

kafka
作用
解耦
冗余
扩展
灵活性峰值处理
可恢复性
顺序性保证
缓冲
1、点对点模式,消费者主动拉取数据,消息收到后立即清除。
2、发布订阅模式,一对多,数据产生之后,推送给所有订阅者。
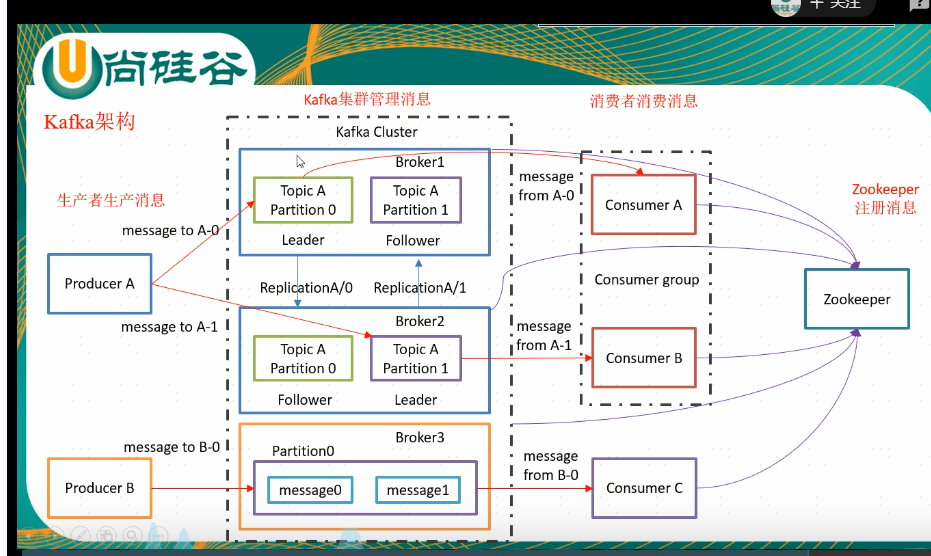
同一个分组的消费者不能消费同一个分区的数据。副本数小于broker数量
生产数据
1、生产者推送数据,消息append到分区中。分区内部有顺序,每个分区维护一个自己的offset。消费者也需要维护自己的offset。分区原因,降低broker负载,提高读的并发性。
分区原则:指定分区。未指定分区,指定了key,通过key进行hash对分区进行取模。轮询的方式。
2、副本备份数据使用,leader和flower不能在同一个broker上面。
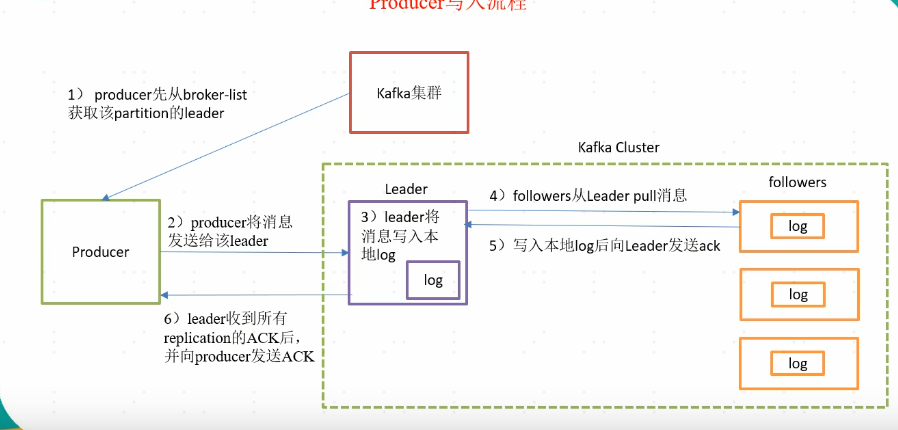
3、生产数据流程,去brokerlist里面找到分区的leader,然后跟leader进行交互。ACK机制,设置为2可以确保不会丢数据。0,leader收不收的不管,1leader收到即可,2leader和所有flower全部收到才算写入成功。
1、消费数据
高级API和低级API
不需要自己管理offset,系统通过zk自行管理,不需要管理分区和副本,系统自动管理。消费者断线后从zk自动获取上次的offset,默认1分钟更新一次zk的offset。可以通过group来区分同一个topic的不同程序访问隔离开。不同程序读取同一个topic,不会相互影响offset。
低级API
自己控制offset,分区。
