

DataFrame中统计某几列中字符出现次数并比较
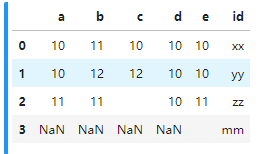
aa = pd.DataFrame({'id':['xx','yy','zz','mm'], 'a':['10','10','11',np.nan],'b':['11','12','11',np.nan],'c':['10','12','',np.nan],'d':['10','10','10',np.nan],'e':['10','10','11','']})
aa
def map_func1(x):
if (x['a'] == x['b'] == x['c'] == x['d'] == ''):
return 'www'
else:
li = list(x[['a','b','c','d']])
print(li)
set1 = set(li)
dict1 = {}
for item in set1:
dict1.update({item:li.count(item)})
print(dict1)
return max(dict1,key=dict1.get)
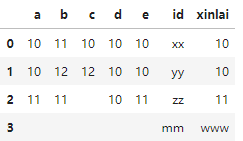
aa['xinlai'] = aa.apply(map_func1,axis=1) #axis控制按行还是按列
既然无论如何时间都会过去,为什么不选择做些有意义的事情呢
