
tensorflow函数介绍(2)
参考:tensorflow书
1、模型的导出:
import tensorflow as tf v1=tf.Variable(tf.constant(2.0),name="v1") v2=tf.Variable(tf.constant(3.0),name="v2") init_op=tf.global_variables_initializer() saver=tf.train.Saver() with tf.Session() as sess: sess.run(init_op) saver_path=saver.save(sess,"model.ckpt") print("model saved in file:",saver_path)
2、模型的导入:
import tensorflow as tf saver = tf.train.import_meta_graph("model.ckpt.meta") with tf.Session() as sess: saver.restore(sess, "model.ckpt") print (sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
例1:模型的导入、导出的应用
import tensorflow as tf var_1=tf.Variable(tf.constant([1,2],shape=[1,2]),name='var_1',dtype=tf.int32) var_2=tf.placeholder(shape=[2,1],name='var_2',dtype=tf.int32) var_3=tf.matmul(var_1,var_2,name='var_3') with tf.Session() as sess: saver=tf.train.Saver() init=tf.global_variables_initializer() sess.run(init) saver.save(sess,'data.chkp') saver=tf.train.import_meta_graph('data.chkp.meta') predict=tf.get_default_graph().get_tensor_by_name('var_3:0') sess.run(init) print(predict.eval(session=sess,feed_dict={var_2:[[2],[2]]})) with tf.Session() as sess: saver.restore(sess,'data.chkp') print(sess.run(var_3,feed_dict={var_2:[[5],[5]]}))
接上(若对变量名字作了改变,则在tf.train.Saver()中引入字典来作调整):
import tensorflow as tf var_1=tf.Variable(tf.constant([1,2],shape=[1,2]),name='other_var_1') var_2=tf.Variable(tf.constant([1,2],shape=[2,1]),name='other_var_2') #将上面代码的placeholder换成Variable var_3=tf.matmul(var_1,var_2,name='var_3') saver=tf.train.Saver({'var_1':var_1,'var_2':var_2}) with tf.Session() as sess: saver.restore(sess,'data.chkp') print(sess.run(var_3))
3、迭代的计数表示:
参考:http://blog.csdn.net/shenxiaolu1984/article/details/52815641
global_step = tf.Variable(0, trainable=False)
increment_op = tf.assign_add(global_step, tf.constant(1))
lr = tf.train.exponential_decay(0.1, global_step, decay_steps=1, decay_rate=0.9, staircase=False) #创建计数器衰减的tensor
tf.summary.scalar('learning_rate', lr) #对标量数据汇总和记录,把tensor添加到观测中
sum_ops = tf.summary.merge_all() #获取所有的操作
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
summary_writer = tf.train.SummaryWriter('/tmp/log/', sess.graph) #将监测结果输出目录
for step in range(0, 10): #迭代写入文件
s_val = sess.run(sum_ops) # 获取serialized监测结果:bytes类型的字符串
summary_writer.add_summary(s_val, global_step=step) # 写入文件
sess.run(increment_op)
4、指数衰减法tf.train.exponential_decay()的使用
参考:http://blog.csdn.net/zsean/article/details/75196092
decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps) #每轮迭代通过乘以decay_rate来调整学习率值 global_step = tf.Variable(0) learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True) #生成学习率,其中衰减率为0.96,每100轮巡检进行一次迭代,学习率乘以0.96 learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(....., global_step=global_step) #使用指数衰减学习率来进行梯度下降优化
注:Adam算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即alpha)更新所有的权重,学习率在训练过程中并不会改变。而Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
5、通过自己创建collection组织对象,来构建loss
import tensorflow as tf x1=tf.constant(1.0) l1=tf.nn.l2_loss(x1) x2 = tf.constant([2.5, -0.3]) l2 = tf.nn.l2_loss(x2) tf.add_to_collection('losses',l1) #通过手动指定一个collection来将创建的损失添加到集合 tf.add_to_collection("losses", l2) losses=tf.get_collection('losses') #创建完成后统一获取所有损失,losses是一个tensor类型的list loss_total=tf.add_n(losses) #把所有损失累加起来得到一个tensor sess=tf.Session() init=tf.global_variables_initializer() sess.run(init) sess.run(losses) sess.run(loss_total)
6、tf.nn.embedding_lookup(embedding, self.input_x)的含义
该函数返回embedding中的第input_x行所对应的内容,并得到这些行所组成的tensor,如下图:
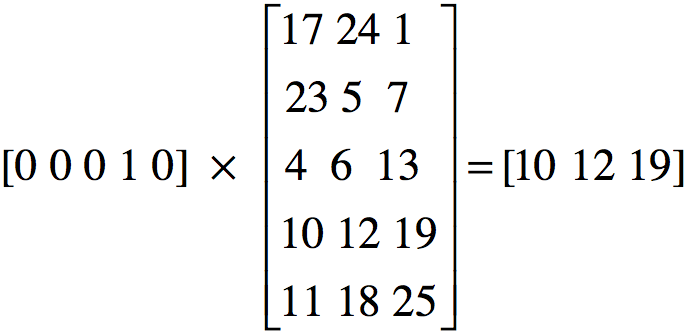

 浙公网安备 33010602011771号
浙公网安备 33010602011771号