提升算法(1)
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易得多,提升法就是从弱学习算法出发,反复学习,得到一系列弱分类器,然后组合弱分类器构成强分类器。大多数提升法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
关于AdaBoost的做法是,1、提高前一轮弱分类器错误分类样本的权值,降低正确分类样本的权值,从而以权值增大来获取对弱分类器更大的关注。2、关于分类结果的问题,AdaBoost采取加权多数表决的方法,加大分类误差率小的弱分类器的权值,使其在表决中起到作用更大,减少分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
AdaBoost算法:
输入:训练数据集![]() ,其中
,其中![]() ,弱学习算法
,弱学习算法
输出:最终分类器G(x)
(1) 初始化训练数据的权值分布(设定基分类器对每条训练数据的权值)
![]()
(2) 对m=1,2,...,M
1) 使用具有权值分布Dm的训练数据集学习,得到基本分类器:![]()
2) 计算Gm(x)在训练数据集上的分类误差率
![]()
3) 计算Gm(x)的系数(计算每个基分类器的系数,用以进一步加权求和得到sign分类结果)
![]()
(这里的log为ln)
4) 更新训练数据集的权值分布(用以更新数据集的权值w)
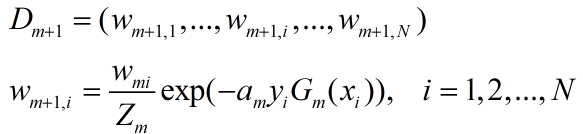
这里,Zm是规范化因子
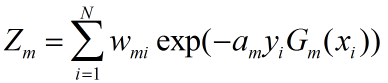
以上部分的![]() 为各实例xi由基分类器判别得到的所属类别,那么
为各实例xi由基分类器判别得到的所属类别,那么![]() 在基分类器正确分类的时候值为1,错误分类的时候值为-1.
在基分类器正确分类的时候值为1,错误分类的时候值为-1.
(3) 构建基本分类器的线性组合(构造最终的分类)
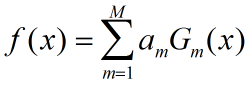
得到最终分类器:
![]()
AdaBoost算法的说明:
AdaBoost反复学习基本分类器,在每一轮m=1,2,...,M顺序执行如下操作:
1)使用当前分布Dm加权的训练数据集,学习基本分类器Gm(x)
2)计算基本分类器Gm(x)在加权训练数据集上的分类误差率:
![]()
其中![]() 。这说明Gm(x)在加权的训练数据集上的分类误差率是被Gm(x)误分类样本的权值之和,由此可得数据权值分布Dm与基本分类器Gm(x)的分类误差率的关系。
。这说明Gm(x)在加权的训练数据集上的分类误差率是被Gm(x)误分类样本的权值之和,由此可得数据权值分布Dm与基本分类器Gm(x)的分类误差率的关系。
3)计算基本分类器Gm(x)的系数am,表示Gm(x)在最终分类器的重要性,由am的计算公式可以发现,当em小于0.5的时候am大于0,反之亦然。因而分类误差率越小的基本分类器在最终分类器中起到的作用越大。
4)通过更新训练数据的权值分布来为下一轮迭代做输入,表示如下:
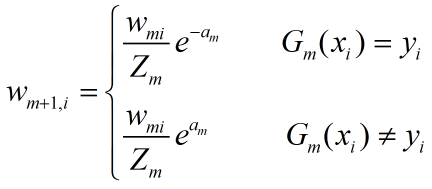
![]() 表示基分类器的返回判断结果。
表示基分类器的返回判断结果。
从而被基分类器Gm(x)误分类样本的权值会得以扩大,被正确分类样本的权值会缩小。误分类样本在下一轮学习中起到更大作用,以改变训练数据权值分布,来使训练数据在基分类器的学习中起不同的作用。
在最终的分类过程中,f(x)的符号决定实例分类,通过基分类器的线性组合构建最终分类器。
AdaBoost最基本的性质是它能在学习过程中不断减少训练误差,即在训练数据集上的分类误差率,关于这个问题有如下定理:
AdaBoost的训练误差界:
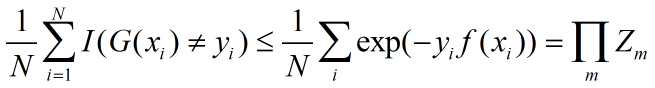
其中I为指示函数,当满足条件时为1,否则为0;
二分类问题AdaBoost的训练误差界:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号