基于jaccard相似度的LSH
使用Python通过LSH建立推荐引擎
LSH:一个可以用来处理成百上千行的算法
前提:
Python基础Pandas
学完本教程之后,解锁成就:
- 通过建立
shingles为LSH准备训练集和测试集 - 为
LSH挑选参数 - 为
LSH建立Minhash - 同过
LSH检索推荐会议论文 - 通过
LSH建立不同类型的推荐引擎
LSH—Locality-Sensitive Hashing
我们将基于文章的标题以及摘要来推荐会议论文。我们主要有两种类型的推荐系统:基于内容和协同过滤引擎
- 基于内容的推荐仅仅依赖于所推荐的条目。关于用户的信息一点都没有
- 协同过滤使用了用户的信息。一般来说数据包含了每个用户所使用过的条目的喜好。喜欢和不喜欢可以是暗含着的,比如用户看了一整部电影,也可以是明确的,比如用户对这部电影竖起大拇指或者给予好评。
大体来说,推荐系统本质上是去寻找条目的相似性。我们可以将相似性视为找到具有较大交集的集合。我们可以收集任何条目,例如文档、电影、网页...并称收集到的属性的集合为shingles,或称特征的集合为shingles 。
shingles
shingles是一个基础的广义概念。对于文本,它们可以是字母,一元语法,二元语法。也可以使用类的集合为shingles 。shingles 将我们的文档化简为元素的集合。以此我们可以计算集合之间的相似性。
n元语法(英语:n-gram)指文本中连续出现的n个语词。
对于我们的会议论文,我们将对文章的标题和摘要使用一元语法。如果我们有一组用户喜欢哪篇论文的数据,我们甚至可以把用户当作shingles来使用。通过这种方式,您可以执行基于项目的协同过滤,在其中搜索由同一用户正面评价的项目的MinHash。
同样的,你可以反过来想,让这些项目成为基于用户的协同过滤的shingles。在这种情况下,您将发现与其他用户有着相似的正面评价的用户。
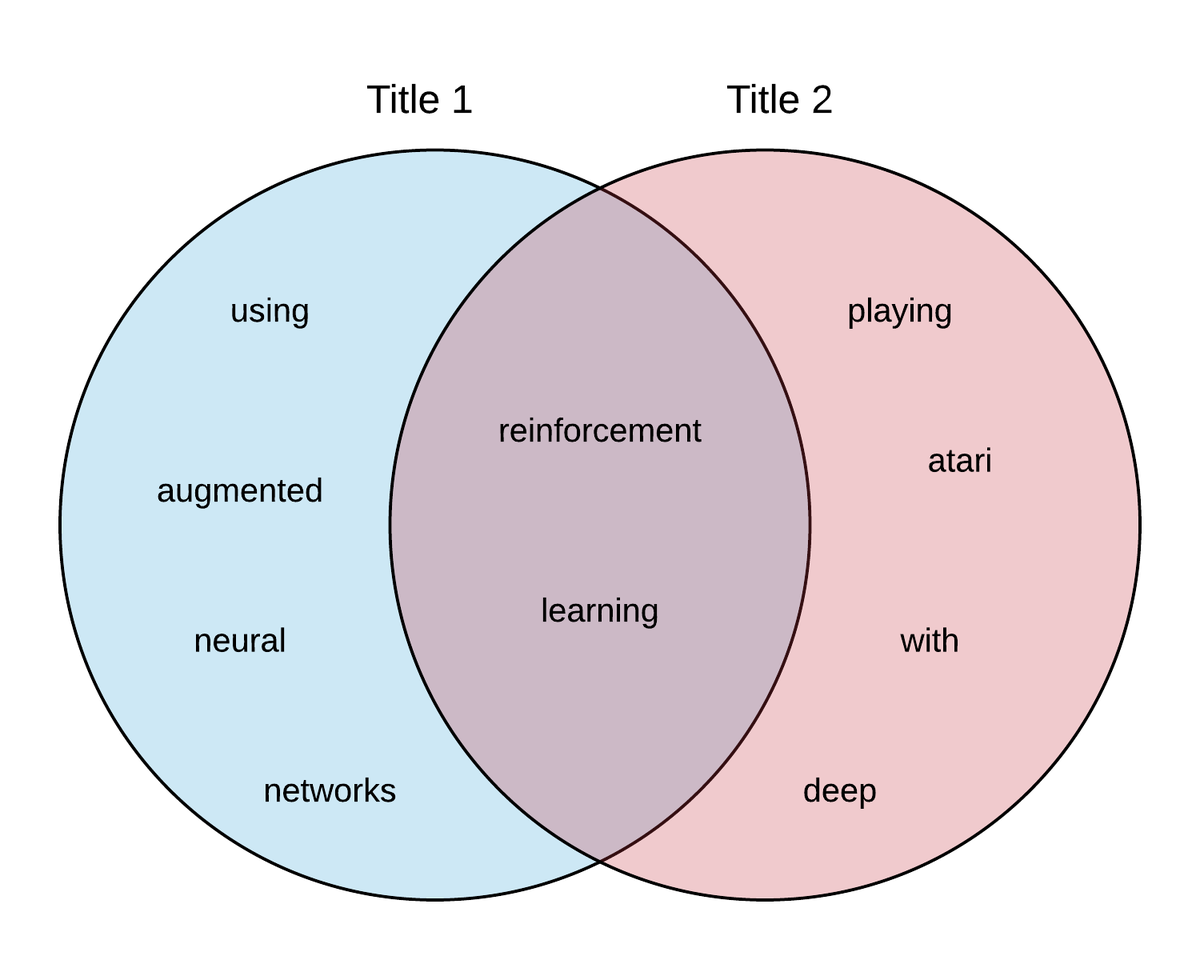
我们取两个论文的标题并且将他们转换为1元语法的shingles 的集合。
- 标题1= "Reinforcement Learning using Augmented Neural networks"
-
shingles=['reinforcement','learning','using','augment','neural','network']
- 标题2="Playing Atari with Deep Reinforcement Learning"
-
shingles=['playing','atari','with','deep','reinforcement','learning']
现在我们通过视觉的方法观察两个集合相交的部分,以此我们可以计算这两标题的相似性。
为什么要使用LSH
LSH 可以被视为一种降维的方法。每当我们想从特别大的数据集进行推荐条目时,就会产生一个问题:我们根本不太可能比对完所有条目的相似性。此外,我们可能会为所有条目提供很少量的重叠数据。
要了解为什么会这样,我们可以考虑存储所有会议论文时创建的词汇矩阵。
传统上,为了提出建议,我们会为每个文档设置一列,每个词设置为一行。因为论文的文本内容差异很大,每一列我们都有很多空行。由此具有稀疏性。为了提供建议,我们将会计算那些具有相同之处的每一行的相似性。
| paper 1 | paper 2 | paper 3 | ... | paper n | |
|---|---|---|---|---|---|
| word 1 | 1 | 0 | 1 | ... | 0 |
| word 2 | 0 | 0 | 0 | ... | 1 |
| word 3 | 0 | 1 | 1 | ... | 1 |
| ... | |||||
| word n | 1 | 0 | 1 | ... | 0 |
这些问题激发了LSH技术的发展。这种技术可以作为更复杂的推荐引擎的基础,方法是将行压缩成“签名”或整数序列,这样我们就可以比较论文,而不必比较整个单词集。
与更传统的推荐引擎相比,LSH主要加快了推荐进程。 这些模型的伸缩性也更好。 因此,与传统的推荐引擎相比,在大型数据集上定期对推荐引擎进行再培训的计算强度要低得多。 在本教程中,我们将通过一个示例向您推荐相似的NIPS会议论文。
商业用例
推荐引擎非常流行。当你使用电脑、手机或平板电脑时,你很可能经常与推荐引擎互动。我们都收到过来自Netflix、Amazon、Facebook、谷歌等网络应用的推荐。这里有几个可能是用例的例子:
- 给顾客推荐产品
- 预测顾客对产品的评价
- 根据调查数据建立消费群体
- 推荐工作流的下一步
- 在工作流的步骤上提供最佳做法
- 侦测剽窃行为
- 查找近似的文章和作者
LSH 的技术概览
LSH用基于相似度的简单概念进行最近邻搜索
当两个条目的集合的并集充分的大时,我们称这俩具有相似性。
这与集合的Jaccard 相似性完全相同,回顾上图,我们对相似度的最终衡量标准是1/5,也就是Jaccard 相似度。
NOTE Jaccard similarity is defined as the intersection of two sets divided by the union of the two sets.
注意,其他的用来度量相似性的方法也可以使用,但是在这个教程中我们严格使用Jaccard 相似度。LSH 是一种像K-NN,k最近邻的一种基于邻域的一种方法。也正如你可以看到的下表一样,与LSH 相比KNN 的扩展性很差。
| Model Build | Query | |
|---|---|---|
| KNN | O(n2) | O(n) |
| LSH | O(n) | O(p) |
\(n: \mbox{number of items}\)
\(p: \mbox{number of permutations}\)
LSH的强大功能在于,随着项目数量的增长,它甚至可以使用Forest技术进行次线性扩展。 如前所述,目标是找到与查询集相似的集。
通用的方法是:
- 对条目进行哈希使得相似的条目进入到一个篮子里具有较高的概率
- 将相似性搜索限制为仅在与查询项关联的存储桶中查询。
将文本转换为shingles 的集合
请记住shingle 是一个独立的元素,它可以是集合的一部分,像字符,一元语法,二元语法。在标准文献中有一个shingle大小的概念,\(k\) ,当shingle的总数为\(20^k\) 。也就是说当你挑选好shingle 的种类的时候,也已经暗示了shingle 的大小。
举个例子,我们使用字母表中的字母作为shingle ,所有我们有26种shingle ,这也是shingle 的种数,此时\(k=1,20^k\)近似于是字母表中经常使用的不同字符的数量。
当shingling 文档为一元语法时看,我们会发现存在大量可能的单词,即,我们将k的值设置为较大。下表提供了shingle数量相对于shingle大小k时的情况。
| k | \(20^k\) |
|---|---|
| 2 | 400 |
| 3 | 8000 |
| 4 | 16000 |
| 5 | 32000 |
当涉及到挑选shingle 的时候,你必须有充足不同的shingle ,以使得shingle 出现在给定文档的可能性较低。如果一个shingle 在你的所有集合中出现的过于频繁,这个shingle 就不可能提供区别于其他集合的信息。在自然语言处理NPL 中有一个很经典的实例就是”the“,这个出现的太普遍了。大多数的自然语言处理时都会将文档中的the 移除掉,因为其根本不会提供更有用的信息。类似的,你也不想使用一个出现在所有文档中的属性当作shingle 。它降低了方法的效率。你在TF-IDF 中也可以看到这样的想法。出现在太多文档的条目会被打折。
由于您希望任何单个shingle出现在给定文档中的概率都很低,因此我们甚至可以查看包含双格、三格或更大的shingle。如果两个文档中有大量相同的双字母或三字母格式,则表明这些文档非常相似。
当寻找适当数量的shingle时,请查看文档中出现的平均字符或标记数。 确保选择足够的shingle,以使文档中的shingle比平均数量多得多。
取shingle
对于这篇文章我们将会推荐会议文章。我们将快速浏览一个与会议论文标题有关的例子:
"Self-Organization of Associative Database and Its Applications"
如果我们使用一元语法作为shingle 时,我们应当移除所有标点符号和停用词,并且小写所有字符得到以下结果:
['self','organization','associative','database','application']
注意我们去除了通常的停用词'like','of','and',and 'its'因为这些词提供有用的信息特别少。
Minhash 签名?特征?
Minhash的主要目标是用小的signature(这块翻译成签名其实挺合适的)取代大的集合,而且还保留了潜在的相似性度量。
为了对每个集合建立Minhash签名:
- 对
shingle matrix其行随机排列。即行12345,变成了行35421,。例如如果"reininforcement" 过去在行1,现在就是在行5。这块如果看不懂可以看这篇 - 对于每一个集合(在我们的例子中是文章的标题),从开始位置起,找到在集合中第一个出现
shingle的位置。第一个shingle的位置。使用这个shingle number代表集合。这就是签名signature - 根据需求重复多次,每次都会将结果附加到集合的签名中。
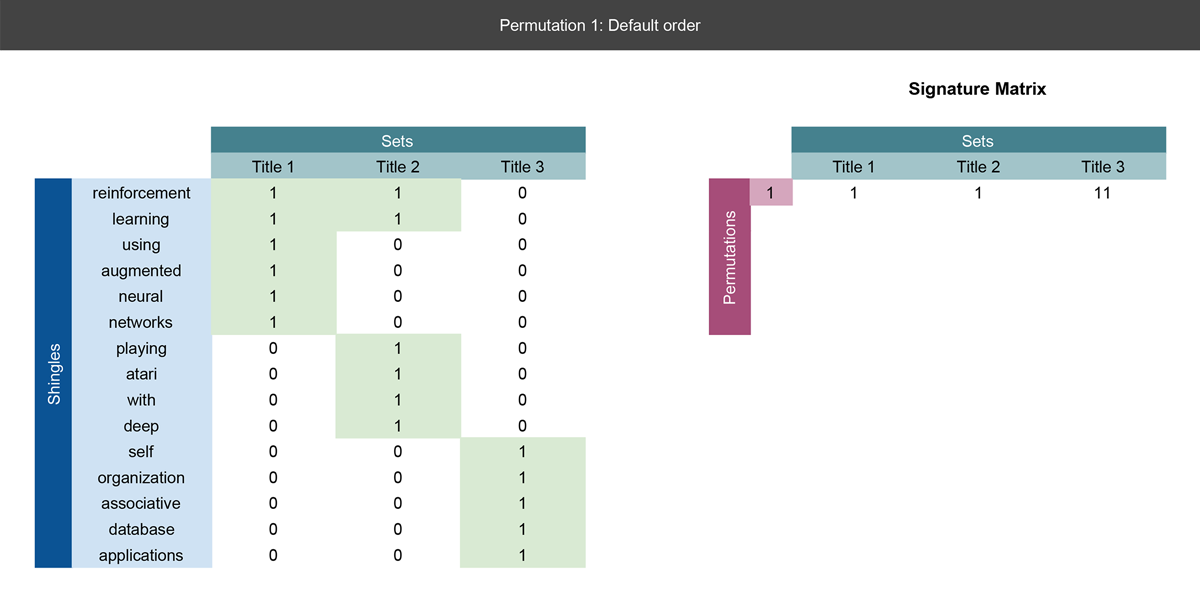
我们对三个论文标题进行具体的检验。我们已经shingled 标题为一元语法的集合,所以我们可以将其放入进一个矩阵中并且执行以上三步。
\({step\ one}\cal\)
\(\cal{step\ two }\)

\(\cal{step\ three}\)
\(\cal{step \ four}\)
注意:这只是一个简化的小例子,我们仅仅用到了文章的标题。在下面的实现中我们将会把摘要部分加入进去来实现更精确的推荐。
第一张幻灯片
在左侧,我们定义了矩阵,每个标题为一列,我们把三个标题中遇到所有单词定义为行,如果以一个单词在标题中出现了,我们在此单词行对应的标题下记为1,这就是我们哈希函数的输入矩阵。
注意,右边签名矩阵中的第一个记录就是我们首先找到1的当前行号。有关更详细的解释,请参阅下一张幻灯片。
第二张幻灯片
我们执行第一个实数行全排列。我们注意到,一元语法的单词有了新的排序。在右侧,我们又得到了新的签名矩阵,我们将在那里记录排列的结果。
在每次排列中,我们都会记录在标题中第一次单词出现的行数,即,在这次排列中第一次单词出现所在的行数。在此次排列中标题1标题2第一个一元单词都出现在行1.因此在标题1标题2下的签名矩阵第一行都写着1。对于标题三来说,第一个一元单词出现在第5行。在签名矩阵中,标题三那列的第一行就记录为5.
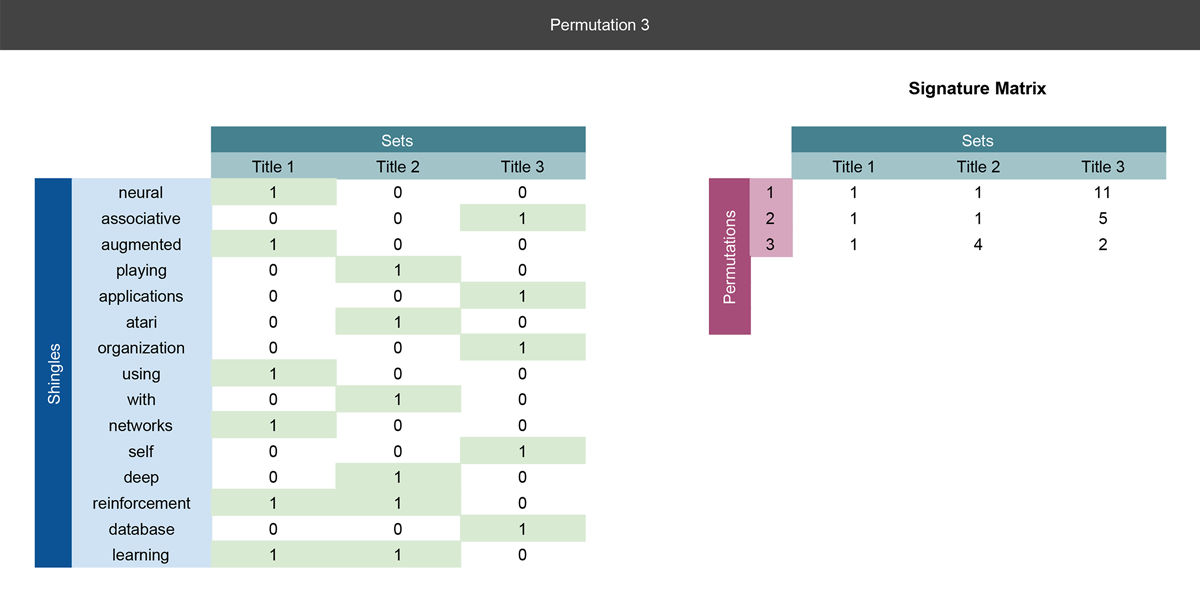
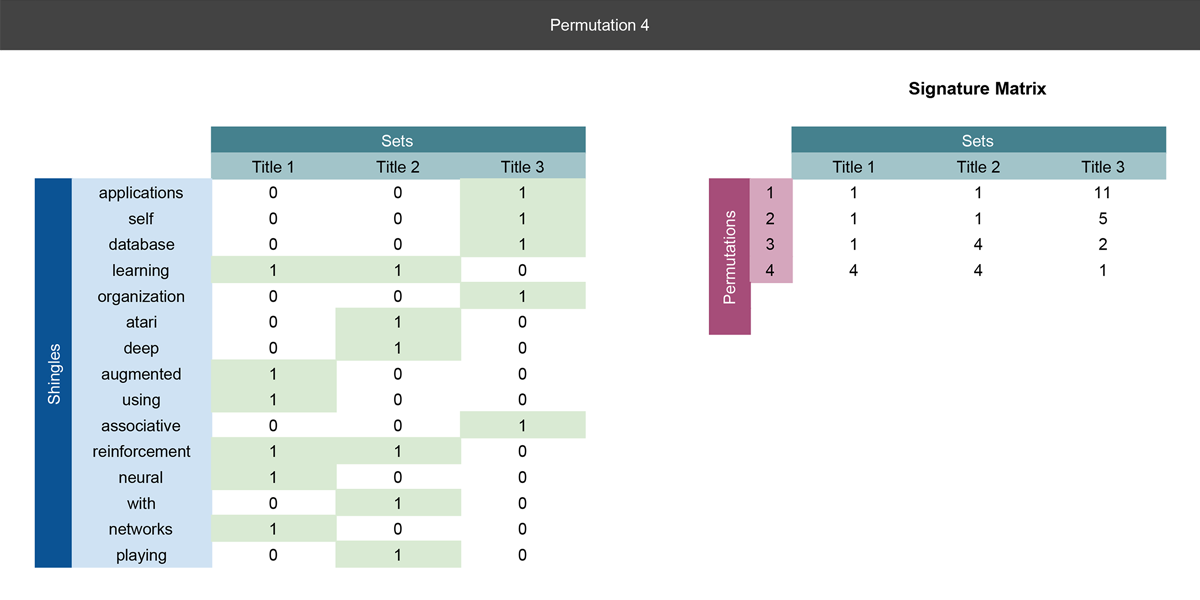
第三四张幻灯片
本质上呢,这步也是像第二张幻灯片一样。,唯一的不同点呢就是我们在每次给输入矩阵重新排列的时候都会将结果记录并添加到右侧的签名矩阵中。
到目前来说我么已经完成了三次排列,并且实际上我们已经可以使用签名矩阵去计算标题之间的相似性。注意我们是如何将shingle 矩阵中的15行压缩到签名矩阵中的3行的。
经过MinHash 过程,每篇会议论文都会由MinHash 的签名所取代,在那里,矩阵的行数远小于起始shingle 矩阵。只是因为我们通过行全排列所获得的签名。而且需要的排列数,远少于shingle 数。
现在如果我们考虑在文章标题和摘要所有的单词,那我们可能以后上百万个行。通过行排列建立签名,我们可以有效的将上百万个行数降低到数百行,而不失其计算相似性的能力
显然,行排列的次数越多,就会获得越多的签名。这就给我们提供了最终的目标,也就是相似的会议论文的签名也是相似的。事实上,你可以观察以下结论(其中签名的相似性为相同的行数比上签名矩阵所具有的总行数):
为了进一步提升效率,在实际使用上我们用随机哈希函数代替行的随机排列。
在MinHash 签名上的LSH
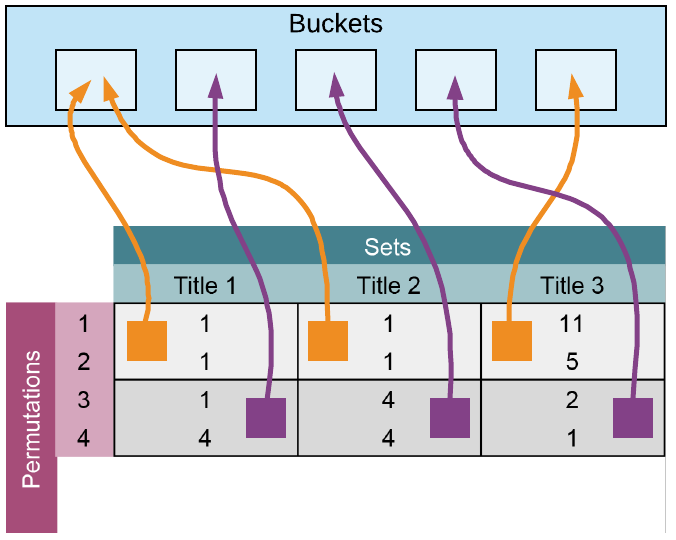
现在。上面的签名矩阵被分解成b组,每组r行,每一行都分别为hash .对于这个例子来说,我们将组数设置为2,也就是意味着我们将把头两行相同的标题视为相似的。 如果组数越大,b越大,另一篇匹配相同排列的论文出现的可能性就越小。
举个例子。注意上面呈现的矩阵中的第一组,会议论文标题1和会议论文标题2将会进入相同的桶中,因为它们含有相同的组,此时的标题三完全不同。尽管是标题1标题2的签名有不同,他们依然会进入到同一个桶中,并且在组的规模一定条件下考虑相似性。
Ultimately,最终,组的大小控制着具有给定Jaccard相似性的两个项目最终出现在同一存储桶中的可能性。如果组数很大,就会得到很小的集合。举个例子,\(b=p\) ,\(p\) 是排列的次数,也是签名矩阵的行数,也会导致对于每一个条目都会建立一个哈希桶,对于每次排列这是最好的相似。对于我们挑选的组的大小来说,我们真正要寻找的是对于两类错误的容忍性,一种是假阳性(出现在共同的桶中,却不是相似的文档),还有一种是假阴性(没有出现在共同的桶中却是相似的文档)
推荐的检索
当有一个新的检索时,我们使用一下流程。
- 将要检索的文本转换为
shingles或者tokens - 对
shingle set进行MinHash和LSH,将其映射到一个特殊的桶中 - 在要查询的条目和在桶里的其他条目之中进行相似度搜索。
在实际上可以通过LSH Forest 算法进行高效的搜索来提高效率。想要更多的info,看这个👤 M. Bawa, T. Condie and P. Ganesan, "LSH Forest: Self-Tuning Indexes for Similarity Search.
LSH 清单
作为执行LSH 的一个最终的清单,先确保完成了以下步骤:
- 对于数据集,建立了
shingles,也即1元语法,二元语法,等级等等 - 建立了\(m \times n\) 的矩阵,对于每一个
shingle来说,在一个集合里出现了就标记为1,不出现就标记为2 - 重新对
shingle matrix进行行排列,并经历步骤二在建立一个\(p \times n\) 的签名矩阵,其中记录集合中出现的第一个shingle的行数用于签名矩阵的排列。 - 对于输入矩阵重新排列\(p\)次,将\(p\times n\)的签名矩阵补充完全
- 选择一个带宽大小b作为您将在LSH矩阵的集合之间进行比较的行数。
在Python 中实现LSH
步骤一加载包
import numpy as np
import pandas as pd
import re
import time
from datasketch import MinHash, MinHashLSHForest
步骤二浏览数据
在此次教程中我们的目的是同过LSH 快速的对所有已知的会议论文做出检索来对会议论文进行推荐。更一般的是,首先需要检验数据,为了更适合的对数据预处理以及找到合适的参数,需要深刻的理解你的数据集。我们给出挑选参数的一些基本指导。如上所述都需要探索实验集。
为了本教程的顺利进行,我们在这来实现一个简单的数据集。kaggle上有神经信息处理系统(NIPS)的会议论文。点他
对于这些文章的数据探索可以点他.
第三步预处理数据
对于此文章,我们粗略的使用一元语法作为我们的shingle .我们通过以下步骤:
- 移除所有标点符号
- 小写文本
- 通过分割空白,建立一元语法的
shingle或者来说token
#Preprocess will split a string of text into individual tokens/shingles based on whitespace.
def preprocess(text):
text = re.sub(r'[^\w\s]','',text)
tokens = text.lower()
tokens = tokens.split()
return tokens
有个简单的例子可以如下表示:
text = 'The devil went down to Georgia'
print('The shingles (tokens) are:', preprocess(text))
The shingles (tokens) are: ['the', 'devil', 'went', 'down', 'to', 'georgia']
第四步挑选参数
为了顺利进行我们的例子,我们将会使用标准的128个排列。也会进行一个推荐。
#Number of Permutations
permutations = 128
#Number of Recommendations to return
num_recommendations = 1
步骤五对于检索建立Minhash Forest
为了建立Minhash Forest 我们将执行以下步骤:
- 将你想要检索的所有字符都放入到一个
dataframe中 - 对文本的一个字符串,安照上文所展示的步骤进行预处理。
- 在
MinHash中设置排列数 - 在所有存在字符串中的
shingle中,对字符串进行Minhash - 储存字符串的
Minhash值 - 在
dataframe中重复2-5步 - 对所有的进行
MinHash的字符串建立一个forest - 对你的
forest建立一个索引,使其具有可搜索性
def get_forest(data, perms):
start_time = time.time()
minhash = []
for text in data['text']:
tokens = preprocess(text)
m = MinHash(num_perm=perms)
for s in tokens:
m.update(s.encode('utf8'))
minhash.append(m)
forest = MinHashLSHForest(num_perm=perms)
for i,m in enumerate(minhash):
forest.add(i,m)
forest.index()
print('It took %s seconds to build forest.' %(time.time()-start_time))
return forest
步骤六评估检索
为了去在建立好的forest中检索,我们将遵循以下步骤:
- 对文本进行预处理,也即将其转换为
shingles - 为您的
MinHash设置与构建森林时相同的排列数量。 - 对你的文本中的所有
shinglse建立MinHash - 用新得到的
Minhash值进行检索,并返回数个推荐 - 提供推荐的每篇论文的标题
def predict(text, database, perms, num_results, forest):
start_time = time.time()
tokens = preprocess(text)
m = MinHash(num_perm=perms)
for s in tokens:
m.update(s.encode('utf8'))
idx_array = np.array(forest.query(m, num_results))
if len(idx_array) == 0:
return None # if your query is empty, return none
result = database.iloc[idx_array]['title']
print('It took %s seconds to query forest.' %(time.time()-start_time))
return result
用NIPS会议论文测试我们的推荐系统
首先我们先加载包含会议论文的CSV ,并创建一个将标题和摘要相结合的新字段。由此,我们可以得到由标题和摘要组成的共同的shingles
最终,我们可以查询文本的任意字符串,例如标题或者是话题来返回一列的推荐。注意我么以下的例子,我们只挑选了会议论文的标题。自然的,我么得到的精确答案会成为我们的推荐之一。
db = pd.read_csv('papers.csv')
db['text'] = db['title'] + ' ' + db['abstract']
forest = get_forest(db, permutations)
It took 12.728999853134155 seconds to build forest.
num_recommendations = 5
title = 'Using a neural net to instantiate a deformable model'
result = predict(title, db, permutations, num_recommendations, forest)
print('\n Top Recommendation(s) is(are) \n', result)
It took 0.006001949310302734 seconds to query forest.
Top Recommendation(s) is(are)
995 Neural Network Weight Matrix Synthesis Using O...
5 Using a neural net to instantiate a deformable...
5191 A Self-Organizing Integrated Segmentation and ...
2069 Analytic Solutions to the Formation of Feature...
2457 Inferring Neural Firing Rates from Spike Train...
Name: title, dtype: object
结论:
仅作为最后一个注记,你可以使用这种方法建立多种推荐引擎。你不需要仅仅限制于我们阐述过的基于文本内容的过滤。你可以使用这种方法进行协同过滤引擎。
总之,我们教程的流程,介绍了Locality-Sensitive Hashing此处的材料可以用作一般指南。如果您要处理大量项目,并且相似性度量标准是Jaccard相似性度量标准,则LSH提供了一种非常强大且可扩展的方式来得出推荐。
☑️英文原版在这

 浙公网安备 33010602011771号
浙公网安备 33010602011771号