
什么是自注意力机制?
自注意力机制(Self-Attention Mechanism)是一种在自然语言处理和计算机视觉等领域中广泛使用的技术,它可以帮助模型在处理序列数据时更好地理解上下文信息。
在自注意力机制中,输入序列被表示为一组向量(比如说在自然语言处理中,可以将一句话中的每个单词表示为一个向量),每个向量都被称为一个"查询"。自注意力机制会计算每个查询与其它查询之间的相似度,并根据相似度给每个查询分配一个权重。这些权重表示了模型在处理当前查询时应该关注哪些上下文信息。
自注意力机制的计算过程通常可以分为三个步骤:
- 对输入序列中的每个查询,通过矩阵乘法计算它与所有查询之间的相似度。这个相似度可以使用点积、加性注意力等方式计算。
- 根据相似度计算每个查询的权重。这个权重可以使用 softmax 函数来归一化相似度,使得所有权重的和为1。
- 将每个查询的权重与其它查询的向量进行加权平均,得到每个查询的输出向量。
自注意力机制可以被应用于很多不同的模型中,例如Transformer模型,它在机器翻译、文本生成、语音识别等任务中取得了显著的成功。
自注意力过程(self-attention)
自注意力机制重要组成部分是三个向量:
- query:在注意力机制中,查询表示当前正在处理的单词或token的表示方式。它用于评估与其他单词之间的相关性。简而言之,查询是我们要关注的中心对象。
- key:键向量是对文本中所有单词的标签或描述。它们类似于我们用来在搜索相关单词时进行匹配的内容。在注意力机制中,我们会使用查询和键之间的关系来确定不同单词之间的相关性。
- value:值向量是实际的单词表示方式,通常是通过神经网络学习得到的。一旦我们使用查询和键来评估不同单词之间的相关性,我们将使用这些值向量来计算当前单词的最终表示。值向量会被加权组合,以代表当前单词的含义或重要性。
其公式表示如下:
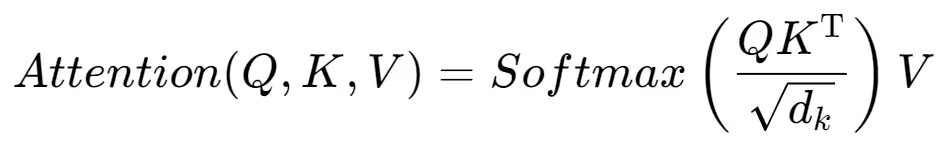
其中, 和𝑄,𝐾和𝑉 是输入矩阵,分别代表查询矩阵、键矩阵和值矩阵,$d_k$ 是向量维度。Attention公式的作用是通过对$Q$ 和$K$ 的相似度进行加权,来得到对应于输入的$V$的加权和。
具体来说,这个公式分为三个步骤:
(1)计算 𝑄 和 𝐾 之间的相似度,即 𝑄𝐾𝑇 。
(2)由于 𝑄 和 𝐾 的维度可能很大, 因此需要将其除以 𝑑𝑘 来缩放。这有助于避免在 Softmax 计算时出现梯度消失或梯度爆炸的问题。
(3) 对相似度矩阵进行 Softmax 操作, 得到每个查询向量与所有键向量的权重分布。然后, 将这些权重与值矩阵 𝑉 相乘并相加, 得到自注意力机制的输出矩阵。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号