World 表:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| name | varchar |
| continent | varchar |
| area | int |
| population | int |
| gdp | bigint |
+-------------+---------+
name 是该表的主键(具有唯一值的列)。
这张表的每一行提供:国家名称、所属大陆、面积、人口和 GDP 值。
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
面积至少为 300 万平方公里(即,3000000 km2),或者
人口至少为 2500 万(即 25000000)
编写解决方案找出 大国 的国家名称、人口和面积。
按 任意顺序 返回结果表。
返回结果格式如下例所示。
示例:
输入:
World 表:
+-------------+-----------+---------+------------+--------------+
| name | continent | area | population | gdp |
+-------------+-----------+---------+------------+--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000000 |
| Albania | Europe | 28748 | 2831741 | 12960000000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000000 |
| Andorra | Europe | 468 | 78115 | 3712000000 |
| Angola | Africa | 1246700 | 20609294 | 100990000000 |
+-------------+-----------+---------+------------+--------------+
输出:
+-------------+------------+---------+
| name | population | area |
+-------------+------------+---------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
+-------------+------------+---------+
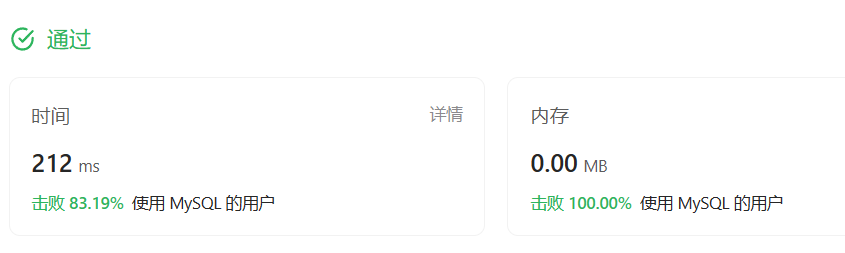
Mysql:查询中尽量不要使用or,会影响走索引
SELECT NAME,POPULATION,AREA FROM WORLD WHERE AREA >= 3000000 UNION
SELECT NAME,POPULATION,AREA FROM WORLD WHERE POPULATION >= 25000000;
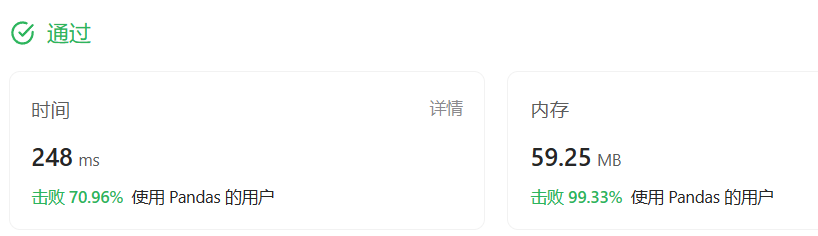
Pyhton基本格式:df.loc[对行筛选, 对列筛选]
import pandas as pd
def big_countries(world: pd.DataFrame) -> pd.DataFrame:
return world.loc[(world['area'] >= 3000000) | (world['population'] >= 25000000),['name','population','area']]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号