大数据解实例决topn问题
做大数据开发经常遇上在众多数据中统计前几的问题,比如王者荣耀每个区的富豪排行榜(腾讯可以做个刺激消费,😄)
我们在众多数据中抽取了如下数据:
所在区,用户名,每次充值数。(a,role1,158)(a,role1,15)(c,role1,18)(b,role3,123)
如上数据可以自行添加多条的hdfs上,不在叙述。
拿到数据首先我们需要分析我们最终要的到的数据的格式,每个区的富豪排行榜,那么首先要把每个人在每个区一共充值多
少钱进行累加,再对各个其进行分区,最终排序。业务很简单,下面就为大家上干货
rdd = sc.textFile('/user/hadoop/datas.txt') rdd.take(10) rdd = rdd.map(lambda x:x.split(",")) rdd = rdd.map(lambda x:((x[0],x[1]),int(x[2]))) rdd=rdd.groupByKey() rdd=rdd.map(lambda x:((x[0],sum(list(x[1]))),'')) print(rdd.take(20)) def getPartition(key): s={'a':0,'b':1,'c':2,'d':3} return s.get(key[0][0]) def mysort(key): return key[1] rdd=rdd.repartitionAndSortWithinPartitions(numPartitions=4,partitionFunc=getPartition,ascending=False,keyfunc=mysort) def topN(it): def my(): for i in range(1,6): yield next(it) return my() rdd = rdd.mapPartitions(topN) rdd = rdd.map(lambda x:(x[0])) rdd.collect()
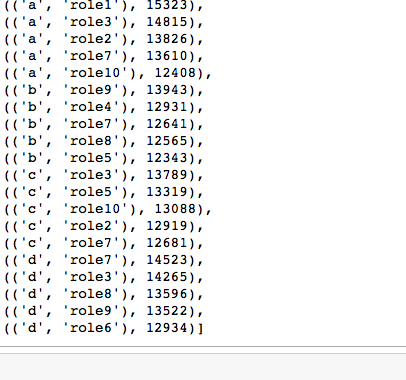
等到如下形式的结果,你就可以面试大数据了,目前也就是这些差不多的工作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号