Bigkey

MoreKey案例
大批量往redis里面插入2000W测试数据key
- Linux Bash下面执行,插入100W
# 生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt;done;
- 通过redis提供的管道--pipe命令插入100W大批量数据
cat /tmp/redisTest.txt | redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
127.0.0.1:6379> DBSIZE
(integer) 1000001
127.0.0.1:6379> get k1000000
"v1000000"
某快递巨头真实生产案例新闻
生产上限制keys */flushdb/flushall等危险命令以防止误删误用
通过配置设置禁用这些命令,redis.conf在SECURITY这一项中

配置完成后重新启动服务器测试,发现这些命令都不能用了

不用Key * 避免卡顿,那该用什么
SCAN:用于迭代数据库中的数据库键
- 基本语法
SCAN cursor [MATH patten][COUNT count]
例:一直翻到想要找的数据为止,若返回0则表示所有数据都已遍历完
127.0.0.1:6379> scan 0 match k* count 15
1) "360448"
2) 1) "k978480"
2) "k815593"
3) "k787850"
4) "k642136"
5) "k303818"
6) "k253563"
7) "k298391"
8) "k68241"
9) "k269843"
10) "k475649"
11) "k851176"
12) "k276609"
13) "k316905"
14) "k952181"
15) "k101724"
127.0.0.1:6379> scan 360448 match k* count 15
1) "147456"
2) 1) "k714195"
2) "k995344"
3) "k985587"
4) "k28048"
5) "k397311"
6) "k461726"
7) "k784947"
8) "k566007"
9) "k685608"
10) "k962394"
11) "k768303"
12) "k773594"
13) "k116391"
14) "k185021"
15) "k176693"
127.0.0.1:6379>
- cursor:游标
- patten:匹配的模式
- count:指定从数据集里返回多少元素,默认值为10
- SCAN 命令是一个基于游标的迭代器,每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数,以此来延续之前的迭代过程
- SCAN返回一个包含两个元素的数组
- 第一个元素是用于进行下一次迭代的新游标
- 第二个元素则是一个数组,这个数组中包含了所有被迭代的元素。如果新游标返回0表示迭代已结束
- SCAN的遍历顺序
非常特别,它不是从第一位数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏
BigKey案例
多大算Big
- String和二级结构
- string是value,最大512MB但是≥10KB就是bigkey
- list、hash、set和zset,个数超过5000就是bigkey
哪些危害
- 内存不均,集群迁移困难
- 超时删除,大Key删除作梗
- 网络流浪阻塞
如何产生
- 社交类,比如某明星粉丝列表,典型案例粉丝逐步递增
- 汇总统计,比如某个报表,月日年经年累月的积累
如何发现
redis-cli --bigkeys
MEMORY USAGE键
如何删除
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会出现在慢查询中(latency可查))
String 一般用del,如果过于庞大unlink
hash 使用hascan每次获取少量field-value,再使用hdel删除每个field
list 使用ltrim渐进式逐步删除,直到全部删除完成
set 使用sscan每次获取部分元素,再使用srem命令删除每个元素
zset 使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素
BigKey生产调优
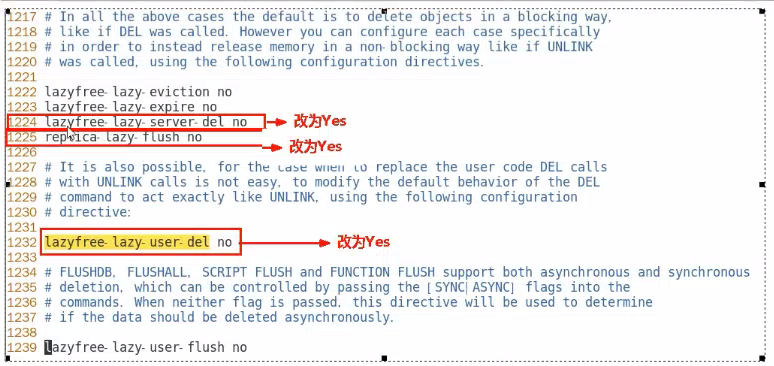
redis.conf配置文件LAZY FREEING相关说明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号