KS检验详细介绍
本文参考:https://zhuanlan.zhihu.com/p/29399126(详细参考该链接,本文只是记录,以备后续查看)


6. 例子 1 对一台设备进行寿命检验,记录10次无故障工作时间,并按照从小到大的次序排列如下:(单位小时)
420 500 920 1380 1510 1650 1760 2100 2300 2350
用Kolmogorov-Smirnov检验方法检验这些数据的分布是否为参数为1/1500的指数分布?
解:(1) 用ks.test()函数进行检验
x<-c(420,500,920,1380 ,1510, 1650,1760,2100,2300, 2350)
ks.test(x,"pexp",1/1500)
运行结果如下:
One-sample Kolmogorov-Smirnov test
data: x
D = 0.30148, p-value = 0.2654
alternative hypothesis: two-sided
因为p值大于0.05,无法拒绝原假设,因此接受这些数据服从为参数为1/1500的指数分布。
(2)用统计模拟方法计算p值.
- 作业:(1)用统计模拟方法计算例子1中的p值。
x<-c(420, 500 ,920 ,1380, 1510, 1650, 1760 ,2100 ,2300 ,2350)
n<-length(x)
d<-max(1:n/n-pexp(x,1/1500),pexp(x,1/1500)-0:(n-1)/n)
r<-10000
D<-0
for(i in 1:r){u<-runif(n);y<-sort(u);D[i]<-max(1:n/n-y,y-0:(n-1)/n)}
p<-length(D[D>d])/r
p
p值的运行结果为:
[1] 0.2656
即模拟的p值为0.2656.
------------------
(2)假设从一个总体中抽取容量为14的样本:164, 142, 110, 153, 103, 52, 174, 88, 178, 184, 58, 62, 132, 128,问该总体是否服从区间为(50,200)的均匀分布?
题目要求:首先用ks.test()函数进行检验,然后用统计模拟方法计算p值,说明检验结果。
解:首先用ks.test()函数进行检验,
x<-c(164, 142, 110, 153, 103, 52, 174, 88, 178, 184, 58, 62, 132, 128)
ks.test(x,"punif",50,200)
结果如下:
One-sample Kolmogorov-Smirnov test
data: x
D = 0.13429, p-value = 0.9332
alternative hypothesis: two-sided
由于p值= 0.9332>0.05,因此接受该总体服从区间为(50,200)的均匀分布。
-----------
统计模拟的方法
x<-c(164, 142, 110, 153, 103, 52, 174, 88, 178, 184, 58, 62, 132, 128)
n<-length(x)
y<-sort(x)
d<-max(1:n/n-punif(y,50,200),punif(y,50,200)-0:(n-1)/n)
r<-10000
D<-0
for(i in 1:r){
u<-runif(n)
y<-sort(u)
D[i]<-max(1:n/n-y,y-0:(n-1)/n)
}
p<-length(D[D>d])/r
p
p值的运行结果为:
[1] 0.9357
即模拟的p值为0.9357.
(3)假设从一个总体中抽取容量为20的样本:-1.4716958 0.2431494 0.8265337 1.8980804 -4.0423784 3.4327539 5.9290206 1.8254857 -2.4829388 2.5908620 -2.7393827 7.1431654 2.8001338 -0.8907646 6.5693761 -4.2833803 -1.1415025 -8.5100896 2.6901414 10.2162229
该总体是否服从N(1,16)?
x<-c(-1.4716958, 0.2431494, 0.8265337, 1.8980804, -4.0423784, 3.4327539 , 5.9290206, 1.8254857, -2.4829388 , 2.5908620, -2.7393827, 7.1431654, 2.8001338 ,-0.8907646, 6.5693761, -4.2833803, -1.1415025, -8.5100896 , 2.6901414 ,10.2162229)
n<-length(x)
y<-sort(x)
d<-max(1:n/n-pnorm(y,1,4),pnorm(y,1,4)-0:(n-1)/n)
r<-10000
D<-0
for(i in 1:r){
u<-runif(n)
y<-sort(u)
D[i]<-max(1:n/n-y,y-0:(n-1)/n)
}
p<-length(D[D>d])/r
p
KS检验是如何工作的?
首先观察下分析数据
对于以下两组数据:
controlB={1.26, 0.34, 0.70, 1.75, 50.57, 1.55, 0.08, 0.42, 0.50, 3.20, 0.15, 0.49, 0.95, 0.24, 1.37, 0.17, 6.98, 0.10, 0.94, 0.38}
treatmentB= {2.37, 2.16, 14.82, 1.73, 41.04, 0.23, 1.32, 2.91, 39.41, 0.11, 27.44, 4.51, 0.51, 4.50, 0.18, 14.68, 4.66, 1.30, 2.06, 1.19}
对于controlB,这些数据的统计描述如下:
Mean = 3.61
Median = 0.60
High = 50.6 Low = 0.08
Standard Deviation = 11.2
可以发现这组数据并不符合正态分布, 否则大约有15%的数据会小于均值-标准差(3.61-11.2),而数据中显然没有小于0的数。
观察数据的累计分段函数(Cumulative Fraction Function)
对controlB数据从小到大进行排序:
sorted controlB={0.08, 0.10, 0.15, 0.17, 0.24, 0.34, 0.38, 0.42, 0.49, 0.50, 0.70, 0.94, 0.95, 1.26, 1.37, 1.55, 1.75, 3.20, 6.98, 50.57}。10%的数据(2/20)小于0.15,85%(17/20)的数据小于3。所以,对任何数x来说,其累计分段就是所有比x小的数在数据集中所占的比例。下图就是controlB数据集的累计分段图
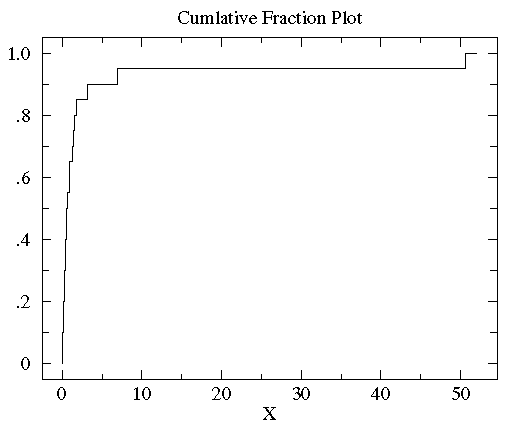
可以看到大多数数据都几种在图片左侧(数据值比较小),这就是非正态分布的标志。为了更好的观测数据在x轴上的分布,可以对x轴的坐标进行非等分的划分。在数据都为正的时候有一个很好的方法就是对x轴进行log转换。下图就是上图做log转换以后的图:

将treatmentB的数据也做相同的图(如下),可以发现treatmentB和controlB的数据分布范围大致相同(0.1 - 50)。但是对于大部分x值,在controlB数据集中比x小的数据所占的比例比在treatmentB中要高,也就是说达到相同累计比例的值在treatment组中比control中要高。KS检验使用的是两条累计分布曲线之间的最大垂直差作为D值(statistic D)作为描述两组数据之间的差异。在此图中这个D值出现在x=1附近,而D值为0.45(0.65-0.25)。
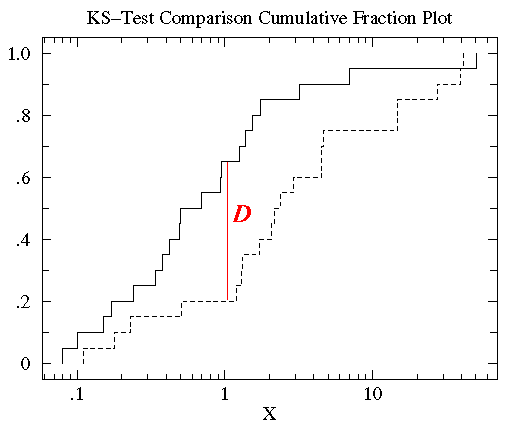
值得注意的是虽然累计分布曲线的性状会随着对数据做转换处理而改变(如log转换),但是D值的大小是不会变的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号