3.朴素贝叶斯和KNN算法的推导和python实现
前面一个博客我们用Scikit-Learn实现了中文文本分类的全过程,这篇博客,着重分析项目最核心的部分分类算法:朴素贝叶斯算法以及KNN算法的基本原理和简单python实现。
3.1 贝叶斯公式的推导
简单介绍一下什么是贝叶斯:
1 看着后视镜往前开车



%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mn%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-39%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-35%22%20x%3D%22500%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1001%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-25%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) 的概率是错误的。
的概率是错误的。
2 结合开车来理解贝叶斯公式
%3DP(A)%5Cfrac%7BP(B%7CA)%7D%7BP(B)%7D%3C%2Ftitle%3E%0A%3Cdefs%20aria-hidden%3D%22true%22%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-50%22%20d%3D%22M287%20628Q287%20635%20230%20637Q206%20637%20199%20638T192%20648Q192%20649%20194%20659Q200%20679%20203%20681T397%20683Q587%20682%20600%20680Q664%20669%20707%20631T751%20530Q751%20453%20685%20389Q616%20321%20507%20303Q500%20302%20402%20301H307L277%20182Q247%2066%20247%2059Q247%2055%20248%2054T255%2050T272%2048T305%2046H336Q342%2037%20342%2035Q342%2019%20335%205Q330%200%20319%200Q316%200%20282%201T182%202Q120%202%2087%202T51%201Q33%201%2033%2011Q33%2013%2036%2025Q40%2041%2044%2043T67%2046Q94%2046%20127%2049Q141%2052%20146%2061Q149%2065%20218%20339T287%20628ZM645%20554Q645%20567%20643%20575T634%20597T609%20619T560%20635Q553%20636%20480%20637Q463%20637%20445%20637T416%20636T404%20636Q391%20635%20386%20627Q384%20621%20367%20550T332%20412T314%20344Q314%20342%20395%20342H407H430Q542%20342%20590%20392Q617%20419%20631%20471T645%20554Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-28%22%20d%3D%22M94%20250Q94%20319%20104%20381T127%20488T164%20576T202%20643T244%20695T277%20729T302%20750H315H319Q333%20750%20333%20741Q333%20738%20316%20720T275%20667T226%20581T184%20443T167%20250T184%2058T225%20-81T274%20-167T316%20-220T333%20-241Q333%20-250%20318%20-250H315H302L274%20-226Q180%20-141%20137%20-14T94%20250Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-41%22%20d%3D%22M208%2074Q208%2050%20254%2046Q272%2046%20272%2035Q272%2034%20270%2022Q267%208%20264%204T251%200Q249%200%20239%200T205%201T141%202Q70%202%2050%200H42Q35%207%2035%2011Q37%2038%2048%2046H62Q132%2049%20164%2096Q170%20102%20345%20401T523%20704Q530%20716%20547%20716H555H572Q578%20707%20578%20706L606%20383Q634%2060%20636%2057Q641%2046%20701%2046Q726%2046%20726%2036Q726%2034%20723%2022Q720%207%20718%204T704%200Q701%200%20690%200T651%201T578%202Q484%202%20455%200H443Q437%206%20437%209T439%2027Q443%2040%20445%2043L449%2046H469Q523%2049%20533%2063L521%20213H283L249%20155Q208%2086%20208%2074ZM516%20260Q516%20271%20504%20416T490%20562L463%20519Q447%20492%20400%20412L310%20260L413%20259Q516%20259%20516%20260Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-7C%22%20d%3D%22M139%20-249H137Q125%20-249%20119%20-235V251L120%20737Q130%20750%20139%20750Q152%20750%20159%20735V-235Q151%20-249%20141%20-249H139Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-42%22%20d%3D%22M231%20637Q204%20637%20199%20638T194%20649Q194%20676%20205%20682Q206%20683%20335%20683Q594%20683%20608%20681Q671%20671%20713%20636T756%20544Q756%20480%20698%20429T565%20360L555%20357Q619%20348%20660%20311T702%20219Q702%20146%20630%2078T453%201Q446%200%20242%200Q42%200%2039%202Q35%205%2035%2010Q35%2017%2037%2024Q42%2043%2047%2045Q51%2046%2062%2046H68Q95%2046%20128%2049Q142%2052%20147%2061Q150%2065%20219%20339T288%20628Q288%20635%20231%20637ZM649%20544Q649%20574%20634%20600T585%20634Q578%20636%20493%20637Q473%20637%20451%20637T416%20636H403Q388%20635%20384%20626Q382%20622%20352%20506Q352%20503%20351%20500L320%20374H401Q482%20374%20494%20376Q554%20386%20601%20434T649%20544ZM595%20229Q595%20273%20572%20302T512%20336Q506%20337%20429%20337Q311%20337%20310%20336Q310%20334%20293%20263T258%20122L240%2052Q240%2048%20252%2048T333%2046Q422%2046%20429%2047Q491%2054%20543%20105T595%20229Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-29%22%20d%3D%22M60%20749L64%20750Q69%20750%2074%20750H86L114%20726Q208%20641%20251%20514T294%20250Q294%20182%20284%20119T261%2012T224%20-76T186%20-143T145%20-194T113%20-227T90%20-246Q87%20-249%2086%20-250H74Q66%20-250%2063%20-250T58%20-247T55%20-238Q56%20-237%2066%20-225Q221%20-64%20221%20250T66%20725Q56%20737%2055%20738Q55%20746%2060%20749Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-3D%22%20d%3D%22M56%20347Q56%20360%2070%20367H707Q722%20359%20722%20347Q722%20336%20708%20328L390%20327H72Q56%20332%2056%20347ZM56%20153Q56%20168%2072%20173H708Q722%20163%20722%20153Q722%20140%20707%20133H70Q56%20140%2056%20153Z%22%3E%3C%2Fpath%3E%0A%3C%2Fdefs%3E%0A%3Cg%20stroke%3D%22currentColor%22%20fill%3D%22currentColor%22%20stroke-width%3D%220%22%20transform%3D%22matrix(1%200%200%20-1%200%200)%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(751%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1141%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-41%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-texatom%22%20transform%3D%22translate(1891%2C0)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-7C%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(2170%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(2929%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(3596%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(4653%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(5404%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(5794%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-41%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(6544%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mfrac%22%20transform%3D%22translate(6934%2C0)%22%3E%0A%3Cg%20transform%3D%22translate(120%2C0)%22%3E%0A%3Crect%20stroke%3D%22none%22%20width%3D%223439%22%20height%3D%2260%22%20x%3D%220%22%20y%3D%22220%22%3E%3C%2Frect%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%20transform%3D%22translate(60%2C770)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(751%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1141%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-texatom%22%20transform%3D%22translate(1900%2C0)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-7C%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(2179%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-41%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(2929%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%20transform%3D%22translate(574%2C-771)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(751%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1141%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(1900%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E)



%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-41%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(750%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1195%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) 的圆形面积是示意):
的圆形面积是示意):

%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) 。事件发生后导致的调整为:
。事件发生后导致的调整为: %7D%7BP(B)%7D%3C%2Ftitle%3E%0A%3Cdefs%20aria-hidden%3D%22true%22%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-50%22%20d%3D%22M287%20628Q287%20635%20230%20637Q206%20637%20199%20638T192%20648Q192%20649%20194%20659Q200%20679%20203%20681T397%20683Q587%20682%20600%20680Q664%20669%20707%20631T751%20530Q751%20453%20685%20389Q616%20321%20507%20303Q500%20302%20402%20301H307L277%20182Q247%2066%20247%2059Q247%2055%20248%2054T255%2050T272%2048T305%2046H336Q342%2037%20342%2035Q342%2019%20335%205Q330%200%20319%200Q316%200%20282%201T182%202Q120%202%2087%202T51%201Q33%201%2033%2011Q33%2013%2036%2025Q40%2041%2044%2043T67%2046Q94%2046%20127%2049Q141%2052%20146%2061Q149%2065%20218%20339T287%20628ZM645%20554Q645%20567%20643%20575T634%20597T609%20619T560%20635Q553%20636%20480%20637Q463%20637%20445%20637T416%20636T404%20636Q391%20635%20386%20627Q384%20621%20367%20550T332%20412T314%20344Q314%20342%20395%20342H407H430Q542%20342%20590%20392Q617%20419%20631%20471T645%20554Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-28%22%20d%3D%22M94%20250Q94%20319%20104%20381T127%20488T164%20576T202%20643T244%20695T277%20729T302%20750H315H319Q333%20750%20333%20741Q333%20738%20316%20720T275%20667T226%20581T184%20443T167%20250T184%2058T225%20-81T274%20-167T316%20-220T333%20-241Q333%20-250%20318%20-250H315H302L274%20-226Q180%20-141%20137%20-14T94%20250Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-42%22%20d%3D%22M231%20637Q204%20637%20199%20638T194%20649Q194%20676%20205%20682Q206%20683%20335%20683Q594%20683%20608%20681Q671%20671%20713%20636T756%20544Q756%20480%20698%20429T565%20360L555%20357Q619%20348%20660%20311T702%20219Q702%20146%20630%2078T453%201Q446%200%20242%200Q42%200%2039%202Q35%205%2035%2010Q35%2017%2037%2024Q42%2043%2047%2045Q51%2046%2062%2046H68Q95%2046%20128%2049Q142%2052%20147%2061Q150%2065%20219%20339T288%20628Q288%20635%20231%20637ZM649%20544Q649%20574%20634%20600T585%20634Q578%20636%20493%20637Q473%20637%20451%20637T416%20636H403Q388%20635%20384%20626Q382%20622%20352%20506Q352%20503%20351%20500L320%20374H401Q482%20374%20494%20376Q554%20386%20601%20434T649%20544ZM595%20229Q595%20273%20572%20302T512%20336Q506%20337%20429%20337Q311%20337%20310%20336Q310%20334%20293%20263T258%20122L240%2052Q240%2048%20252%2048T333%2046Q422%2046%20429%2047Q491%2054%20543%20105T595%20229Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-7C%22%20d%3D%22M139%20-249H137Q125%20-249%20119%20-235V251L120%20737Q130%20750%20139%20750Q152%20750%20159%20735V-235Q151%20-249%20141%20-249H139Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-41%22%20d%3D%22M208%2074Q208%2050%20254%2046Q272%2046%20272%2035Q272%2034%20270%2022Q267%208%20264%204T251%200Q249%200%20239%200T205%201T141%202Q70%202%2050%200H42Q35%207%2035%2011Q37%2038%2048%2046H62Q132%2049%20164%2096Q170%20102%20345%20401T523%20704Q530%20716%20547%20716H555H572Q578%20707%20578%20706L606%20383Q634%2060%20636%2057Q641%2046%20701%2046Q726%2046%20726%2036Q726%2034%20723%2022Q720%207%20718%204T704%200Q701%200%20690%200T651%201T578%202Q484%202%20455%200H443Q437%206%20437%209T439%2027Q443%2040%20445%2043L449%2046H469Q523%2049%20533%2063L521%20213H283L249%20155Q208%2086%20208%2074ZM516%20260Q516%20271%20504%20416T490%20562L463%20519Q447%20492%20400%20412L310%20260L413%20259Q516%20259%20516%20260Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-29%22%20d%3D%22M60%20749L64%20750Q69%20750%2074%20750H86L114%20726Q208%20641%20251%20514T294%20250Q294%20182%20284%20119T261%2012T224%20-76T186%20-143T145%20-194T113%20-227T90%20-246Q87%20-249%2086%20-250H74Q66%20-250%2063%20-250T58%20-247T55%20-238Q56%20-237%2066%20-225Q221%20-64%20221%20250T66%20725Q56%20737%2055%20738Q55%20746%2060%20749Z%22%3E%3C%2Fpath%3E%0A%3C%2Fdefs%3E%0A%3Cg%20stroke%3D%22currentColor%22%20fill%3D%22currentColor%22%20stroke-width%3D%220%22%20transform%3D%22matrix(1%200%200%20-1%200%200)%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mfrac%22%3E%0A%3Cg%20transform%3D%22translate(120%2C0)%22%3E%0A%3Crect%20stroke%3D%22none%22%20width%3D%223439%22%20height%3D%2260%22%20x%3D%220%22%20y%3D%22220%22%3E%3C%2Frect%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%20transform%3D%22translate(60%2C770)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(751%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1141%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-texatom%22%20transform%3D%22translate(1900%2C0)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-7C%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(2179%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-41%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(2929%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%20transform%3D%22translate(574%2C-771)%22%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-50%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(751%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-28%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1141%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mo%22%20transform%3D%22translate(1900%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-29%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E)
3 贝叶斯定理与人脑

%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20class%3D%22mjx-svg-mrow%22%3E%0A%3Cg%20class%3D%22mjx-svg-mn%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-35%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-30%22%20x%3D%22500%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20class%3D%22mjx-svg-mi%22%20transform%3D%22translate(1001%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-25%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) ,如果我扔了一千次都是正面,那说明了什么?
,如果我扔了一千次都是正面,那说明了什么?
第(3)步的各个条件概率,我们可以按以下步骤计算:




3.2 贝叶斯算法的实现
为了将主要的精力集中在算法本身,我们使用简单的英文语料作为数据集。
import sys import os from numpy import * import numpy as np def loadDataSet(): #训练集文本 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him','my'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #每个文本对应的分类 classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec #编写贝叶斯算法类,创建默认的构造方法 class NBayes(object): def __init__(self): self.vocabulary = [] #词典 self.idf = 0 #词典的IDF权值向量 self.tf = 0 #训练集的权值矩阵 self.tdm=0 #P(x|yi) self.Pcates = {} #p(yi)是一个类别字典,训练样本中0占多少比例,1占多少比例 self.labels= [] #对应每个文本的分类,是一个外部导入的列表 self.doclength = 0 #训练集文本数 self.vocablen = 0 #词典词长 self.testset = 0 #测试集 #导入和训练数据集,生成算法所必需的参数和数据结构 def train_set(self,trainset,classVec): self.cate_prob(classVec)#计算每个分类在数据集中的概率P(Yi) self.doclength = len(trainset)#训练集合的个数 print(self.doclength) tempset = set() #生成词典(去重后的词典,即训练样本中的所有词汇) [tempset.add(word) for doc in trainset for word in doc] print(tempset) #训练样本词典 self.vocabulary = list(tempset) #词典长度 self.vocablen = len(self.vocabulary) self.calc_wordfreq(trainset)#计算词频数据集 self.build_tdm() #按分类累计向量空间的每维值P(X|Yi) #计算在数据集中每个分类的概率P(Yi) def cate_prob(self,classVec): self.labels = classVec #输出各个分类 print(self.labels) #转成集合,去重,只有0,1 labeltemps = set(self.labels)#获取全部分类 print(labeltemps) for labeltemp in labeltemps: # 统计列表中重复的分类:self.labels.count(labeltemp) #0的比例占多少,1的比例占多少 self.Pcates[labeltemp] = float(self.labels.count(labeltemp))/float(len(self.labels)) print(self.Pcates[labeltemp]) #生成普通的词频向量 def calc_wordfreq(self,trainset): self.idf = np.zeros([1,self.vocablen])#1*词典单词数,统计的是所有的样本单词的次数 print(self.idf) self.tf = np.zeros([self.doclength,self.vocablen])#训练集文件数*词典数,统计的是每一个训练样本单词的次数 print(self.tf) #遍历训练集 for indx in range(self.doclength): # 遍历每一个训练样本中的每个词 for word in trainset[indx]: #相应位置上的单词+1,第indx行,self.vocabulary.index(word)列 #self.vocabulary.index(word)返回的是word在词典中的下标 self.tf[indx,self.vocabulary.index(word)] += 1 #整个词典的计数加1 for signleword in set(trainset[indx]): self.idf[0,self.vocabulary.index(signleword)] += 1 print(self.idf) print(self.tf) #按分类累计计算向量空间的每维值P(X|Yi) def build_tdm(self): self.tdm = np.zeros([len(self.Pcates),self.vocablen])#类别个数*词典长度 print(self.tdm) sumlist = np.zeros([len(self.Pcates),1])#类别个数*1 print(sumlist) #遍历所有的训练样本 for indx in range(self.doclength): #求同一类别的词向量空间值加总,加的是每一个训练样本对应的每个词的个数 self.tdm[self.labels[indx]] += self.tf[indx] #统计每个分类的总的词数 sumlist[self.labels[indx]] = np.sum(self.tdm[self.labels[indx]]) print(self.tdm) print(sumlist) self.tdm = self.tdm/sumlist#生成P(X|Yi),即求每个分类的单词,占该分类的所有单词总数的比例 print(self.tdm) #将测试集映射到当前词典 def map2vocab(self,testdata): #计算测试集的特征向量(非线性代数的特征向量,而是一行中对词的统计信息) self.testset = np.zeros([1,self.vocablen]) for word in testdata: self.testset[0,self.vocabulary.index(word)] += 1 #将预测分类,输出预测的分类类别 def predict(self,testset): #np.shape(testset)[1]列值 if np.shape(testset)[1] != self.vocablen:#如果测试集长度与字典不相同则退出程序 print("输入错误") exit(0) predvalue = 0 #初始化后类别概率 predclass = "" #初始化类别名称 #tdm是每一类某个单词,占该类的总的单词的比例,后面一个参数是所有类别 for tdm_vect,keyclass in zip(self.tdm,self.Pcates): #P(X|Yi) P(Yi) #变量tdm,计算最大分类值 print("---"*30) print(testset*tdm_vect*self.Pcates[keyclass]) temp = np.sum(testset*tdm_vect*self.Pcates[keyclass]) print(temp) #选择概率最大的一个 if temp > predvalue: predvalue = temp predclass = keyclass return predclass #dataset:句子的词向量 #listClasses是句子所属于的类别[0,1,0,1,0,1] dataSet,listClasses = loadDataSet()#导入外部数据集 nb = NBayes()#实例化 nb.train_set(dataSet,listClasses)#训练数据集 nb.map2vocab(dataSet[2])#随机选择一个测试句 print(nb.predict(nb.testset))#输出分类结果
3.3 kNN分类算法
前面使用了朴素贝叶斯算法实现了文本分类。下面我们可以考虑通过计算向量间的距离衡量相似度来进行文本分类。这就是kNN算法,一种基于向量间相似度的分类算法。
3.3.1 kNN算法原理
k最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法。采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样本中的大多数都属于某一个类别,则该样本也属于这个类别。第一个字母k可以小写,表示外部定义的近邻数量。举个栗子:
有一个数据集,这个数据集很简单,由二维空间上的4个点构成一个矩阵:

其中前 两个点构成一个类别A,后两个点构成一个类别B。
代码:
import sys import os from numpy import * import numpy as np import matplotlib.pyplot as plt import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels dataSet,labels = createDataSet() #绘图 fig = plt.figure() ax = fig.add_subplot(111) indx = 0 for point in dataSet: if labels[indx] == 'A': ax.scatter(point[0],point[1],c='blue',marker='o',linewidths=0,s=300) plt.annotate("("+str(point[0])+","+str(point[1])+")",xy = (point[0],point[1])) else: ax.scatter(point[0], point[1], c='red', marker='^', linewidths=0, s=300) plt.annotate("(" + str(point[0]) + "," + str(point[1]) + ")", xy=(point[0], point[1])) indx += 1 plt.show()
如下图
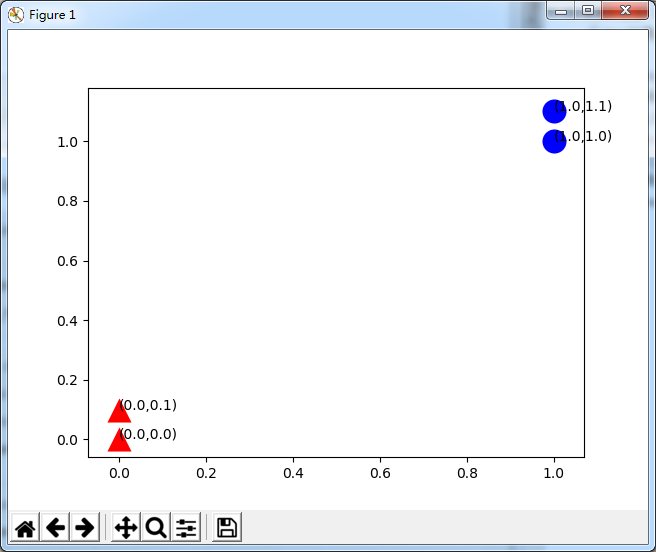
如图所示,可以清晰得看到由4个点构成的训练集。该训练集呗分成两个类别:A类----蓝色圆圈,B类----红色三角形。可以看出红色区域的点距比它们到蓝色区域内的点距要小得多,这种分类也是自然而然的。
下面再给出测试集,并把它加入到刚才的矩阵中去。
对测试集进行绘图:
import sys import os from numpy import * import numpy as np import matplotlib.pyplot as plt import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels dataSet,labels = createDataSet() #绘图 fig = plt.figure() ax = fig.add_subplot(111) indx = 0 for point in dataSet: if labels[indx] == 'A': ax.scatter(point[0],point[1],c='blue',marker='o',linewidths=0,s=300) plt.annotate("("+str(point[0])+","+str(point[1])+")",xy = (point[0],point[1])) else: ax.scatter(point[0], point[1], c='red', marker='^', linewidths=0, s=300) plt.annotate("(" + str(point[0]) + "," + str(point[1]) + ")", xy=(point[0], point[1])) indx += 1 testdata=[0.2,0.2] ax.scatter(testdata[0], testdata[1], c='green', marker='^', linewidths=0, s=300) plt.annotate("(" + str(testdata[0]) + "," + str(testdata[1]) + ")", xy=(testdata[0], testdata[1])) plt.show()
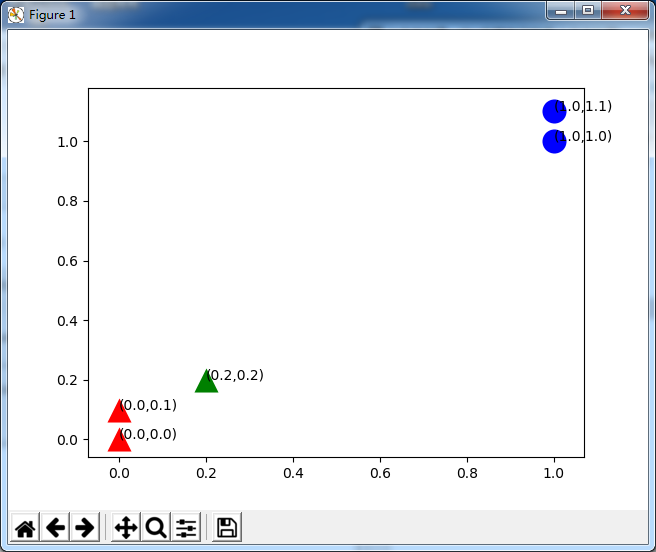
很清晰,从距离上看,它更接近红色的三角形范围,应该归入B类,这就是kNN算法的基本原理。
由此可见,kNN算法应该由如下的步骤构成:

第三阶段:统计这k个样本点钟各个类别的数量。如上图所示,如果我们选定k值为3,则B类样本(三角形)有两个,A类样本(圆形)有1个,那么我们就把这个数据点定为B类,根据k个样本中数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
3.3.2 kNN算法的Python实现
import sys import os from numpy import * import numpy as np import operator from Nbayes_lib import * def loadDataSet(): #训练集文本 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him','my'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #每个文本对应的分类 classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec #编写贝叶斯算法类,创建默认的构造方法 class NBayes(object): def __init__(self): self.vocabulary = [] #词典 self.idf = 0 #词典的IDF权值向量 self.tf = 0 #训练集的权值矩阵 self.tdm=0 #P(x|yi) self.Pcates = {} #p(yi)是一个类别字典,训练样本中0占多少比例,1占多少比例 self.labels= [] #对应每个文本的分类,是一个外部导入的列表 self.doclength = 0 #训练集文本数 self.vocablen = 0 #词典词长 self.testset = 0 #测试集 #导入和训练数据集,生成算法所必需的参数和数据结构 def train_set(self,trainset,classVec): self.cate_prob(classVec)#计算每个分类在数据集中的概率P(Yi) self.doclength = len(trainset)#训练集合的个数 print(self.doclength) tempset = set() #生成词典(去重后的词典,即训练样本中的所有词汇) [tempset.add(word) for doc in trainset for word in doc] print(tempset) #训练样本词典 self.vocabulary = list(tempset) #词典长度 self.vocablen = len(self.vocabulary) self.calc_wordfreq(trainset)#计算词频数据集 self.build_tdm() #按分类累计向量空间的每维值P(X|Yi) #计算在数据集中每个分类的概率P(Yi) def cate_prob(self,classVec): self.labels = classVec #输出各个分类 print(self.labels) #转成集合,去重,只有0,1 labeltemps = set(self.labels)#获取全部分类 print(labeltemps) for labeltemp in labeltemps: # 统计列表中重复的分类:self.labels.count(labeltemp) #0的比例占多少,1的比例占多少 self.Pcates[labeltemp] = float(self.labels.count(labeltemp))/float(len(self.labels)) print(self.Pcates[labeltemp]) #生成普通的词频向量 def calc_wordfreq(self,trainset): self.idf = np.zeros([1,self.vocablen])#1*词典单词数,统计的是所有的样本单词的次数 print(self.idf) self.tf = np.zeros([self.doclength,self.vocablen])#训练集文件数*词典数,统计的是每一个训练样本单词的次数 print(self.tf) #遍历训练集 for indx in range(self.doclength): # 遍历每一个训练样本中的每个词 for word in trainset[indx]: #相应位置上的单词+1,第indx行,self.vocabulary.index(word)列 #self.vocabulary.index(word)返回的是word在词典中的下标 self.tf[indx,self.vocabulary.index(word)] += 1 #整个词典的计数加1 for signleword in set(trainset[indx]): self.idf[0,self.vocabulary.index(signleword)] += 1 print(self.idf) print(self.tf) #按分类累计计算向量空间的每维值P(X|Yi) def build_tdm(self): self.tdm = np.zeros([len(self.Pcates),self.vocablen])#类别个数*词典长度 print(self.tdm) sumlist = np.zeros([len(self.Pcates),1])#类别个数*1 print(sumlist) #遍历所有的训练样本 for indx in range(self.doclength): #求同一类别的词向量空间值加总,加的是每一个训练样本对应的每个词的个数 self.tdm[self.labels[indx]] += self.tf[indx] #统计每个分类的总的词数 sumlist[self.labels[indx]] = np.sum(self.tdm[self.labels[indx]]) print(self.tdm) print(sumlist) self.tdm = self.tdm/sumlist#生成P(X|Yi),即求每个分类的单词,占该分类的所有单词总数的比例 print(self.tdm) #将测试集映射到当前词典 def map2vocab(self,testdata): #计算测试集的特征向量(非线性代数的特征向量,而是一行中对词的统计信息) self.testset = np.zeros([1,self.vocablen]) for word in testdata: self.testset[0,self.vocabulary.index(word)] += 1 #将预测分类,输出预测的分类类别 def predict(self,testset): #np.shape(testset)[1]列值 if np.shape(testset)[1] != self.vocablen:#如果测试集长度与字典不相同则退出程序 print("输入错误") exit(0) predvalue = 0 #初始化后类别概率 predclass = "" #初始化类别名称 #tdm是每一类某个单词,占该类的总的单词的比例,后面一个参数是所有类别 for tdm_vect,keyclass in zip(self.tdm,self.Pcates): #P(X|Yi) P(Yi) #变量tdm,计算最大分类值 print("---"*30) print(testset*tdm_vect*self.Pcates[keyclass]) temp = np.sum(testset*tdm_vect*self.Pcates[keyclass]) print(temp) #选择概率最大的一个 if temp > predvalue: predvalue = temp predclass = keyclass return predclass k=3 #夹角余弦距离公式 def cosdist(vector1,vector2): return dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2)) #kNN实现分类器 #测试集:testdata 训练集:trainSet 类别标签:listClasses k:k个邻居数 def classify(testdata,trainSet,listClasses,k): dataSetSize = trainSet.shape[0]#放回样本集的行数 print(dataSetSize) distances = array(zeros(dataSetSize)) print(distances) #计算测试集与训练集直接的距离:夹角余弦 for indx in range(dataSetSize): distances[indx] = cosdist(testdata,trainSet[indx]) #根据夹角余弦从大到小排序,结果为索引号 sortedDistIndicies = argsort(-distances) print(sortedDistIndicies) classCount = {} for i in range(k):#获取角度最小的前k项作为参考项 #按排序顺序返回样本集对应的类别标签 voteIlabel = listClasses[sortedDistIndicies[i]] try: classCount[voteIlabel] += 1 except: classCount[voteIlabel] = 1 print(listClasses) print(classCount) #对分类字典classCount按value重新排序 #sorted(data.iteritems(),key=operator.itemgetter(1),reversee=True) #该句是按字典值排序的固定用法 #classCount.iteritems():字典迭代器函数 #key:排序参数 operator.itemgetter(1):多级排序 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) print(sortedClassCount) return sortedClassCount[0][0]#返回序最高的一项 dataSet,listClasses = loadDataSet() nb = NBayes() nb.train_set(dataSet,listClasses) print("------"*20) #nb.tf:统计的是每一个训练样本单词的次数 print(classify(nb.tf[3],nb.tf,listClasses,k))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号