重启yarn导致僵死资源不可用问题
今日在做节点可靠性测试的时候,错误重启了yarn整个服务,其hdfs等他组件正常,yarn过会自动僵死,导致整个平台资源调度问题,恢复步骤如下:
1.查看日志tail -f yarn-resourcemanger-192.168.1.233.log(不清楚你的日志在哪可以find / -name yarn)
2.登陆装有yarn的机器,查看rm1,rm2 的状态。我的rm1,rm2,都是standby,(rm是resourceManger,HA)
$ yarn rmadmin -getServiceState rm1 standby $ yarn rmadmin -getServiceState rm2 standby
(手动的切换准备命令了yarn rmadmin -transitionToStandby rm1)
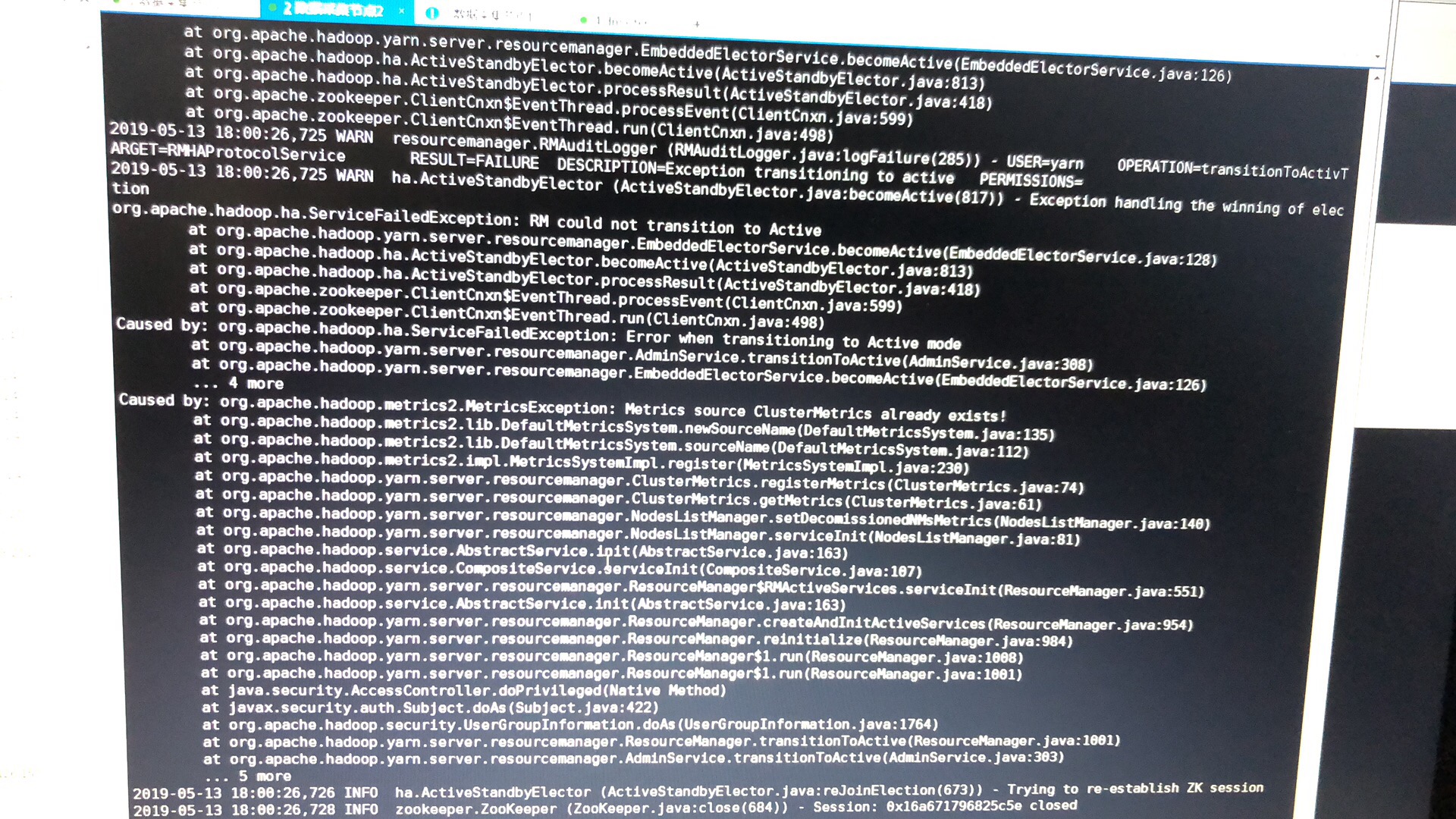
3.以上两个命令已经可以发现主rm没有起来,但重启后,依然会僵死。清空rm日志,重新启动rm后,分析日志会发现如下错误:
Caused by: org.apache.hadoop.metrics2.MetricsException: Hadoop:service=ResourceManager,name=RMNMInfo already exists!
Caused by: java.lang.IllegalArgumentException: No object name specified
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.registerDynamicMBean(DefaultMBeanServerInterceptor.java:949)
... 21 more
Metrics source ClusterMetrics already exists!
4.这时可以考虑是有个application加载不起来。
可以修改yarn-site.xml的yarn.resourcemanager.recovery.enabled = false。
若集群开启了Recovery功能,则ResourceManager重启过程中:
- Hive作业正常运行至结束
- YARN UI的作业信息一直保留存在
这里我们要改为false,后重启yarn。
5.等待yarn空闲时,连接zookeeper(在zk的bin目录下运行./zkCli.sh -server 127.0.0.1:2181)
登陆后查看该目录ls /rmstore/ZKRMStateRoot/RMAppRoot,
不为空则使用该命令rmr /rmstore/ZKRMStateRoot/RMAppRoot/* 删除目录文件
确定为空时,把yarn-site.xml的yarn.resourcemanager.recovery.enabled改回ture
6.重启yarn。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号