redis十大数据类型
命令查询
redis字符串(String)
- String(字符串)
- string是redis最基本的类型,一个key对应一个value
- string类型是
二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象。 - string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M。
案例:
set key value
set key values [NX|XX] [GET] [EX seconds|PX milliseconds|EXAT unix-time-seconds|PXAT unix-time-milliseconds|LEEPTTL]
set命令有 EX、PX、NX、XX以及KEEPTTL五个可选参数,其中KEEPTTL为6.0版本添加的可选参数,其它为2.6.12版本添加的可选参数。
- EX seconds:以秒为单位设置过期时间
127.0.0.1:6379> set k1 v1 ex 5
OK
127.0.0.1:6379> ttl k1
(integer) 4
127.0.0.1:6379> ttl k1
(integer) 1
- PX milliseconds:以毫秒为单位设置过期时间(少用)
127.0.0.1:6379> set k1 v1 px 3000
OK
127.0.0.1:6379> ttl k1
(integer) 0
127.0.0.1:6379> ttl k1
(integer) -2
- NX:键不存在的时候设置键值
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k1 v1 nx
(nil)
127.0.0.1:6379> set k4 v4 nx
OK
- XX:键存在的时候设置键值
127.0.0.1:6379> set k1 v1 xx
OK
127.0.0.1:6379> set k5 v5 xx
(nil)
常用命令:
- 最常用
set key value
get key
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
- 同时设置/获取多个键值
mset
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
- 获取指定区间范围内的值
mget
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
- 数值增减
(1)incr key:将存储在指定的key的数值增加1
127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> incr k1
(integer) 101
127.0.0.1:6379> incr k1
(integer) 102
127.0.0.1:6379> incr k1
(integer) 103
(2)incrby key incre:将存储在指定key的数值增加指定的增值量
127.0.0.1:6379> incrby k1 5
(integer) 108
127.0.0.1:6379> incrby k1 5
(integer) 113
127.0.0.1:6379> incrby k1 5
(integer) 118
(3)decr key:将存储在指定key的数值减少1
127.0.0.1:6379> decr k1
(integer) 117
127.0.0.1:6379> decr k1
(integer) 116
127.0.0.1:6379> decr k1
(integer) 115
(4)decrby key:将存储在指定key的数值减少指定的减量值
127.0.0.1:6379> decrby k1 5
(integer) 109
127.0.0.1:6379> decrby k1 5
(integer) 104
127.0.0.1:6379> decrby k1 5
(integer) 99
- 获取字符串长度和内容追加
strlenappend
127.0.0.1:6379> get k1
"99123"
127.0.0.1:6379> strlen k1
(integer) 5
127.0.0.1:6379> append k1 333
(integer) 8
127.0.0.1:6379> strlen k1
(integer) 8
127.0.0.1:6379> get k1
"99123333"
- 分布式锁
- setnx key value
- setex(set with expire)键秒值/setnx(set if not exist)
- getset(先get再set)
127.0.0.1:6379> getset k2 333
"v2"
127.0.0.1:6379> get k2
"333"
- 获取指定区间范围内的值
getrange/setrange
127.0.0.1:6379> get k1
"99123333"
127.0.0.1:6379> getrange k1 0 3
"9912"
127.0.0.1:6379> get k1
"99123333"
127.0.0.1:6379> setrange k1 0 3
(integer) 8
127.0.0.1:6379> get k1
"39123333"
应用场景
- 比如抖音无限点赞某个视频或者商品,点一下加一次
- 是否喜欢的文章
redis列表(list)
- List(列表)
- Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。它的底层实际是个
双端链表,最多可以包含2^23-1元素,每个列表超过40亿个元素。
简单说明:
一个双端链表的结构,容量是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈、队列、消息队列等场景。
left、right都可以插入添加:
如果键不存在,创建新的链表;
如果键已存在,新增内容;
如果值全移除,对应的键也就消失了。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差
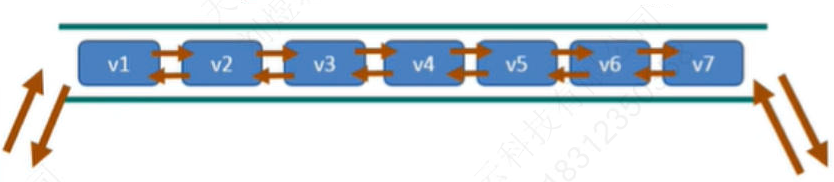
案例:
- lpush/rpush/lrange
127.0.0.1:6379> lpush list1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> rpush list2 11 22 33 44 55
(integer) 5
127.0.0.1:6379> type list1
list
127.0.0.1:6379> type list2
list
127.0.0.1:6379> lrange list1 0 -1
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
127.0.0.1:6379> lrange list2 0 -1
1) "11"
2) "22"
3) "33"
4) "44"
5) "55"
- lpop/rpop
127.0.0.1:6379> lrange list1 0 -1
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
127.0.0.1:6379> lpop list1
"5"
127.0.0.1:6379> lrange list1 0 -1
1) "4"
2) "3"
3) "2"
4) "1"
127.0.0.1:6379> rpop list1
"1"
127.0.0.1:6379> lrange list1 0 -1
1) "4"
2) "3"
3) "2"
- lindex 按照索引下标获得元素(从上到下)
127.0.0.1:6379> lrange list1 0 -1
1) "4"
2) "3"
3) "2"
127.0.0.1:6379> lindex list1 2
"2"
127.0.0.1:6379> lindex list1 1
"3"
- llen 获取列表中元素的个数
127.0.0.1:6379> lrange list1 0 -1
1) "4"
2) "3"
3) "2"
127.0.0.1:6379> llen list1
(integer) 3
- Lrem key 数字N给定值v1
解释(删除N个值等于v1的元素)
- 从left往right删除2个值等于v1的元素,返回的值为实际删除的数量。
- LREM list3 0 值,表示删除全部给定的值,零个就是全部值
127.0.0.1:6379> lpush list3 v1 v1 v1 v2 v3 v3 v4 v5
(integer) 8
127.0.0.1:6379> lrange list3 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v3"
5) "v2"
6) "v1"
7) "v1"
8) "v1"
127.0.0.1:6379> lrem list3 2 v1
(integer) 2
127.0.0.1:6379> lrange list3 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v3"
5) "v2"
6) "v1"
- ltrim key 开始index结束index,截取指定范围的值后再赋值给key
ltrim:截取指定索引区间的元素,格式是ltrim list的key 起始索引 结束索引
127.0.0.1:6379> lpush list4 0 1 2 3 4 5 6 7 8 9
(integer) 10
127.0.0.1:6379> lrange list4 0 -1
1) "9"
2) "8"
3) "7"
4) "6"
5) "5"
6) "4"
7) "3"
8) "2"
9) "1"
10) "0"
127.0.0.1:6379> ltrim list4 3 5
OK
127.0.0.1:6379> lrange list4 0 -1
1) "6"
2) "5"
3) "4"
- rpoplpush 源列表 目的列表
移除列表的最后一个元素,并将该元素添加到另一个列表并返回
127.0.0.1:6379> lrange list3 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v3"
5) "v2"
6) "v1"
127.0.0.1:6379> lrange list2 0 -1
1) "22"
2) "33"
3) "44"
127.0.0.1:6379> rpoplpush list2 list3
"44"
127.0.0.1:6379> lrange list2 0 -1
1) "22"
2) "33"
127.0.0.1:6379> lrange list3 0 -1
1) "44"
2) "v5"
3) "v4"
4) "v3"
5) "v3"
6) "v2"
7) "v1"
- lset key index value
127.0.0.1:6379> lrange list4 0 -1
1) "6"
2) "5"
127.0.0.1:6379> lset list4 1 c++
OK
127.0.0.1:6379> lrange list4 0 -1
1) "6"
2) "c++"
127.0.0.1:6379> lset list4 0 java
OK
127.0.0.1:6379> lrange list4 0 -1
1) "java"
2) "c++"
- linsert key before/after 已有值 插入的新值
127.0.0.1:6379> lrange list4 0 -1
1) "java"
2) "c++"
127.0.0.1:6379> linsert list4 before java python
(integer) 3
127.0.0.1:6379> lrange list4 0 -1
1) "python"
2) "java"
3) "c++"
127.0.0.1:6379> linsert list4 after c++ php
(integer) 4
127.0.0.1:6379> lrange list4 0 -1
1) "python"
2) "java"
3) "c++"
4) "php"
可用场景:
- 微信公众号订阅的消息
redis哈希表(Hash)
- Redis hash 是一个string类型的field(字段)和value(值)的映射表,hash特别适合用于存储对象。
- Redis中每个hash可以存储2^32-1 键值对(40多亿)
- KV模式不变,但V是一个键值对 Map<String,Map<Object,Object>>
常用:
- hset/hget/hmset/hmget/hgetall/hdel
127.0.0.1:6379> hset user:001 id 11 name z3 age 25
(integer) 3
127.0.0.1:6379> hget user:001 id
"11"
127.0.0.1:6379> hget user:001 name
"z3"
127.0.0.1:6379> hmset user:001 id 22 name li4 age 26
OK
127.0.0.1:6379> hmget user:001 id name age
1) "22"
2) "li4"
3) "26"
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "age"
6) "26"
127.0.0.1:6379> hdel user:001 age
(integer) 1
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
- hlen 获取某个Key内的全部数量
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
127.0.0.1:6379> hlen user:001
(integer) 2
- hexists key 在key里面的某个值的key
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
127.0.0.1:6379> hexists user:001 name
(integer) 1
127.0.0.1:6379> hexists user:001 score
(integer) 0
- hkeys/hvals
127.0.0.1:6379> hkeys user:001
1) "id"
2) "name"
127.0.0.1:6379> hvals user:001
1) "22"
2) "li4"
- hincrby/hincrbyfloat
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "score"
6) "91.5"
127.0.0.1:6379> hincrby user:001 age 1
(integer) 1
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "score"
6) "91.5"
7) "age"
8) "1"
127.0.0.1:6379> hincrby user:001 age 10
(integer) 11
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "score"
6) "91.5"
7) "age"
8) "11"
127.0.0.1:6379> hincrbyfloat user:001 score 5
"96.5"
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "score"
6) "96.5"
7) "age"
8) "11"
127.0.0.1:6379> hincrbyfloat user:001 score 0.5
"97"
127.0.0.1:6379> hgetall user:001
1) "id"
2) "22"
3) "name"
4) "li4"
5) "score"
6) "97"
7) "age"
8) "11"
- hsetnx
不存在赋值,存在了无效
127.0.0.1:6379> hsetnx hasd3 k1 44
(integer) 1
127.0.0.1:6379> hsetnx hasd3 k1 44
(integer) 0
127.0.0.1:6379> hget hasd3 k1
"44"
127.0.0.1:6379> hsetnx user:001 email xiaodunan@126.com
(integer) 1
127.0.0.1:6379> hsetnx user:001 email xiaodunan@126.com
(integer) 0
应用场景:
JD购物车早期,设计目前不再采用,当前小中厂可用
redis集合(set)
单值多value,且无重复
- set (集合)
- Redis的Set是String类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是Intest或者hashtable。
- Redis中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 集合中最大的成员数为2^32-1(每个集合可存储40多亿个成员)
案例:
- SADD key member [member ...] 添加元素
127.0.0.1:6379> sadd set1 1 1 1 2 2 2 3 4 5
(integer) 5
- SMEMBERS key 遍历集合中的所有元素
127.0.0.1:6379> smembers set1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
- SISMEMBER key member 判断元素是否在集合中
127.0.0.1:6379> sismember set1 x
(integer) 0
127.0.0.1:6379> sismember set1 1
(integer) 1
127.0.0.1:6379> sismember set1 5
(integer) 1
- SREM key member [member ...] 删除元素
127.0.0.1:6379> srem set1 5
(integer) 1
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
- scard 获取集合里面的元素个数
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> scard set1
(integer) 4
- SRANDMEMBER key [数字]
从集合中随机展现设置的数字个数元素,元素不删除
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> SRANDMEMBER set1
"1"
127.0.0.1:6379> SRANDMEMBER set1
"4"
127.0.0.1:6379> SRANDMEMBER set1
"2"
127.0.0.1:6379> SRANDMEMBER set1
"4"
- SPOP key [数字]
从集合中随机弹出一个元素,出一个删一个
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> spop set1
"3"
127.0.0.1:6379> spop set1
"2"
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "4"
- smove key1 key2 在key1里已存在的某个值
将key1里已存在的某个值赋给key2
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "4"
127.0.0.1:6379> sadd set2 a b c
(integer) 3
127.0.0.1:6379> smove set1 set2 4
(integer) 1
127.0.0.1:6379> SMEMBERS set1
1) "1"
127.0.0.1:6379> SMEMBERS set2
1) "c"
2) "a"
3) "4"
4) "b"
集合运算
背景:A、B两个集合,A{a,b,c,1,2},B{1,2,3,a,x}
- 集合的差集运算 A-B
属于A但不属于B的元素构成的集合
SDIFF key [key ...]
127.0.0.1:6379> SADD set1 a b c 1 2
(integer) 5
127.0.0.1:6379> SADD set2 1 2 3 a x
(integer) 5
127.0.0.1:6379> SDIFF set1 set2
1) "c"
2) "b"
127.0.0.1:6379> SDIFF set2 set1
1) "x"
2) "3"
- 集合的并集运算 A ∪ B
属于A或者属于B的元素合并后的集合
SUNINO key [key ...]
127.0.0.1:6379> SMEMBERS set1
1) "c"
2) "2"
3) "a"
4) "b"
5) "1"
127.0.0.1:6379> SMEMBERS set2
1) "2"
2) "3"
3) "a"
4) "x"
5) "1"
127.0.0.1:6379> SUNION set1 set2
1) "c"
2) "2"
3) "3"
4) "x"
5) "a"
6) "b"
7) "1"
- 集合的交集运算 A ∩ B
属于A同时也属于B的共同拥有的元素构成的集合
SINTER key [key ...]
127.0.0.1:6379> SMEMBERS set1
1) "c"
2) "2"
3) "a"
4) "b"
5) "1"
127.0.0.1:6379> SMEMBERS set2
1) "2"
2) "3"
3) "a"
4) "x"
5) "1"
127.0.0.1:6379> SINTER set1 set2
1) "2"
2) "a"
3) "1"
SINTERCARD numkeys key [key ...] [LIMIT limit]
redis 7 新命令
它不返回结果集,而只返回结果的基数。返回由所有给定集合的交集产生的集合的基数。
127.0.0.1:6379> SINTER set1 set2
1) "2"
2) "a"
3) "1"
127.0.0.1:6379> SINTERCARD 2 set1 set2
(integer) 3
127.0.0.1:6379> SINTERCARD 2 set1 set2 limit 1
(integer) 1
127.0.0.1:6379> SINTERCARD 2 set1 set2 limit 2
(integer) 2
127.0.0.1:6379> SINTERCARD 2 set1 set2 limit 3
(integer) 3
127.0.0.1:6379> SINTERCARD 2 set1 set2 limit 4
(integer) 3
应用场景
- 微信抽奖小程序
- 微信朋友圈点赞查看同赞朋友
- QQ内推可能认识的人
redis有序集合(ZSet)
- ZSet(sorted set:有序集合)
- Redis zset 和 set 一样也是String类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数,Redis正是通过分数来为集合中的成员进行从小到大的排序
- zset的成员是唯一的,但分数(score)却可以重复
- zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为2^32-1。
在set基础上,每个val值前加一个score分数值,之前set是k1 v1 v2 v3,现在zset是k1 score1 v1 score2 v2。
案例
向有序集合中加入一个元素和该元素的分数
- ZADD key score member [score member ...]
添加元素
127.0.0.1:6379> ZADD zset1 60 v1 70 v2 80 v3 90 v4 100 v5
(integer) 5
- ZRANGE key start stop [WITHSCORES]
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v1"
2) "v2"
3) "v3"
4) "v4"
5) "v5"
127.0.0.1:6379> ZRANGE zset1 0 -1 withscores
1) "v1"
2) "60"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
9) "v5"
10) "100"
- zrevrange
127.0.0.1:6379> ZREVRANGE zset1 0 -1 withscores
1) "v5"
2) "100"
3) "v4"
4) "90"
5) "v3"
6) "80"
7) "v2"
8) "70"
9) "v1"
10) "60"
- zrangebyscore key min max [withscores] [limit offset count]
获取指定分数范围的元素
127.0.0.1:6379> ZRANGEBYSCORE zset1 60 90
1) "v1"
2) "v2"
3) "v3"
4) "v4"
127.0.0.1:6379> ZRANGEBYSCORE zset1 60 90 withscores
1) "v1"
2) "60"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
( 不包含
127.0.0.1:6379> ZRANGEBYSCORE zset1 (60 90 withscores
1) "v2"
2) "70"
3) "v3"
4) "80"
5) "v4"
6) "90"
limit 作用是返回限制
limit开始下标步 多少步
127.0.0.1:6379> ZRANGEBYSCORE zset1 (60 90 withscores limit 0 1
1) "v2"
2) "70"
127.0.0.1:6379> ZRANGEBYSCORE zset1 (60 90 withscores limit 0 2
1) "v2"
2) "70"
3) "v3"
4) "80"
- zscore key member
获取元素的分数
127.0.0.1:6379> zscore zset1 v5
"100"
127.0.0.1:6379> zscore zset1 v4
"90"
- zcard key
获取集合中元素的数量
127.0.0.1:6379> zcard zset1
(integer) 5
- zrem key 某score下对应的value值,作用是删除元素
127.0.0.1:6379> zrem zset1 v5
(integer) 1
127.0.0.1:6379> zrem zset1 v5
(integer) 0
127.0.0.1:6379> ZRANGE zset1 0 -1 withscores
1) "v1"
2) "60"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
- zincrby key increment member
增加某个元素的分数
127.0.0.1:6379> ZINCRBY zset1 3 v1
"63"
127.0.0.1:6379> ZRANGE zset1 0 -1 withscores
1) "v1"
2) "63"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
- zcount key min max
获得指定分数范围内的元素个数
127.0.0.1:6379> zcount zset1 60 100
(integer) 4
127.0.0.1:6379> zcount zset1 65 70
(integer) 1
- ZMPOP
从键名列表中的第一个非空排序集中弹出一个或多个元素,它们是成员分数对
127.0.0.1:6379> ZMPOP 1 zset1 min count 1
1) "zset1"
2) 1) 1) "v1"
2) "63"
127.0.0.1:6379> zrange zset1 0 -1 withscores
1) "v2"
2) "70"
3) "v3"
4) "80"
5) "v4"
6) "90"
- zrank key values 值
作用是获得下标值
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v2"
2) "v3"
3) "v4"
127.0.0.1:6379> zrank zset1 v2
(integer) 0
- zrevrank key values值
作用是逆序获得下标值
127.0.0.1:6379> ZREVRANK zset1 v2
(integer) 2
应用场景:
根据商品销售对商品进行排序显示
redis基数统计(HyperLogLog)
- HyperLogLog是用来做
基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。 - 在Redis里面每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
- 但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
命令即描述:
- PFADD key element {element...}
添加指定元素到HyperLogLog中
127.0.0.1:6379> pfadd hll01 1 3 4 5 7 9
(integer) 1
127.0.0.1:6379> pfadd hll02 1 4 4 4 6 8 9
(integer) 1
- PFCOUNT key {key...}
返回给定HyperLogLog的基数估算值
127.0.0.1:6379> pfcount hll01
(integer) 6
127.0.0.1:6379> pfcount hll02
(integer) 5
- PFMERGE destkey sourcekey {sourcekey...}
将多个HyperLogLog合并为一个HyperLogLog
127.0.0.1:6379> PFMERGE hllresult hll01 hll02
OK
127.0.0.1:6379> pfcount hllresult
(integer) 8
应用场景:
天猫网站首页亿级UV的Redis统计方案
Redis位图(bitmap)
- Bit arrays(or simply blitmaps,我们可以称之为位图)
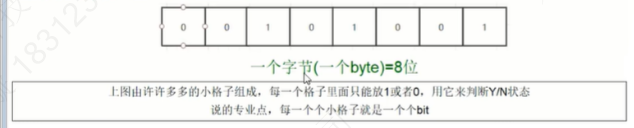
由0和1状态表现的二进制位的bit数组
需求:
用户是否登录过Y、N,比如京东每日签到送京豆
电影、广告是否被点击播放过
钉钉打卡上下班,签到统计
基本命令:
| 命令 | 作用 | 时间复杂度 |
|---|---|---|
| setbit key offset val | 给指定key的值的第offset赋值val | O(1) |
| getbit key offset | 获取指定key的第offset位 | O(1) |
| bitcount key start end | 返回指定key中[start,end]中为1的数量 | O(n) |
| bitop operation destkey key | 对不同的二进制存储数据进行位运算(AND、OR、NOT、XOR) | O(n) |
- setbit
setbit key offset value
setbit 键 偏移位 只能0或1
Bitmap的偏移量是从零开始算的
127.0.0.1:6379> setbit k1 1 1
(integer) 0
127.0.0.1:6379> setbit k1 2 1
(integer) 0
127.0.0.1:6379> setbit k1 3 1
(integer) 0
127.0.0.1:6379> setbit k1 3 7
(error) ERR bit is not an integer or out of range
127.0.0.1:6379> type k1
string
127.0.0.1:6379> setbit k1 3 0
(integer) 1
- getbit
127.0.0.1:6379> getbit k1 1
(integer) 1
127.0.0.1:6379> getbit k1 2
(integer) 1
127.0.0.1:6379> getbit k1 3
(integer) 0
127.0.0.1:6379> getbit k1 4
(integer) 0
- strlen
统计字节数占用多少,不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一 byte再扩容
127.0.0.1:6379> strlen k1
(integer) 1
127.0.0.1:6379> setbit k1 8 1
(integer) 0
127.0.0.1:6379> strlen k1
(integer) 2
127.0.0.1:6379> setbit k1 16 1
(integer) 0
127.0.0.1:6379> strlen k1
(integer) 3
- bitcount
全部键里面含有1的有多少个
127.0.0.1:6379> setbit uid:login123 1 1
(integer) 0
127.0.0.1:6379> setbit uid:login123 2 1
(integer) 0
127.0.0.1:6379> setbit uid:login123 3 1
(integer) 0
127.0.0.1:6379> bitcount uid:login123
(integer) 3
- bitop
127.0.0.1:6379> setbit 20250101 0 1
(integer) 0
127.0.0.1:6379> setbit 20250101 1 1
(integer) 0
127.0.0.1:6379> setbit 20250101 2 1
(integer) 0
127.0.0.1:6379> setbit 20250101 3 1
(integer) 0
127.0.0.1:6379> getbit 20250101 0
(integer) 1
127.0.0.1:6379> setbit 20250102 0 1
(integer) 0
127.0.0.1:6379> setbit 20250102 2 1
(integer) 0
127.0.0.1:6379> bitcount 20250101
(integer) 4
127.0.0.1:6379> bitcount 20250102
(integer) 2
127.0.0.1:6379> bitop and c1 20250101 20250102
(integer) 1
127.0.0.1:6379> bitcount c1
(integer) 2
应用场景:
一年365天,全年天天登录占用多少字节
redis地理空间(GEO)
- Redis GEO主要用于存储地理位置信息,并对存储的信息进行操作,包括:
- 添加地理位置的坐标
- 获取地理位置的坐标
- 计算两个位置之间的距离
- 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
- 命令
- GEOADD:多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的key中
- GEOPOS:从键里面返回所有给定位置元素的位置(经度和纬度)
- GEODIST:返回两个给定位置之间的距离
- GEORADIUS:以给定的经纬度为中心,返回与中心的距离不超过给定最大距离的所有位置元素
- GEORADIUSBYMEMBER:跟GEORADIUS类似
- GEOHASH:返回一个或多个位置元素的Geohash表示
- 命令实操
(1)GEOADD添加经纬度坐标
- geoadd 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的key中
- geoadd 语法格式如下:
GEOADD key longitude latitude member [longitude latitude member ...]
127.0.0.1:6379> GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
(integer) 3
127.0.0.1:6379> type city
zset
127.0.0.1:6379> zrange city 0 -1
1) "\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8"
2) "\xe6\x95\x85\xe5\xae\xab"
3) "\xe9\x95\xbf\xe5\x9f\x8e"
中文乱码解决方法:加上--raw参数
[ops@master2 ~]$ redis-cli -a 111111 --raw
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> zrange city 0 -1
天安门
故宫
长城
(2)GEOPOS返回经纬度
- geopos 用于从给定的key里返回所有指定名称(member)的位置(经度和纬度),不存在的返回null
- geopos 语法格式如下:
geopos key member [member ...]
127.0.0.1:6379> geopos city 天安门 故宫
116.40396326780319214
39.91511970338637383
116.40341609716415405
39.92409008156928252
(3)GEOHASH返回坐标的geohash表示
- Redis GEO 使用 geohash来保存地理位置的坐标
- geohash 用于获取一个或多个位置元素的geohash值
- geohash 语法格式如下
GEOHASH key member [member ...]
127.0.0.1:6379> GEOHASH city 天安门 长城 故宫
wx4g0f6f2v0
wx4t85y1kt0
wx4g0gfqsj0
(4)GEODIST两个位置之间距离
- GEODIST 用于返回两个给定位置之间的距离
- GEODIST 语法格式如下
GEODIST key member1 member2 [m|km|ft|mi]
127.0.0.1:6379> geodist city 天安门 长城 km
59.3390
127.0.0.1:6379> geodist city 天安门 长城 m
59338.9814
127.0.0.1:6379> geodist city 天安门 长城 ft
194681.6976
127.0.0.1:6379> geodist city 天安门 长城 mi
36.8716
后面参数是距离单位,m 米,km 千米,ft 英尺,mi 英里
(5)GEORADIUS
- GEORADIUS 以给定的经纬度为中心,返回键包含的位置元素当中,与中心的距离不超过给定最大距离的所有位置元素
WITHDIST:在返回位置元素的同时,将位置元素与中心之间的距离也一并返回。距离的单位和用户给定的范围单位保持一致
WITHCOORD:将位置元素的经度和纬度也一并返回
WITHHASH:以52位有符号整数的形式,返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试,实际中的作用并不大。
COUNT:限定返回的记录数
127.0.0.1:6379> georadius city 116.418017 39.914402 10 km withdist withcoord count 10
天安门
1.2016
116.40396326780319214
39.91511970338637383
故宫
1.6470
116.40341609716415405
39.92409008156928252
(6)GEORADIUSBYMEMBER
127.0.0.1:6379> GEORADIUSBYMEMBER city 天安门 10 km withdist withcoord count 10 withhash
天安门
0.0000
4069885555089531
116.40396326780319214
39.91511970338637383
故宫
0.9988
4069885568908290
116.40341609716415405
39.92409008156928252
redis位域(bitfield)
- 通过bitfield命令可以一次性操作多个
比特位域(指的是连续的多个比特位),它会执行一系列操作并返货一个响应数组,这个数组中的元素对应参数列表中的响应操作的执行结果。 - 说白了就是看通过bitfield命令我们可以一次性对多个比特位域进行操作。
BITFIELD命令可以将一个Redis字符串看作是一个由二进制位组成的数组,并对这个数组中任意偏移进行访问。可以使用该命令对一个有符号的5位整型数的第1234位设置指定值,也可以对一个31位无符号整型数的第4567位进行取值。类似地,本命令可以对指定的整数进行自增和自减操作,可配置的上溢和下溢处理操作。
BITFIELD命令可以在一次调用中同时对多个位范围进行操作;它接受一系列待执行的操作作为参数,并返回一个数组,数组中的每个元素就是对应操作的执行结果。
例如,对位于5位有符号整数的偏移量100执行自增操作,并获取位于偏移量0上的4位长无符号整数;
BITIFILD mykey INCRBY i5 100 1 GET u4 0
用途:
BITFIELD命令的作用在于它能够将很小的整数存储到一个长度较大的位图中,又或者将一个非常庞大的键分割为多个较小的键来进行存储,从而非常高效地使用内存,使得Redis能够得到更多不同的应用——特别是在实时分析领域;BITDIELD能够以指定的方式对计算溢出进行控制的能力,使得它可以被应用于这一领域。
基本语法
下面是已支持的命令列表:
- GET
-返回指定的位域 - SETM
-设置指定位域的值并返回它的原值 - INCRBY
-自增或自减(如果increment为负数)指定位域的值并返回它的新值。
还有一个命令通过设置溢出行为来改变调用INCRBY指令的后续操作:
- OVERFLOW [WRAP|SAT|FAIL]
当需要一个整型时,有符号整型需在位数前加i,无符号在位数前加u。例如,u8是一个8位的无符号整型,i16是一个16位的有符号整型。
基本命令代码实操
- BITFIELD key [GET type offset]
27.0.0.1:6379> set fieldkey hello
OK
127.0.0.1:6379> get fieldkey
"hello"
127.0.0.1:6379> type fieldkey
string
127.0.0.1:6379> BITFIELD fieldkey get i8 0
1) (integer) 104
127.0.0.1:6379> BITFIELD fieldkey get i8 8
1) (integer) 101
- BOTFIELD key [SET type offset value]
127.0.0.1:6379> BITFIELD fieldkey set i8 8 120 #从第9个位开始,将接下来8个位用有符号数120(字母x)替换
1) (integer) 101
127.0.0.1:6379> get fieldkey
"hxllo"
- BITFIELD key [INCRBY type offset increment]
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1 #从第3个位开始,对接下来的4位无符号数+1
1) (integer) 11
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1
1) (integer) 12
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1
1) (integer) 13
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1
1) (integer) 14
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1
1) (integer) 15
127.0.0.1:6379> BITFIELD fieldkey incrby u4 2 1 #默认overflow为wrap,即循环溢出
1) (integer) 0
- 溢出控制OVERFLOW [WRAP|SAT|FAIL]
127.0.0.1:6379> set fieldkey hello
OK
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1 # 从第3个位开始,对接下来的4位无符号数+1
1) (integer) 11
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1
1) (integer) 12
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1
1) (integer)
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1
1) (integer) 14
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1
1) (integer) 15
127.0.0.1:6379> bitfield fieldkey incrby u4 2 1 # 默认overflow为wrap,即循环溢出
1) (integer) 0
(1)WRAP:使用回绕(wrap around)方法处理有符号整数和无符号整数的溢出情况
127.0.0.1:6379> set test a
OK
127.0.0.1:6379> bitfield test get i8 0 #a对应的ascll码值97
1) (integer) 97
127.0.0.1:6379> bitfield test set i8 0 127 #i8表示有符号8位二进制,范围(-128-127)
1) (integer) 97
127.0.0.1:6379> bitfield test get i8 0
1) (integer) 127
127.0.0.1:6379> bitfield test set i8 0 138 #默认overflow为wrap,即循环溢出
1) (integer) 127
127.0.0.1:6379> bitfield test get i8 0
1) (integer) -118
(2)SAT:使用饱和计算(saturation arithmetic)方法处理溢出,下溢计算的结果为最小的整数值,而上溢计算的结果为最大的整数值
127.0.0.1:6379> bitfield test get i8 0
1) (integer) -118
127.0.0.1:6379> bitfield test overflow sat set i8 0 128
1) (integer) -118
127.0.0.1:6379> bitfield test get i8 0
1) (integer) 127
(3)FAIL:命令将拒绝执行那些会导致上溢或者下溢情况出现的计算,并向用户返回空值表示计算未被执行
127.0.0.1:6379> bitfield test get i8 0
1) (integer) 127
127.0.0.1:6379> BITFIELD test overflow fail set i8 0 827
1) (nil)
redis流(Stream)
- Redis Stream 是Redis 5.0 版本新增加的数据结构
- Redis Stream 主要用于消息队列(MQ。Message Queue),Redis本身是有一个Redis发布订阅(pub/sub)来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃。
- 简单来说发布订阅(pub/sub)可以分发消息,但无法记录历史消息。
- 而Redis Stream提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
底层结构和原理说明
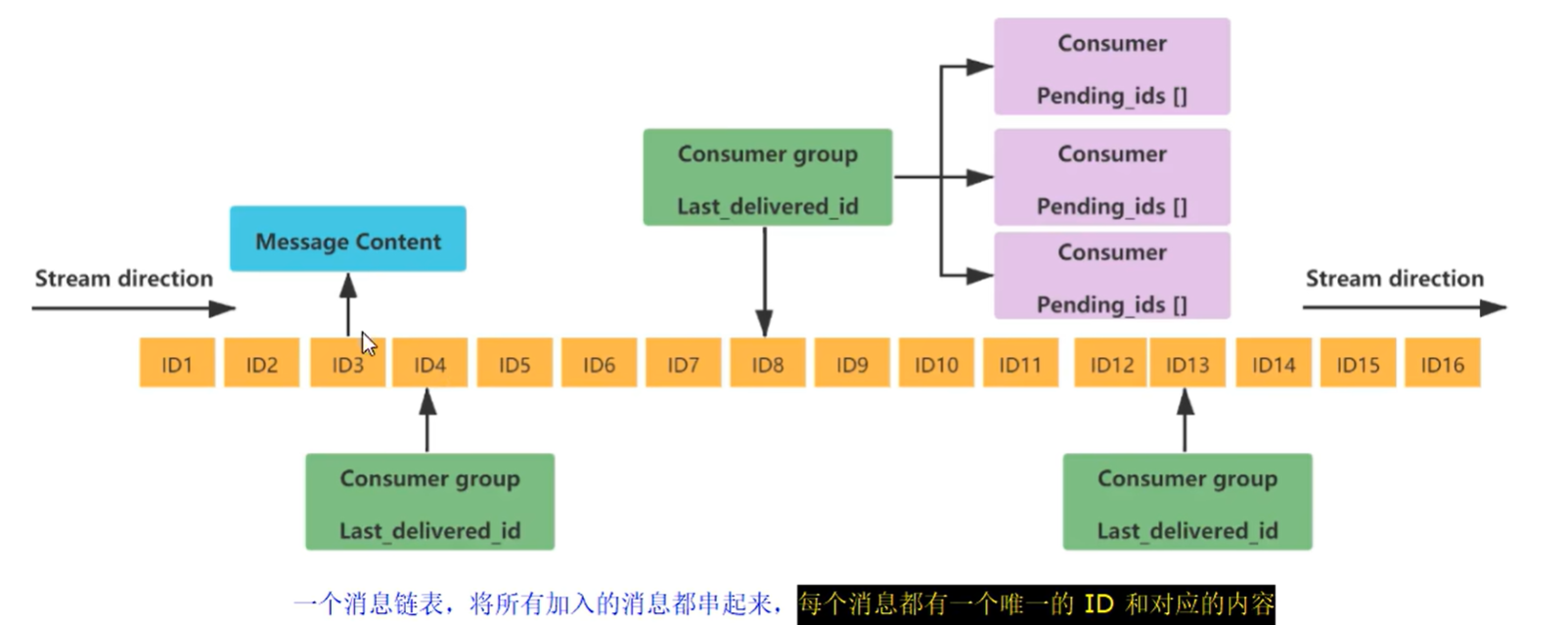
| 序号 | 组件 | 说明 |
|---|---|---|
| 1 | Message Content | 消息内容 |
| 2 | Consumer group | 消费组,通过XGROUP CREATE命令创建,同一个消费组可以有多个消费者 |
| 3 | Last_delivered_id | 游标,每个消费组会有个游标last_delivered_id,任意一个消费者读取了消息都会使游标last_delivered_id往前移动 |
| 4 | Consumer | 消费者,消费组中的消费者 |
| 5 | Pending_ids | 消费者会有一个状态变量,用于记录被当前已读取但未ack的消息id,如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack它就开始减少。这个pending_ids变量在Redis官方被称之为PEL(Pending Entries List),记录了当前已经被客户端读取的消息,但是还没有ack(Acknowledge character:确认字符),它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理 |
基本命令理论简介
- 队列相关指令
| 指令名称 | 指令作用 |
|---|---|
| XADD | 添加消息到队列末尾 |
| XTRIM | 限制Stream的长度,如果已经超长会进行截取 |
| XDEL | 删除消息 |
| XLEN | 获取Stream中的消息长度 |
| XRANGE | 获取消息列表(可以指定范围),忽略删除的消息 |
| XREVRANGE | 和XRANGE相比区别在于反向获取,ID从大到小 |
| XREAD | 获取消息(阻塞/非阻塞),返回大于指定ID的消息 |
- 消费组相关指令
| 指令名称 | 指令作用 |
|---|---|
| XGROUP CREATE | 创建消费者组 |
| XREADGROUP GROUP | 读取消费者中的消息 |
| XACK | ack消息,消息被标记为“已处理” |
| XGROUP SETID | 设置消费者组最后递送消息的ID |
| XGROUP DELCONSUMER | 删除消费者组 |
| XPENDING | 打印待处理消息的详细信息 |
| XCLAIM | 转移消息的归属权(长期未被处理/无法处理的消息,转交给其他消费者组进行处理) |
| XINFO | 打印Stream\Consumer\Group的详细信息 |
| XINFO GROUPS | 打印消费者组的详细信息 |
| XINFO STREAM | 打印Stream的详细信息 |
- 四个特殊符号
| 符号 | 作用 |
|---|---|
| -+ | 最小和最大可能出现的id |
| $ | $表示只消费新的消息,当前流中最大的id,可用于将要到来的信息 |
| > | 用于XREADGROUP命令,表示迄今还没有发送给组中使用者的信息,会更新消费者组的最后ID |
| * | 用于XADD命令中,让系统自动生成id |
Redis流实例演示
一、 队列相关指令
1.XADD
XADD 用于向Stream 队列中添加消息,如果指定的Stream队列不存在,则该命令执行时会新建一个Stream队列,* 表示服务器自动生成MessageID(类似mysql里面主键auto_increment),后面顺序跟着一堆业务key/value

信息条目指的是序列号,在相同的毫秒下序列号从0开始递增,序列号是64位长度,理论上在同一毫秒内生成的数据量无法到达这个级别,因此不用担心序列号会不够用。millisecondsTime指的是Redis节点服务器的本地时间,如果存在当前的毫秒时间戳比以前已经存在的数据的时间戳小的话(本地时间钟后跳),那么系统将会采用以前相同的毫秒创建新的ID,也即redis在增加信息条目时会检查当前id与上一条目的id,自动纠正错误的情况,一定要保证后面的id比前面大,一个流中信息条目的ID必须是单调增的,这是流的基础。。
客户端显示传入规则:Redis对于ID有强制要求,格式必须是时间戳-自增ID这样的方式,且后续ID不能小于前一个ID。
Stream的消息内容,也就是图中的Message Content它的结构类似Hash结构,以key-value的形式存在。
127.0.0.1:6379> XADD mystream * id 11 cname z3
"1738572049369-0"
127.0.0.1:6379> XADD mystream * id 12 cname li4
"1738572069986-0"
127.0.0.1:6379> XADD mystream * k1 v1 k2 v2 k3 v3
"1738572085771-0"
127.0.0.1:6379> XADD mystream 1738572085771-0 k1 v1 k2 v2 k3 v3
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
127.0.0.1:6379> type mystream
stream
2.XRANGE
用于获取消息列表(可以指定范围),忽略删除的消息
start 表示开始值,-代表最小值
end 表示结束值,+代表最大值
count 表示最多获取多少个值
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1738572049369-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
2) 1) "1738572069986-0"
2) 1) "id"
2) "12"
3) "cname"
4) "li4"
3) 1) "1738572085771-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
127.0.0.1:6379> XRANGE mystream - + count 1
1) 1) "1738572049369-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
3.XREVRANGE
127.0.0.1:6379> XREVRANGE mystream + -
1) 1) "1738572085771-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
2) 1) "1738572069986-0"
2) 1) "id"
2) "12"
3) "cname"
4) "li4"
3) 1) "1738572049369-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
4.XDEL
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1738572049369-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
2) 1) "1738572069986-0"
2) 1) "id"
2) "12"
3) "cname"
4) "li4"
3) 1) "1738572085771-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
127.0.0.1:6379> XDEL mystream 1738572085771-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1738572049369-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
2) 1) "1738572069986-0"
2) 1) "id"
2) "12"
3) "cname"
4) "li4"
5.XLEN
用于获取stream队列的消息的长度
127.0.0.1:6379> XLEN mystream
(integer) 2
6.XTRIM
用于对Stream的长度进行截取,如超长会进行截取
- MAXLEN:允许的最大长度,对流进行修剪限制长度
127.0.0.1:6379> XRANGE stream - +
1) 1) "1738574125302-0"
2) 1) "k1"
2) "v1"
2) 1) "1738574129216-0"
2) 1) "k2"
2) "v2"
3) 1) "1738574155552-0"
2) 1) "k3"
2) "v3"
4) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> XTRIM stream maxlen 2
(integer) 2
127.0.0.1:6379> xrange stream - +
1) 1) "1738574155552-0"
2) 1) "k3"
2) "v3"
2) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
- MINID:允许的最小id,从某个id值开始比该id值小的将会被抛弃
127.0.0.1:6379> xrange stream - +
1) 1) "1738574155552-0"
2) 1) "k3"
2) "v3"
2) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> XTRIM stream minid 1738574155552-0
(integer) 0
127.0.0.1:6379> xrange stream - +
1) 1) "1738574155552-0"
2) 1) "k3"
2) "v3"
2) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> XTRIM stream minid 1738574160371-0
(integer) 1
127.0.0.1:6379> xrange stream - +
1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
7.XREAD
用于获取消息(阻塞/非阻塞),只会返回大于指定ID的消息
- 非阻塞
$代表特殊ID,表示以当前Stream已经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil
0-0代表从最小的ID开始获取Stream中的消息,当不指定count,将会返回Stream中的所有消息,注意也可以使用0(00/000也都是可以的...)
127.0.0.1:6379> XRANGE stream - +
1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
2) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
3) 1) "1738574909601-0"
2) 1) "k2"
2) "v2"
4) 1) "1738574913087-0"
2) 1) "k3"
2) "v3"
5) 1) "1738574917236-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> XREAD count 2 streams stream $
(nil)
127.0.0.1:6379> XREAD count 2 streams stream 0-0
1) 1) "stream"
2) 1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
2) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
127.0.0.1:6379> XREAD count 2 streams stream 000
1) 1) "stream"
2) 1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
2) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
- 阻塞
开启两个客户端,客户端1为消费者,客户端2为生产者
(1)消费者读取消息
127.0.0.1:6379> XREAD count 1 block 0 streams stream $
(2)生产者添加消息
127.0.0.1:6379> xadd stream * k5 v5
"1738575271521-0"
(3)返回客户端1查看消息
127.0.0.1:6379> XREAD count 1 block 0 streams stream $
1) 1) "stream"
2) 1) 1) "1738575271521-0"
2) 1) "k5"
2) "v5"
(47.00s)
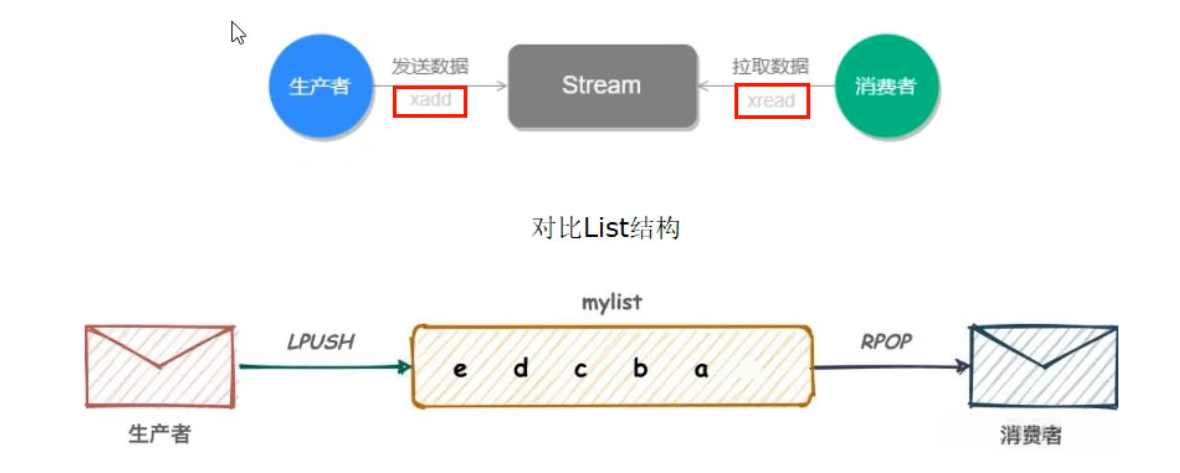
总结:Stream的基础方法,使用XADD存入消息和xread循环阻塞读取消息的方式可以实现简易版的消息队列,交互流程如上。
二、 消费组相关指令
1. XGROUP CREATE
用于创建消费者组
127.0.0.1:6379> XGROUP CREATE stream groupA $
OK
127.0.0.1:6379> XGROUP CREATE stream groupB 0
OK
127.0.0.1:6379> XGROUP CREATE stream groupC 0
OK
$表示从Stream尾部开始消费
0表示从Stream头部开始消费
创建消费者组的时候必须指定ID,ID为0表示从头开始消费,为$表示只消费新的消息,队尾新来
2. XREADGROUP GROUP
">",表示从第一条尚未被消费的消息开始读取
消费组groupA内的消费者consumer1从mystream消息队列中读取所有消息
127.0.0.1:6379> XREADGROUP group groupB consumer1 streams stream >
1) 1) "stream"
2) 1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
2) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
3) 1) "1738574909601-0"
2) 1) "k2"
2) "v2"
4) 1) "1738574913087-0"
2) 1) "k3"
2) "v3"
5) 1) "1738574917236-0"
2) 1) "k4"
2) "v4"
6) 1) "1738575271521-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> XREADGROUP group groupB consumer2 streams stream >
(nil)
Stream中的消息一旦被消费者组里的一个消费者读取了,就不能再被消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息。刚才的XREADGROUP命令再执行一次,此时读到的就是空值。但是,不同消费组的消费者可以消费同一条消息。
127.0.0.1:6379> XREADGROUP group groupC consumer1 streams stream >
1) 1) "stream"
2) 1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
2) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
3) 1) "1738574909601-0"
2) 1) "k2"
2) "v2"
4) 1) "1738574913087-0"
2) 1) "k3"
2) "v3"
5) 1) "1738574917236-0"
2) 1) "k4"
2) "v4"
6) 1) "1738575271521-0"
2) 1) "k5"
2) "v5"
消费者的目的: 让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部门消息,从而实现消息读取负载在多个消费者间是均衡分布的。
127.0.0.1:6379> XGROUP CREATE stream groupD 0-0
OK
127.0.0.1:6379> XREADGROUP group groupD consumer1 count 1 streams stream >
1) 1) "stream"
2) 1) 1) "1738574160371-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> XREADGROUP group groupD consumer2 count 2 streams stream >
1) 1) "stream"
2) 1) 1) "1738574904141-0"
2) 1) "k1"
2) "v1"
2) 1) "1738574909601-0"
2) 1) "k2"
2) "v2"
127.0.0.1:6379> XREADGROUP group groupD consumer3 count 3 streams stream >
1) 1) "stream"
2) 1) 1) "1738574913087-0"
2) 1) "k3"
2) "v3"
2) 1) "1738574917236-0"
2) 1) "k4"
2) "v4"
3) 1) "1738575271521-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> XREADGROUP group groupD consumer4 count 4 streams stream >
(nil)
重点问题:
- 基于Stream实现的消息队列,如何保证消费者在发生故障或者宕机再次重启后,仍然可以读取未处理完的消息?
- Streams会自动使用内部队列(也称为PENDING List)留存消费组里每个消费者读取的消息保底措施,直到消费者使用XACK命令通知Streams“消息已经处理完成”。
- 消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行XACK命令确认消息已经被消费完成。
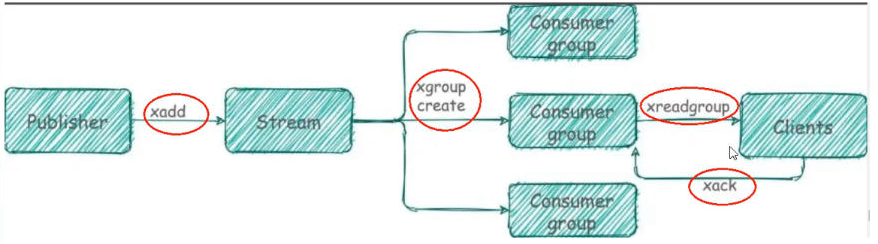
3. XPENDING
查询每个消费组内所有消费者[已读取、但尚未确认]的消息
查看某个消费者具体读取了哪些数据
127.0.0.1:6379> XPENDING stream groupB
1) (integer) 6
2) "1738574160371-0" #所有消费者读取的消息最小ID
3) "1738575271521-0" #所有消费者读取的消息最大ID
4) 1) 1) "consumer1" #一口气读了6条
2) "6"
127.0.0.1:6379> XPENDING stream groupD
1) (integer) 6
2) "1738574160371-0"
3) "1738575271521-0"
4) 1) 1) "consumer1" #3个消费者分别读取了几条信息
2) "1"
2) 1) "consumer2"
2) "2"
3) 1) "consumer3"
2) "3"
4. XACK
向消息队列确认消息处理已完成
127.0.0.1:6379> XPENDING stream groupD - + 10 consumer2
1) 1) "1738574904141-0"
2) "consumer2"
3) (integer) 2835526
4) (integer) 1
2) 1) "1738574909601-0"
2) "consumer2"
3) (integer) 2835526
4) (integer) 1
127.0.0.1:6379> XACK stream groupD 1738574904141-0
(integer) 1
127.0.0.1:6379> XPENDING stream groupD - + 10 consumer2
1) 1) "1738574909601-0"
2) "consumer2"
3) (integer) 2860398
4) (integer) 1
127.0.0.1:6379> XACK stream groupD 1738574909601-0
(integer) 1
127.0.0.1:6379> XPENDING stream groupD - + 10 consumer2
(empty array)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY