“最简单”的爬虫开发方法
背景:
本人接触python爬虫也有一段时间了,期间也有许多小伙伴和我探讨python爬虫怎么学习,因此写下这篇随笔,算不上教学,只是谈谈自己的想法。
实现爬虫的方法有很多,我选取了个人觉得最容易理解、实现的方法。本篇随笔涉及的爬虫知识不多,难度主要在安装相应的库上面!
一、开发环境:
python3、xpath+Selenium
二、安装
如果你已经有了pip管理工具了:(其他安装方法自行百度)
1 pip install selenium
1 pip install lxml
python爬虫中的xpath具体使用请参考:https://www.cnblogs.com/lei0213/p/7506130.html
selenium具体使用请参考:https://blog.csdn.net/weixin_36279318/article/details/79475388
三、案例
本次已爬取猫眼电影-Top100榜为例,目标链接:http://maoyan.com/board/4
第一步:使用selenium获取目标页面的源代码
1 from selenium import webdriver 2 # 本人phantomjs驱动的路径 3 driver = webdriver.PhantomJS('D:\phantomjs-2.1.1-windows\phantomjs.exe') 4 url = 'http://maoyan.com/board/4’ 5 driver.get(url) 6 html = driver.page_source 7 print(html)
第二步:使用xpath获取我们想要的信息
本次我们就爬取电影排名和电影名称。
首先我们打开开发者工具,选择要素找到排名的位置
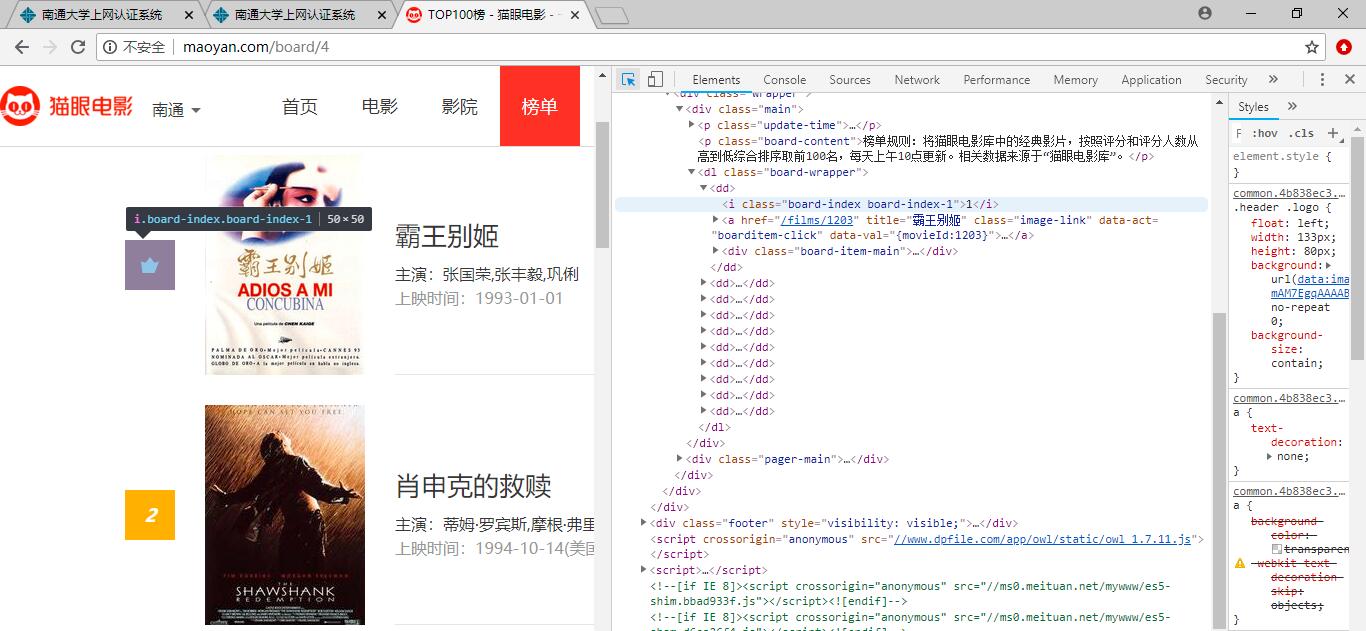
然后选中相应HTML语句右击copy-copy xpath
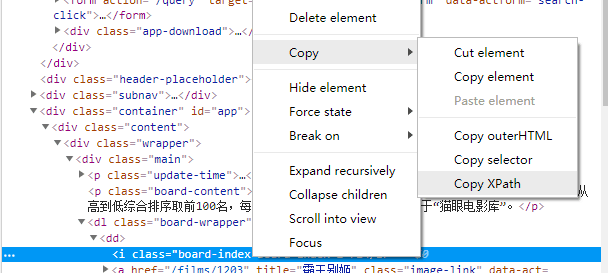
我们选取几个比较一下,很容易得到电影排名的路径://*[@id="app"]/div/div/div[1]/dl/dd/i

如法炮制我们获得电影名的路径://*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a
1 wb_date = driver.page_source 2 html = etree.HTML(wb_date) 3 name_result = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') 4 rank_result = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/i') 5 for i in range(len(rank_result)): 6 print(rank_result[i].text, name_result[i].text)
就这样我们很轻松的爬取了当前页面的排名

接着我们看一下分页的爬取,我们点击下一页,不难发现URL发生了改变(例:http://maoyan.com/board/4?offset=10),多了offset的参数,可以发现这里的offset就是代表分页,因此我们给目标链接出入offset参数,便可以实现其他90部电影的爬取。
1 def get_result(offset): 2 url = 'http://maoyan.com/board/4?offset=' + str(offset) 3 driver.get(url) 4 wb_date = driver.page_source 5 html = etree.HTML(wb_date) 6 name_result = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') 7 rank_result = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/i') 8 for i in range(len(rank_result)): 9 print(rank_result[i].text, name_result[i].text) 10 11 if __name__ == '__main__': 12 for i in range(10): 13 offset = i * 10 14 get_result(offset) # 为了避免对目标网站造成麻烦,我们可以在这里sleep一下
四、小结
本篇随笔只是简单的介绍了如何快速定位元素在XML文档中的位置,和简单的使用xpath+Selenium。掌握了xpath+Selenium,我们就能爬取很多网站了。当然现在很多网站都有了各式各样的反爬,我们一步步破解反爬的过程不也正是爬虫的乐趣所在!希望读者能够通过本篇文章了解到什么是python爬虫,及爬虫的简单的实现,并能从中找到乐趣!掌握了如何获得数据,我觉得最重要的还是如何处理我们爬取的数据!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号