值快速返回。
3)缓存预热
系统上线后,将相关可预期(例如排行榜)热点数据直接加载到缓存。
写一个缓存刷新页面,手动操作热点数据(例如广告推广)上下线。
4、数据不一致
在缓存机器的带宽被打满,或者机房网络出现波动时,缓存更新失败,新数据没有写入缓存,就会导致缓存和 DB 的数据不一致。缓存 rehash 时,某个缓存机器反复异常,多次上下线,更新请求多次 rehash。这样,一份数据存在多个节点,且每次 rehash 只更新某个节点,导致一些缓存节点产生脏数据。
-
Cache 更新失败后,可以进行重试,则将重试失败的 key 写入mq,待缓存访问恢复后,将这些 key 从缓存删除。这些 key 在再次被查询时,重新从 DB 加载,从而保证数据的一致性
-
缓存时间适当调短,让缓存数据及早过期后,然后从 DB 重新加载,确保数据的最终一致性。
-
不采用 rehash 漂移策略,而采用缓存分层策略,尽量避免脏数据产生。
5、数据并发竞争
数据并发竞争在大流量系统也比较常见,比如车票系统,如果某个火车车次缓存信息过期,但仍然有大量用户在查询该车次信息。又比如微博系统中,如果某条微博正好被缓存淘汰,但这条微博仍然有大量的转发、评论、赞。上述情况都会造成并发竞争读取的问题。
- 加写回操作加互斥锁,查询失败默认值快速返回。
- 对缓存数据保持多个备份,减少并发竞争的概率
6、热点key问题
明星结婚、离婚、出轨这种特殊突发事件,比如奥运、春节这些重大活动或节日,还比如秒杀、双12、618 等线上促销活动,都很容易出现 Hot key 的情况。
如何提前发现HotKey?
- 对于重要节假日、线上促销活动这些提前已知的事情,可以提前评估出可能的热 key 来。
- 而对于突发事件,无法提前评估,可以通过 Spark,对应流任务进行实时分析,及时发现新发布的热点 key。而对于之前已发出的事情,逐步发酵成为热 key 的,则可以通过 Hadoop 对批处理任务离线计算,找出最近历史数据中的高频热 key。
解决方案:
-
这 n 个 key 分散存在多个缓存节点,然后 client 端请求时,随机访问其中某个后缀的 hotkey,这样就可以把热 key 的请求打散,避免一个缓存节点过载
-
缓存集群可以单节点进行主从复制和垂直扩容
-
利用应用内的前置缓存,但是需注意需要设置上限
-
延迟不敏感,定时刷新,实时感知用主动刷新
-
和缓存穿透一样,限制逃逸流量,单请求进行数据回源并刷新前置
-
无论如何设计,最后都要写一个兜底逻辑,千万级流量说来就来
7、BigKey问题
比如互联网系统中需要保存用户最新 1万 个粉丝的业务,比如一个用户个人信息缓存,包括基本资料、关系图谱计数、发 feed 统计等。微博的 feed 内容缓存也很容易出现,一般用户微博在 140 字以内,但很多用户也会发表 1千 字甚至更长的微博内容,这些长微博也就成了大 key
- 首先Redis底层数据结构里,根据Value的不同,会进行数据结构的重新选择
- 可以扩展新的数据结构,进行序列化构建,然后通过 restore 一次性写入
- 将大 key 分拆为多个 key,设置较长的过期时间
Redis分区容错
1、redis数据分区
Hash:(不稳定)
客户端分片:哈希+取余
节点伸缩:数据节点关系变化,导致数据迁移
迁移数量和添加节点数量有关:建议翻倍扩容
一个简单直观的想法是直接用Hash来计算,以Key做哈希后对节点数取模。可以看出,在key足够分散的情况下,均匀性可以获得,但一旦有节点加入或退出,所有的原有节点都会受到影响,稳定性无从谈起。
一致性Hash:(不均衡)
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响邻近节点,但是还是有数据迁移
翻倍伸缩:保证最小迁移数据和负载均衡
一致性Hash可以很好的解决稳定问题,可以将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到先遇到的一组存储节点存放。而当有节点加入或退出时,仅影响该节点在Hash环上顺时针相邻的后续节点,将数据从该节点接收或者给予。但这又带来均匀性的问题,即使可以将存储节点等距排列,也会在存储节点个数变化时带来数据的不均匀。
Codis的Hash槽
Codis 将所有的 key 默认划分为 1024 个槽位(slot),它首先对客户端传过来的 key 进行 crc32 运算计算 哈希值,再将 hash 后的整数值对 1024 这个整数进行取模得到一个余数,这个余数就是对应 key 的槽位。
RedisCluster
Redis-cluster把所有的物理节点映射到[0-16383]个slot上,对key采用crc16算法得到hash值后对16384取模,基本上采用平均分配和连续分配的方式。
2、主从模式=简单
主从模式最大的优点是部署简单,最少两个节点便可以构成主从模式,并且可以通过读写分离避免读和写同时不可用。不过,一旦 Master 节点出现故障,主从节点就无法自动切换,直接导致 SLA 下降。所以,主从模式一般适合业务发展初期,并发量低,运维成本低的情况

主从复制原理:
①通过从服务器发送到PSYNC命令给主服务器
②如果是首次连接,触发一次全量复制。此时主节点会启动一个后台线程,生成 RDB 快照文件
③主节点会将这个 RDB 发送给从节点,slave 会先写入本地磁盘,再从本地磁盘加载到内存中
④master会将此过程中的写命令写入缓存,从节点实时同步这些数据
⑤如果网络断开了连接,自动重连后主节点通过命令传播增量复制给从节点部分缺少的数据
缺点
所有的slave节点数据的复制和同步都由master节点来处理,会照成master节点压力太大,使用主从从结构来解决,redis4.0中引入psync2 解决了slave重启后仍然可以增量同步。
3、哨兵模式=读多
由一个或多个sentinel实例组成sentinel集群可以监视一个或多个主服务器和多个从服务器。哨兵模式适合读请求远多于写请求的业务场景,比如在秒杀系统中用来缓存活动信息。 如果写请求较多,当集群 Slave 节点数量多了后,Master 节点同步数据的压力会非常大。

当主服务器进入下线状态时,sentinel可以将该主服务器下的某一从服务器升级为主服务器继续提供服务,从而保证redis的高可用性。
检测主观下线状态
Sentinel每秒一次向所有与它建立了命令连接的实例(主服务器、从服务器和其他Sentinel)发送PING命 令
实例在down-after-milliseconds毫秒内返回无效回复Sentinel就会认为该实例主观下线(SDown)
检查客观下线状态
当一个Sentinel将一个主服务器判断为主观下线后 ,Sentinel会向监控这个主服务器的所有其他Sentinel发送查询主机状态的命令
如果达到Sentinel配置中的quorum数量的Sentinel实例都判断主服务器为主观下线,则该主服务器就会被判定为客观下线(ODown)。
选举Leader Sentinel
当一个主服务器被判定为客观下线后,监视这个主服务器的所有Sentinel会通过选举算法(raft),选出一个Leader Sentinel去执行**failover(故障转移)**操作。
Raft算法
Raft协议是用来解决分布式系统一致性问题的协议。 Raft协议描述的节点共有三种状态:Leader, Follower, Candidate。 Raft协议将时间切分为一个个的Term(任期),可以认为是一种“逻辑时间”。 选举流程:
①Raft采用心跳机制触发Leader选举系统启动后,全部节点初始化为Follower,term为0
②节点如果收到了RequestVote或者AppendEntries,就会保持自己的Follower身份
③节点如果一段时间内没收到AppendEntries消息,在该节点的超时时间内还没发现Leader,Follower就会转换成Candidate,自己开始竞选Leader。 一旦转化为Candidate,该节点立即开始下面几件事情:
--增加自己的term,启动一个新的定时器
--给自己投一票,向所有其他节点发送RequestVote,并等待其他节点的回复。
④如果在计时器超时前,节点收到多数节点的同意投票,就转换成Leader。同时通过 AppendEntries,向其他节点发送通知。
⑤每个节点在一个term内只能投一票,采取先到先得的策略,Candidate投自己, Follower会投给第一个收到RequestVote的节点。
⑥Raft协议的定时器采取随机超时时间(选举的关键),先转为Candidate的节点会先发起投票,从而获得多数票。
主服务器的选择
当选举出Leader Sentinel后,Leader Sentinel会根据以下规则去从服务器中选择出新的主服务器。
- 过滤掉主观、客观下线的节点
- 选择配置slave-priority最高的节点,如果有则返回没有就继续选择
- 选择出复制偏移量最大的系节点,因为复制偏移量越大则数据复制的越完整
- 选择run_id最小的节点,因为run_id越小说明重启次数越少
故障转移
当Leader Sentinel完成新的主服务器选择后,Leader Sentinel会对下线的主服务器执行故障转移操作,主要有三个步骤:
1、它会将失效 Master 的其中一个 Slave 升级为新的 Master , 并让失效 Master 的其他 Slave 改为复制新的 Master ;
2、当客户端试图连接失效的 Master 时,集群会向客户端返回新 Master 的地址,使得集群当前状态只有一个Master。
3、Master 和 Slave 服务器切换后, Master 的 redis.conf 、 Slave 的 redis.conf 和 sentinel.conf 的配置文件的内容都会发生相应的改变,即 Master 主服务器的 redis.conf配置文件中会多一行 replicaof 的配置, sentinel.conf 的监控目标会随之调换。
4、集群模式=写多
为了避免单一节点负载过高导致不稳定,集群模式采用一致性哈希算法或者哈希槽的方法将 Key 分布到各个节点上。其中,每个 Master 节点后跟若干个 Slave 节点,用于出现故障时做主备切换,客户端可以连接任意 Master 节点,集群内部会按照不同 key 将请求转发到不同的 Master 节点
集群模式是如何实现高可用的呢?集群内部节点之间会互相定时探测对方是否存活,如果多数节点判断某个节点挂了,则会将其踢出集群,然后从 Slave 节点中选举出一个节点替补挂掉的 Master 节点。整个原理基本和哨兵模式一致
虽然集群模式避免了 Master 单节点的问题,但集群内同步数据时会占用一定的带宽。所以,只有在写操作比较多的情况下人们才使用集群模式,其他大多数情况,使用哨兵模式都能满足需求
5、分布式锁
利用Watch实现Redis乐观锁
乐观锁基于CAS(Compare And Swap)比较并替换思想,不会产生锁等待而消耗资源,但是需要反复的重试,但也是因为重试的机制,能比较快的响应。因此我们可以利用redis来实现乐观锁(秒杀)。具体思路如下:
1、利用redis的watch功能,监控这个redisKey的状态值
2、获取redisKey的值,创建redis事务,给这个key的值+1
3、执行这个事务,如果key的值被修改过则回滚,key不加1
利用setnx防止库存超卖
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 利用Redis的单线程特性对共享资源进行串行化处理
// 获取锁推荐使用set的方式String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);String result = jedis.setnx(lockKey, requestId); //如线程死掉,其他线程无法获取到锁 // 释放锁,非原子操作,可能会释放其他线程刚加上的锁if (requestId.equals(jedis.get(lockKey))) { jedis.del(lockKey);}// 推荐使用redis+lua脚本String lua = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";Object result = jedis.eval(lua, Collections.singletonList(lockKey),
分布式锁存在的问题:
- 客户端长时间阻塞导致锁失效问题
计算时间内异步启动另外一个线程去检查的问题,这个key是否超时,当锁超时时间快到期且逻辑未执行完,延长锁超时时间。
-
**Redis服务器时钟漂移问题导致同时加锁
redis的过期时间是依赖系统时钟的,如果时钟漂移过大时 理论上是可能出现的 **会影响到过期时间的计算。 -
单点实例故障,锁未及时同步导致丢失
RedLock算法
-
获取当前时间戳T0,配置时钟漂移误差T1
-
短时间内逐个获取全部N/2+1个锁,结束时间点T2
-
实际锁能使用的处理时长变为:TTL - (T2 - T0)- T1
该方案通过多节点来防止Redis的单点故障,效果一般,也无法防止:
-
主从切换导致的两个客户端同时持有锁
大部分情况下持续时间极短,而且使用Redlock在切换的瞬间获取到节点的锁,也存在问题。已经是极低概率的时间,无法避免。Redis分布式锁适合幂等性事务,如果一定要保证安全,应该使用Zookeeper或者DB,但是,性能会急剧下降。
与zookeeper分布式锁对比
- redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
- zk 分布式锁,注册个监听器即可,不需要不断主动尝试获取锁,ZK获取锁会按照加锁的顺序,所以是公平锁,性能和mysql差不多,和redis差别大
Redission生产环境的分布式锁
Redisson是基于NIO的Netty框架上的一个Java驻内存数据网格(In-Memory Data Grid)分布式锁开源组件。

但当业务必须要数据的强一致性,即不允许重复获得锁,比如金融场景(重复下单,重复转账),请不要使用redis分布式锁。可以使用CP模型实现,比如:zookeeper和etcd。
| Redis | zookeeper | etcd | |
|---|---|---|---|
| 一致性算法 | 无 | paxos(ZAB) | raft |
| CAP | AP | CP | CP |
| 高可用 | 主从集群 | n+1 | n+1 |
| 实现 | setNX | createNode | restfulAPI |
6、redis心跳检测
在命令传播阶段,从服务器默认会以每秒一次的频率向主服务器发送ACK命令:
1、检测主从的连接状态 检测主从服务器的网络连接状态
lag的值应该在0或1之间跳动,如果超过1则说明主从之间的连接有 故障。
2、辅助实现min-slaves,Redis可以通过配置防止主服务器在不安全的情况下执行写命令
min-slaves-to-write 3 (min-replicas-to-write 3 )min-slaves-max-lag 10 (min-replicas-max-lag 10) 上面的配置表示:从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令。
3、检测命令丢失,增加重传机制
如果因为网络故障,主服务器传播给从服务器的写命令在半路丢失,那么当从服务器向主服务器发 送REPLCONF ACK命令时,主服务器将发觉从服务器当前的复制偏移量少于自己的复制偏移量, 然后主服务器就会根据从服务器提交的复制偏移量,在复制积压缓冲区里面找到从服务器缺少的数据,并将这些数据重新发送给从服务器。
Redis实战
1、Redis优化

读写方式
简单来说就是不用keys等,用range、contains之类。比如,用户粉丝数,大 V 的粉丝更是高达几千万甚至过亿,因此,获取粉丝列表只能部分获取。另外在判断某用户是否关注了另外一个用户时,也只需要关注列表上进行检查判断,然后返回 True/False 或 0/1 的方式更为高效。
KV size
如果单个业务的 KV size 过大,需要分拆成多个 KV 来缓存。拆分时应考虑访问频率
key 的数量
如果数据量巨大,则在缓存中尽可能只保留频繁访问的热数据,对于冷数据直接访问 DB。
读写峰值
如果小于 10万 级别,简单分拆到独立 Cache 池即可
如果达到 100万 级的QPS,则需要对 Cache 进行分层处理,可以同时使用 Local-Cache 配合远程 cache,甚至远程缓存内部继续分层叠加分池进行处理。(多级缓存)
命中率
缓存的命中率对整个服务体系的性能影响甚大。对于核心高并发访问的业务,需要预留足够的容量,确保核心业务缓存维持较高的命中率。比如微博中的 Feed Vector Cache(热点资讯),常年的命中率高达 99.5% 以上。为了持续保持缓存的命中率,缓存体系需要持续监控,及时进行故障处理或故障转移。同时在部分缓存节点异常、命中率下降时,故障转移方案,需要考虑是采用一致性 Hash 分布的访问漂移策略,还是采用数据多层备份策略。
过期策略
可以设置较短的过期时间,让冷 key 自动过期;也可以让 key 带上时间戳,同时设置较长的过期时间,比如很多业务系统内部有这样一些 key:key_20190801。
缓存穿透时间
平均缓存穿透加载时间在某些业务场景下也很重要,对于一些缓存穿透后,加载时间特别长或者需要复杂计算的数据,而且访问量还比较大的业务数据,要配置更多容量,维持更高的命中率,从而减少穿透到 DB 的概率,来确保整个系统的访问性能。
缓存可运维性
对于缓存的可运维性考虑,则需要考虑缓存体系的集群管理,如何进行一键扩缩容,如何进行缓存组件的升级和变更,如何快速发现并定位问题,如何持续监控报警,最好有一个完善的运维平台,将各种运维工具进行集成。
缓存安全性
对于缓存的安全性考虑,一方面可以限制来源 IP,只允许内网访问,同时加密鉴权访问。
2、Redis热升级
在 Redis 需要升级版本或修复 bug 时,如果直接重启变更,由于需要数据恢复,这个过程需要近 10 分钟的时间,时间过长,会严重影响系统的可用性。面对这种问题,可以对 Redis 扩展热升级功能,从而在毫秒级完成升级操作,完全不影响业务访问。
热升级方案如下,首先构建一个 Redis 壳程序,将 redisServer 的所有属性(包括redisDb、client等)保存为全局变量。然后将 Redis 的处理逻辑代码全部封装到动态连接库 so 文件中。Redis 第一次启动,从磁盘加载恢复数据,在后续升级时,通过指令,壳程序重新加载 Redis 新的 redis-4.so 到 redis-5.so 文件,即可完成功能升级,毫秒级完成 Redis 的版本升级。而且整个过程中,所有 Client 连接仍然保留,在升级成功后,原有 Client 可以继续进行读写操作,整个过程对业务完全透明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号