朴素贝叶斯算法
(1)朴素贝叶斯基本方法:
输入数据有:标记集合 y={c1,c2,...ck}, 特征向量x , 也即训练数据集T={(x1,y1),(x2,y2),....(xn,yn)}
朴素贝叶斯法通过训练数据集学习联合概率分布P(X,Y)(通过联合概率分布P(X,Y)进行不同条件概率的转换),
先验概率分布:P(Y=ck), k=1,2,...,K
条件概率分布:P(X=x|Y=ck)=P(X(1)=x(1), X(2)=x(2),...,X(n)=x(n)|Y=ck) k=1,2,...,K (X(n)=x(n)表示样本集在n维特征的取值)
在此,朴素贝叶斯法对条件概率做了条件独立性的假设,从而有:
P(X=x|Y=ck)=P(X(1)=x(1), X(2)=x(2),...,X(n)=x(n)|Y=ck)
=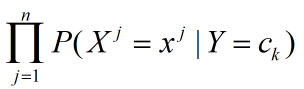
朴素贝叶斯法学习到生成数据的机制,也称为生成模型,条件独立假设即用于分类的特征在类确定的前提下是条件独立的。
在朴素贝叶斯法分类时,在给定新的输入数据x,通过学习好的模型计算后验概率分布:

将以上2个式子合并得到:
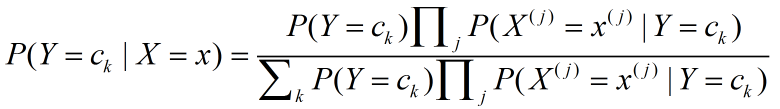 其中k=1,2,...K
其中k=1,2,...K
因此朴素贝叶斯分类器可以表示为:
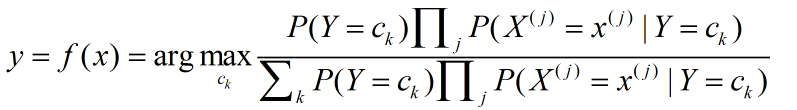
由于对于不同的分类类别的分母都是一样的,因此将其简化后表示为:
![]()
总结的来说就是在得到输入新数据的各特征x之后,计算求得P(Y=ck|X=x)的各类别概率,返回该最大概率的所属类别,那么该类别就是贝叶斯分类器学习到的预测结果。
(2)从损失函数推导后验概率最大化:
选择损失函数:

其中f(X)为分类决策函数,因此期望风险函数为:
![]()
为了使期望风险最小,因而原式可转化为:
![]()
![]()
![]()
从而根据期望风险最小化得到后验化概率最大化准则。
(3)朴素贝叶斯算法过程:
输入:训练数据集T={(x1,y1),(x2,y2),...{xn,yn}} 其中xi=(xi(1),xi(2),...xi(n))T, xi(j) 是第i个样本的第j个特征,yi属于{c1,c2,...cK}
输出:实例x的分类
1)计算先验概率及条件概率

j=1,2,...,n; l=1,2,...,Sj; k=1,2,...,K
2) 对于给定实例x=(x(1),x(2),...x(n))T, 计算
![]()
3) 确实实例x的类别:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号