决策树算法(3)
CART树:
该树的生成就是递归的构建二叉决策树的过程,对回归树用平方误差最小化准则,对分类树用gini指数最小化准则,进行特征选择,生成二叉树。
(1)回归树
假设X和Y分别为输入和输出变量,Y为连续变量,给定数据集D={(x1,y1),(x2,y2),...(xn,yn)}
假设输入空间划分为M个单元R1,R2,...,RM,并且在每个单元Rm上有一个固定的输出cm,于是回归树模型可以表示为:

当输入空间划分确定时,可用平方误差
![]()
来表示回归树对于数据集的预测误差,用平方误差最小的准则求解每个单元的最优输出。单元Rm上的cm的最优值是Rm的所有输入实例xi对应的输出yi的均值,下式子用于计算最小二乘法:
![]()
从每个子cart树中寻找划分点的过程分为选取第j个变量x(j)和其取值s,作为切分变量和切分点,按照如下要求对样本集进行划分:
![]() 和
和![]()
然后寻找最优切分变量j和最优切分点s,具体表现为求解
![]()
对固定输入变量j可以找到最优切分点s
![]() 和
和![]()
遍历所有输入变量,找到最优切分变量j,构成对(j,s),以此划分2个区域,对每个区域重复上述划分过程,直到满足停止条件为止,从而生成决策树,这种方法也成为最小二乘回归树。(总结为变量的遍历,然后寻找最佳切分点,然后做递归生成树)
最小二乘回归树算法如下:
输入:训练数据集D
输出:回归树f(x)
在训练数据集空间,递归将每个区域划分为2个子区域并决定每个子区域的输出值,构建决策树
(1)选择最优切分变量j和切分点s,求解
![]()
遍历变量j,对固定切分变量j扫描切分点s,使上市达到最小值的(j,s)
(2)用选定的(j,s)划分区域并决定相应输出值,左右空间分别表示为:
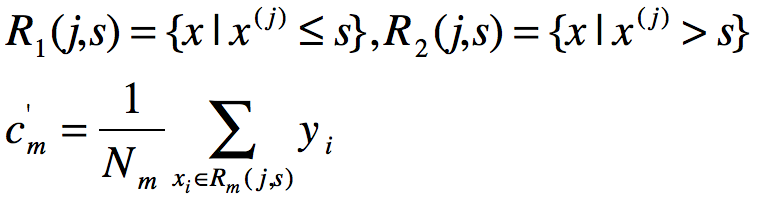
(3)重复对子区域调用步骤(1)、(2)
(4)将输入空间划分M个区域R1,R2,...Rm,并生成决策树
(2)分类树
分类数采用gini指数作为特征筛选条件,假设有K的类,样本点属于第k类的概率为pk,则概率分布的gini指数定义为:
![]() (因为
(因为![]() )
)
如果目标是二分类的话,概率分布的基尼值也可以表示为:
Gini(p)=2p(1-p)
因此,样本集D的基尼指数同样可以表示为:
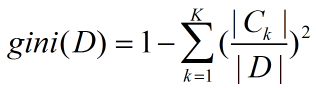
上式的Ck是D中属于第k类的样本集,K是类的个数
CART树算法:
输入:训练数据集D
输出:CART决策树
(1) 设结点训练数据集为D,计算现有特征基尼系数,对每个特征A,对其可能取值的a,根据样本点对A=a的测试为"是"或“否”将D分割成D1和D2两部分,计算属于特征A的基尼系数
(2) 在所有可能的特征A及可能的切分点a中,选择基尼系数最小的特征及对应切分点作为最优特征和最优切分点。并依次将训练集分配到2个子结点
(3) 递归调用(1)和(2),直到分配完毕
(4) 生成CART决策树
CART剪枝:
CART树剪枝通过从决策树T0底端开始剪枝,往上遍历直到根结点,形成子树序列{T0,T1,...,Tn},然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。这里书上讲的并不细致,可以按照以下方式来理解。首先介绍剪枝后属于子结点转为叶结点t的损失函数:
Ca(t)=C(t)+a
以及剪枝之前子树的损失函数:
Ca(Tt)=C(Tt)+a|Tt|
上式中|Tt|表示叶结点的数量,假若进行剪枝,则叶结点的数量则为1.
将剪枝前后的损失函数进行相减,可得到:
![]()
a存在临界值g(t)使得当a>g(t)的时候有:Ca(Tt)>Ca(t)
当a<g(t)时候有:Ca(Tt)<Ca(t)
由于在生成CART树之后,各子结点及对应的树结点的a值都已确定,因此按照a值从大到小进行排序。给定剪枝的a给定阈值a',若计算的a<a',则可进行剪枝,然后逐渐按照小到大逐渐剪枝到阈值为止,然后记录当前树。将阈值从小到大不断调整 ,得到不同的剪枝后决策树。通过另外的测试集来判断该不同的决策树的准确率,选取准确率最高的作为最终结果。
输入:CART算法生成的决策树T0
输出:最优决策树Ta
(1) 设k=0 T=T0
(2)设a=+∞
(3)自上而下对内部结点t计算C(Tt),|Tt|以及
![]()
其中,Tt表示t为根结点的子树,C(Tt)表示对训练数据的预测误差(如基尼指数),|Tt|是Tt的叶结点个数
(4) 对g(t)=a的内部结点t进行剪枝,并对叶结点t以多数表决法决定所属类别,并得到树T
(5)设k=k+1 , ak=a ,Tk=T
(6) 如果Tk不是由根结点及两个叶结点构成的树,则返回步骤3, 否则令Tk=Tn
(7) 用交叉验证法在子树序列T0,T1,....,Tn中选取最优子树Ta

 浙公网安备 33010602011771号
浙公网安备 33010602011771号