
MySQL存储过程
前言
在性能测试时,为模拟实际生产环境的数据量,又或者在业务中,为方便测试,需要预置一批数据使用。所以需要一些大批量造数据的手段,造数据的方法多种多样,本文是介绍的直接通过navicat终端,写存储过程语句批量造数据,这样的方法,最简单有效。先直接上一条,上手就能用的白板SQL。
DELIMITER $$ #定义一个分界符 DROP PROCEDURE IF EXISTS testInsert; #为了使SQL重复执行,所以写了这一句,如果存在即删除, CREATE PROCEDURE testInsert() #创建一个存储过程testInsert BEGIN #事务的开始 DECLARE i INT; #定义变量的数据类型为int set i = 0; #定义 变量i的初始值为0 WHILE i < 3 DO #此处采用的While循环,当上一步设置的i<3时,开始执行下方循环体,即:i=0,循环到i<3,一共会插入3条数据。所以需要通过这一步来控制具体需要循环的次数 INSERT INTO `库名`.`表名`(列名) VALUES (值);#这儿写SQL SET i = i + 1; # i自增1 END WHILE; #结束循环 END; #结束事务 $$ DELIMITER; #此处为定义的分界符的结束符 ----------------------- call testInsert(); #先执行上方的存储过程,再执行这一句,调用存储过程的SQL;
存储过程
1、什么是存储过程?
一个存储过程是一个可编程的函数,经编译后存储在数据库中,用户经过指定存储过程的名字并给定参数(若是该存储过程带有参数)来调用执行它。
存储过程通常有如下优点:
1) 封装性,存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的 SQL 语句,并且数据库专业人员可以随时对存储过程进行修改,而不会影响到调用它的应用程序源代码。
2) 可增强 SQL 语句的功能和灵活性,存储过程可以用流程控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
3) 可减少网络流量,由于存储过程是在服务器端运行的,且执行速度快,因此当客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而可降低网络负载。
4) 高性能,存储过程执行一次后,产生的二进制代码就驻留在缓冲区,在以后的调用中,只需要从缓冲区中执行二进制代码即可,从而提高了系统的效率和性能。
5) 提高数据库的安全性和数据的完整性,使用存储过程可以完成所有数据库操作,并且可以通过编程的方式控制数据库信息访问的权限。
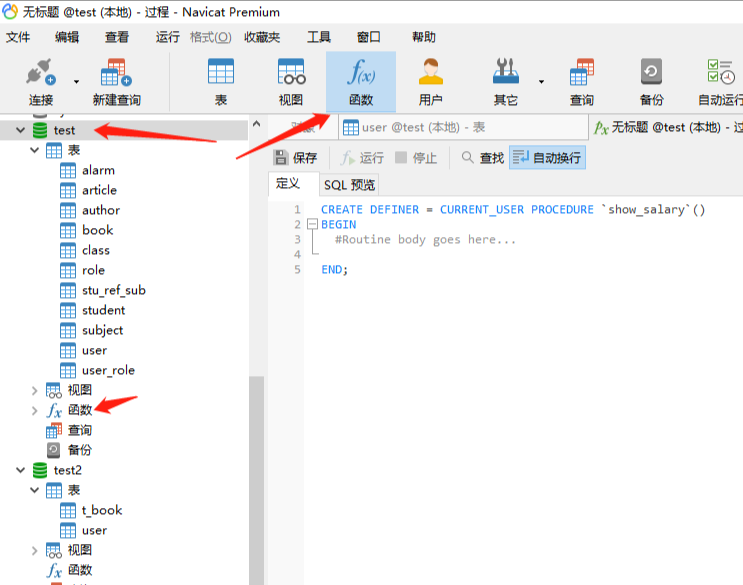
2、创建的存储过程,在哪里查看和编辑?
3、进阶用法,
DELIMITER $$ DROP PROCEDURE IF EXISTS car; CREATE PROCEDURE car(IN orderno VARCHAR(200)) #(按格式定义参数,in输入参数,out输出参数) BEGIN DECLARE maid BIGINT; DECLARE orgid BIGINT; DECLARE orderid BIGINT; DECLARE result INT; set maid = (SELECT 表1列 FROM 表2 WHERE 表1列 = (SELECT 表2列 FROM 表2 WHERE ORDER_NO = orderno)); set orgid = (SELECT 表2列1 FROM 表2 WHERE `ORDER_NO` = orderno); set orderid = (SELECT 表2列2 FROM 表2 WHERE `ORDER_NO` = orderno); set result = (SELECT count(1) FROM 表4 WHERE order_no = orderno); #变量的值可以是SQL语句的值 IF result >= 1 THEN update表5 set 列 = 值 where 列 = orderno; ELSE INSERT INTO 表5 (`列1`, `列2`,) VALUES (orderid, orderno); END IF; # IF else 的用法 INSERT INTO 表6 ( `列1`, `列2`) VALUES (maid, orgid, ); END; $$ DELIMITER; call car('30030023083018877792'); #输入参数的用法
①输入参数(IN):
a.用于向存储过程传递数据。
b.存储过程内部可以读取该参数的值,但不能修改它。
c.输入参数————在调用存储过程中传递数据给存储过程的参数(在调用的过程必须为具有实际值的变量或者字面值)
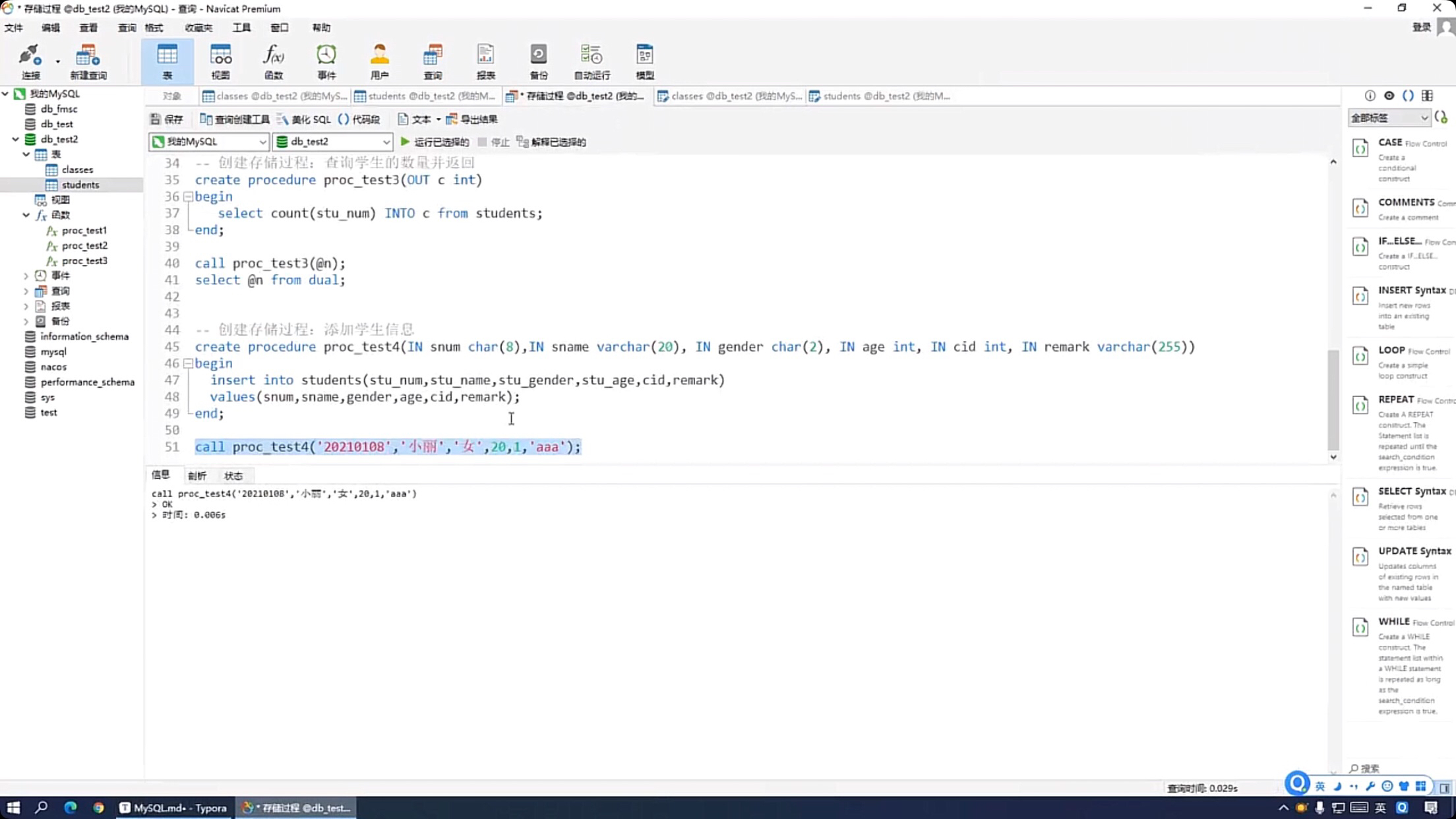
--创建存健过程:添加学生信息 create procedure proc_test4(IN snum char(8),IN sname varchar(20),IN gender char(2),IN age int,IN cid int,INremark varchar(255)) begin insert into students(stu_num,stu_name,stu_gender,stu_age,cid,remark) values(snum,sname,gender,age,cid,remark); end; call proc_test4 ('20210100','小雨','女',20.1,'aaa');
②输出参数(OUT):
a.用于从存储过程返回数据。
b.存储过程内部可以修改该参数的值,调用者可以读取该参数的值。
c.输出参数————将存储过程中产生的数据返回给过程调用者,相当于Java方法的返回值,但不同的是一个存储过程可以有多个输出参数
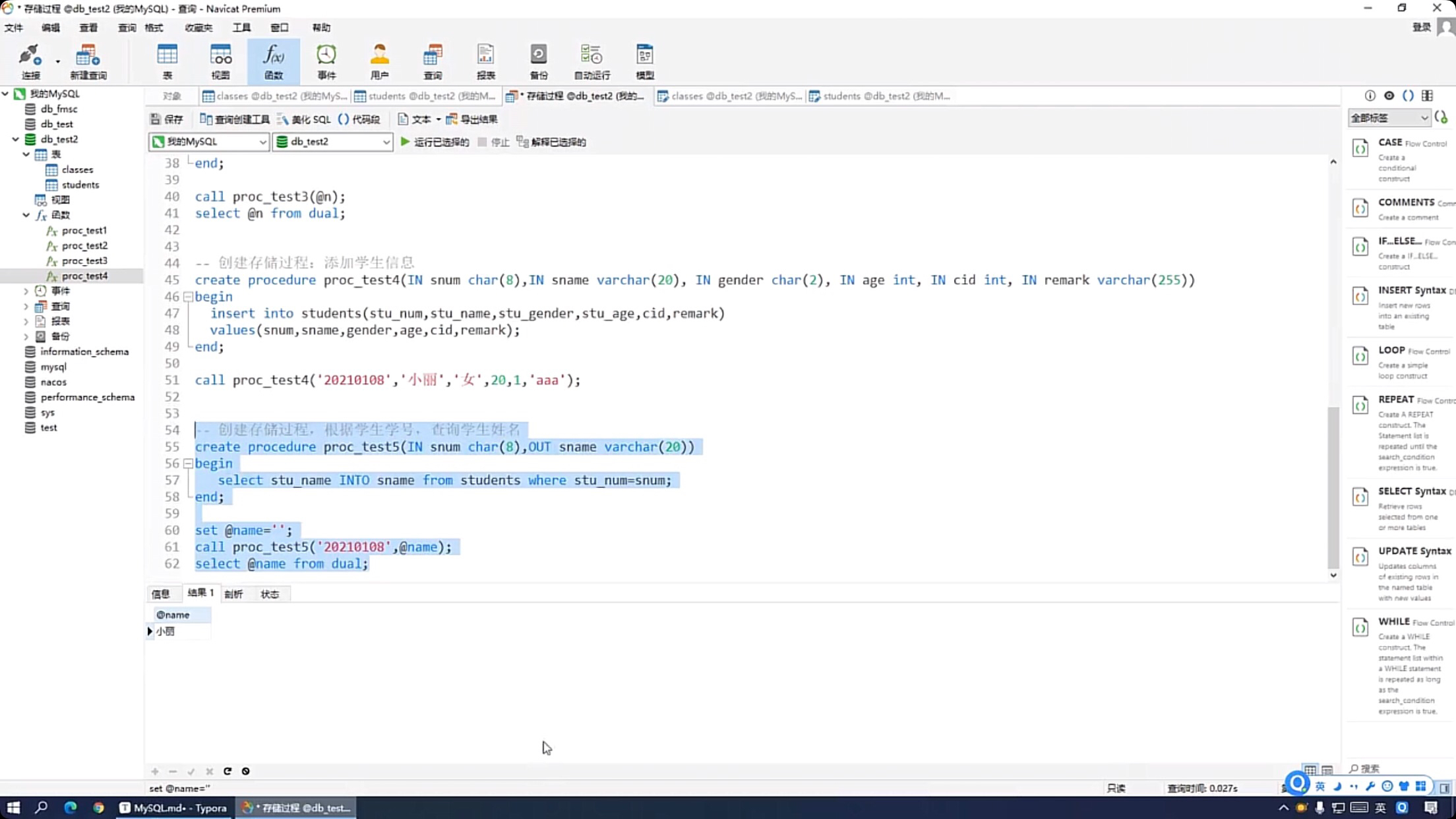
--创建存健过程,根据学生学号,查询学生姓名 create procedure proc_test5(IN snum char(8),ouT sname varchar(20)) begin select stu_name INTO sname from students where stu_num=snum; end; set @name=''; call proc_test5('20210108,@name); select @name from dual;
③输入输出参数(INOUT):
a.既可以向存储过程传递数据,又可以从存储过程返回数据。
b.存储过程内部可以读取和修改该参数的值,调用者也可以读取和修改该参数的值。
create procedure proc_test6(INOUT str varchar(20)) begin select stu_name INTO str from students where stu_num=str: end; set @name='20210188'; call proc_test6(@name); select @name from dual;
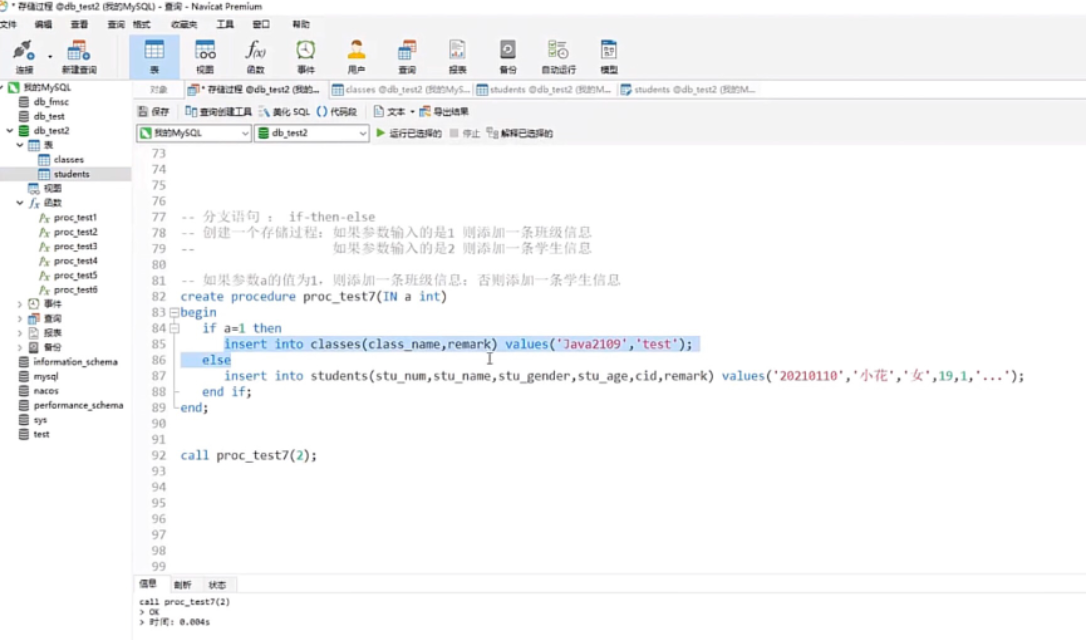
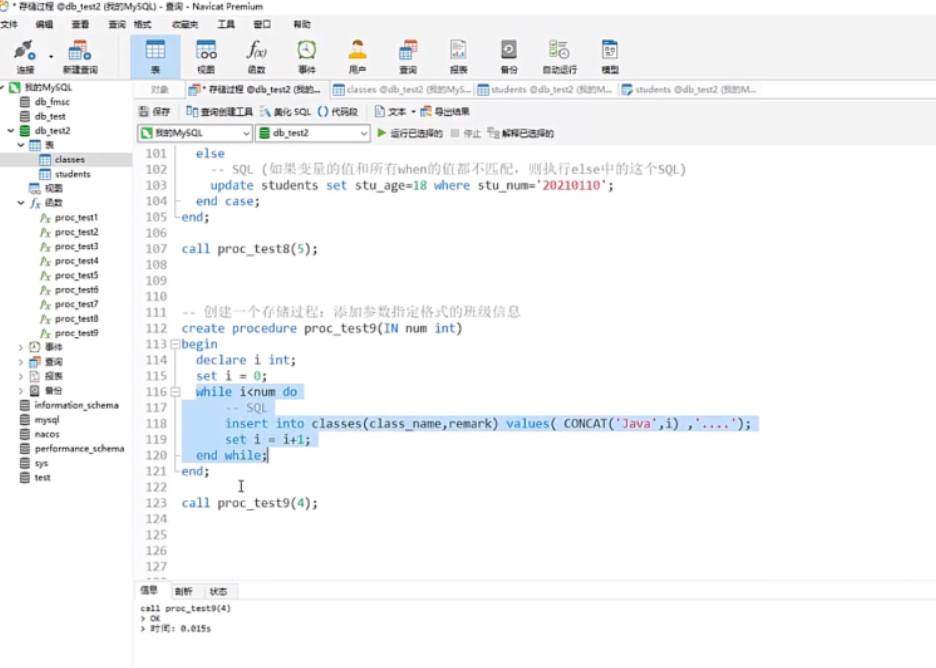
MySQL存储过程中的WHILE循环会在指定的条件为TRUE时重复执行代码块。它首先检查条件,如果条件为TRUE,则执行循环体内的语句;如果条件为FALSE,则退出循环。WHILE循环提供了一个基于条件的重复执行机制。
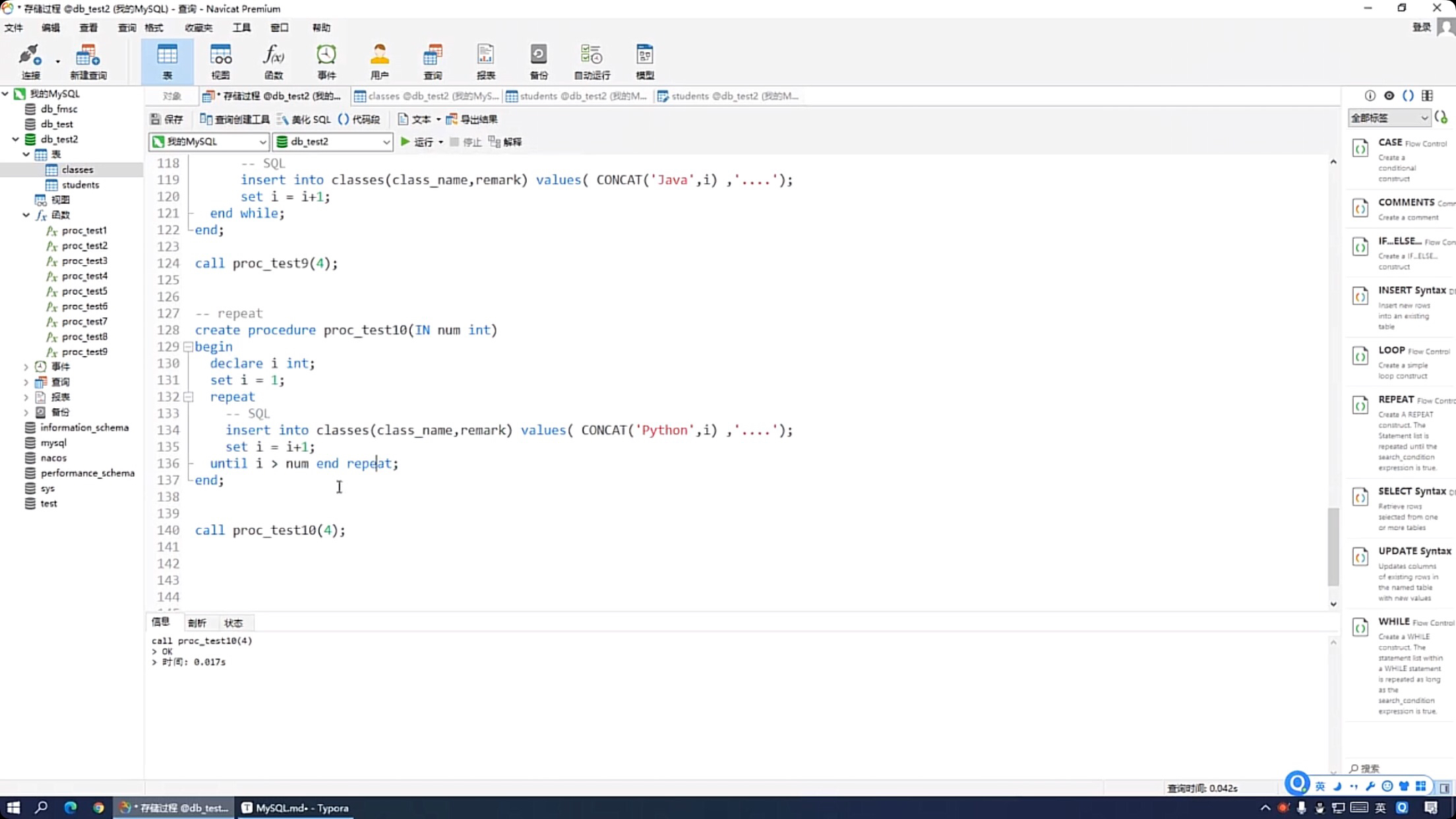
MySQL存储过程中的REPEAT循环会重复执行代码块,直到指定的条件为FALSE。它首先执行循环体,然后检查条件。如果条件为TRUE,则继续循环;如果为FALSE,则退出循环。与WHILE循环不同,REPEAT循环至少会执行一次。
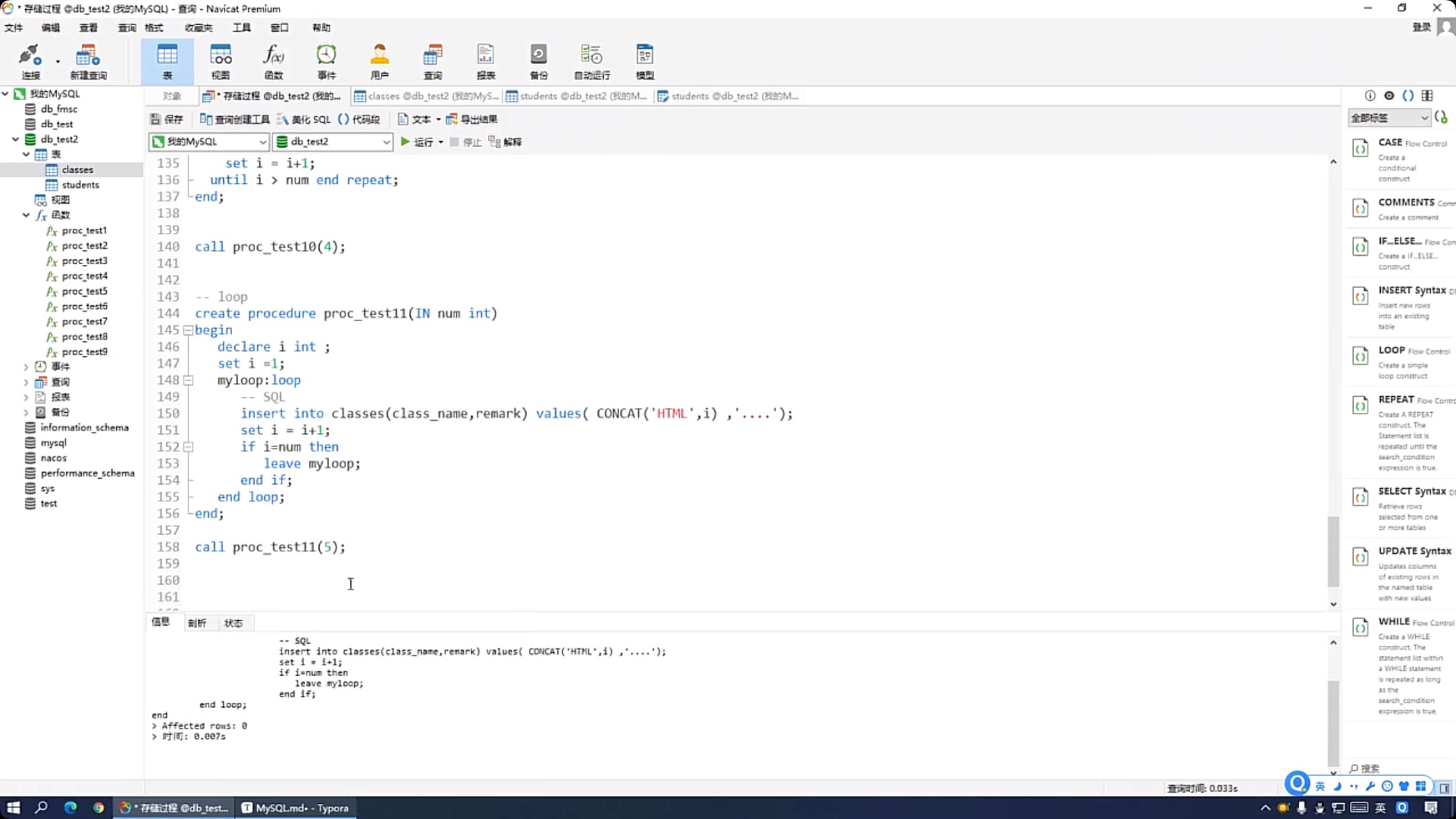
MySQL存储过程中的LOOP是一个无条件循环语句,用于重复执行代码块直到遇到LEAVE语句。使用时需声明循环体,并在适当位置加入LEAVE语句以终止循环,避免无限循环。LOOP不提供内置退出条件,需手动控制循环终止。
结语
亲爱的朋友:希望本文中描述的问题以及解决方案,可以帮助到您。当然,我们深知,问题和挑战总是层出不穷,新的情况也在不断涌现。如果读者朋友您有更好的方案,或者在实际应用中发现了文中的不足之处,请不吝分享您的宝贵建议。诚挚地邀请每一位读者加入我们的行列,共同完善这份教程。
感谢您的阅读与支持!
Dear frends,
We hope that the questions and solutions presented in this article can be of assistance to you. Of course, we are fully aware that problems and challenges are always emerging in an endless stream, and new situations are constantly arising. If you, our readers, have better solutions or have discovered any deficiencies in this article through practical application, please do not hesitate to share your valuable suggestions with us. We sincerely invite every reader to join us in continuously improving this tutorial.
Thank you for your reading and support!
See you,Parting is for better meeting!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号