MySQL中的索引
索引是一种为了加速对表中数据行的检索而创建的数据结构。
2. 唯一索引:加速查询 + 列值唯一(可以有null);
3. 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个;
4. 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并;【最左匹配原则】
5. 全文索引:对文本的内容进行分词,进行搜索;
6. 覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖;
MySQL中索引类型常见的有两种:B+树、Hash表
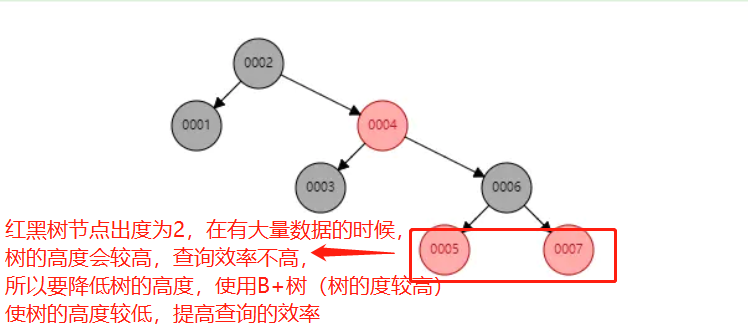
Q:为什么不用二叉树或红黑树?
不使用二叉树的原因:数据库在插入数据前要先维护索引,如果插入的数据中索引是递增的,那么索引就演变成一个链表,在查找的时候相当于全表扫描,没有意义。
不使用红黑树的原因:因为红黑树的度为2,所以红黑树中当表中的数据很多时,红黑树的高度会比较高(一百万条记录,结点都存满了,树高大概是20)
那么当要查找的数据在叶子结点的时候,就可能要找十几次,效率太低。
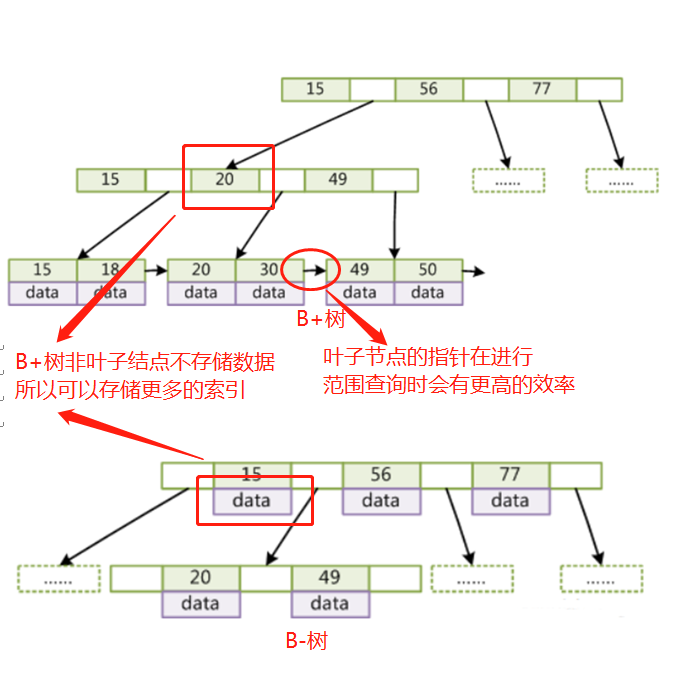
Q:为什么使用B+树而不是B-树?
B+树非叶子结点不存储data,只存储索引(冗余),所以可以放更多的索引。同时B+树的叶子结点用指针连接,可以提高区间访问的性能(如使用where id > =20 进行范围查询时,先找到20这个结点,再可以通过叶子结点的指针将其他结点取出来)
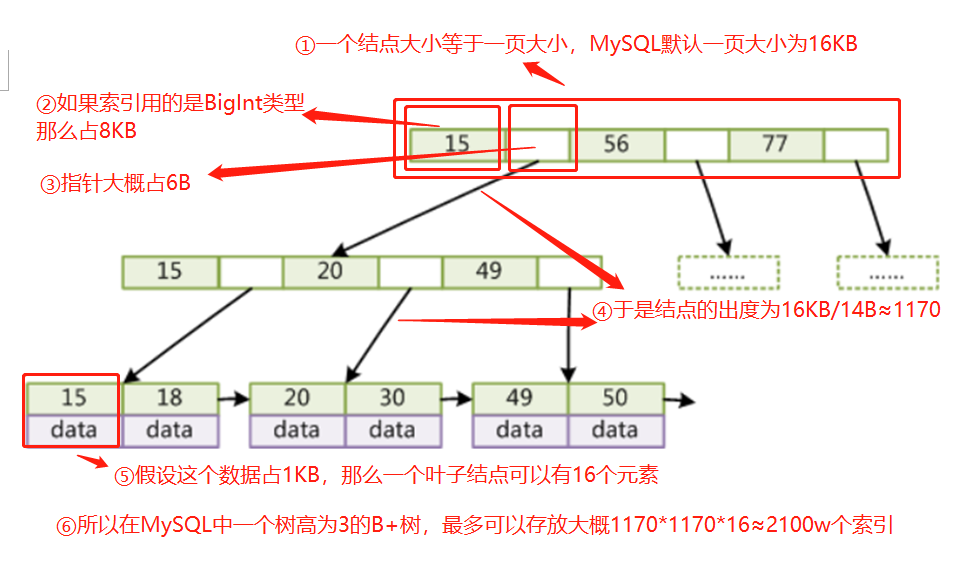
拓展:根据磁盘预读原理,B+树将一个节点的大小设为一个页的大小,MySQL中默认设置一页的大小是16KB,如果索引用的是BigInt(大小为8B),那么加上指针(大概是6B),一个结点大概可以存储16KB/(6B+8B)≈1170个元素,假设叶子结点存储的数据为1KB,那么当树高为3时,总共大概可以存储1170*1170*16≈2190万个索引。也就是说树高为3时,可以支撑千万级表的快速查找。
Q:用Hash表做索引的数据结构有什么不好的地方?
因为Hash索引比较的是进行Hash运算后的Hash值,所以只能用于等值的过滤。而且经过Hash算法运算后的Hash值的大小关系并不一定和原始数据的大小关系一样,所以无法用来做范围查询,只支持等值比较查询(in,=,<=>)。对于组合索引,哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引的全部列值内容来计算哈希值的。如:数据列(a,b)上建立哈希索引,如果只查询数据列a,则无法使用该索引。另外不同的索引键可能存在相同的Hash值,所以即使找个相同Hash值的记录,也无法从Hash索引中直接完成查询,还是要通过进行表扫描,通过访问表中的真实数据进行相应的比较并得到相应的结果。
详细点看:https://www.cnblogs.com/xiaoboluo768/p/5164342.html
常见的两种数据库存储引擎(MyISAM、InnoDB)的索引实现:
#数据库存储引擎是用来形容表的
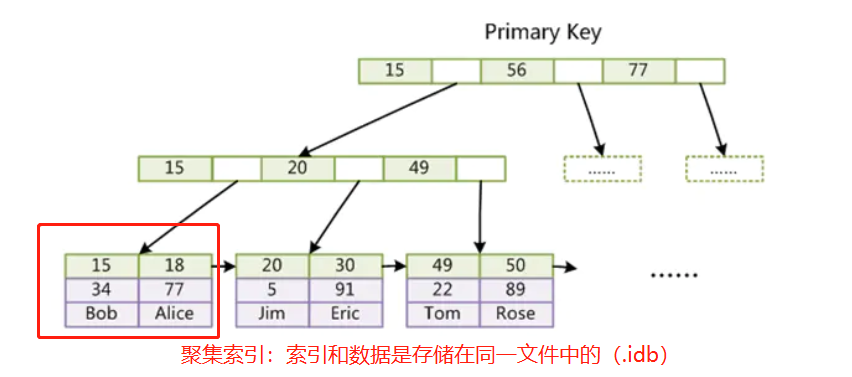
MyISAM存储引擎索引实现
-
MyISAM索引文件和数据文件是分离的(非聚集)
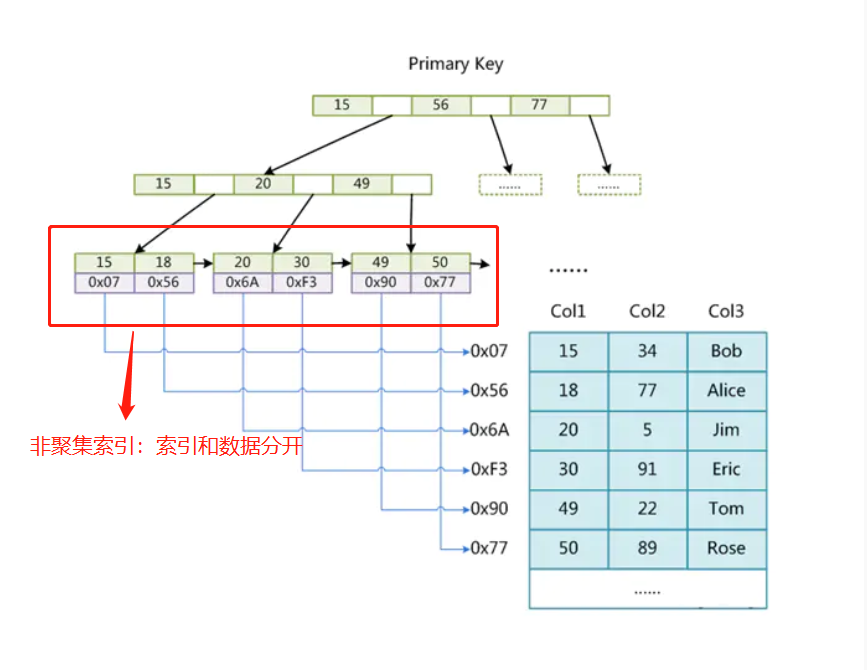
InnoDB索引实现(聚集)
- 表数据文件本身就是按B+树组织的一个索引结构文件
- 叶子结点包含了完整的数据记录(聚集索引和非聚集索引的区别:索引文件和数据文件是不是分开存储的,InnoDB使用聚集索引,MyISAM使用非聚集索引,聚集索引查找效率比非聚集索引高)
- InnoDB表必须有主键(MySQL如果建表的时候没建主键,会找可以建唯一索引的一列作主键,如果找不到可以标识唯一数据的一列,那么会在表里默认加一列数据,在后台维护唯一的主键索引),并且推荐使用整型的自增主键(整型占用的磁盘空间少而且进行比较的效率高于其他数据结构(如字符串等),因为B+树的叶子结点是从左到右是依次递增的,如果不用自增的主键,那么在插入记录维护索引的时候,就有可能因为结点16KB已经放满而进行结点分裂和树平衡,这会带来性能的开销,而自增的主键永远往右边的结点加元素,那么造成结点分裂的概率就会非常小)
- 非主键索引结构叶子结点存储的是主键值(保证一致性和节省存储空间)
用MyISAM的表由三个文件组成:.frm(表结构文件) .MYD(表的数据文件) .MYI(表的索引信息文件)
用InnoDB的表由两个文件组成:.frm(表结构文件) .ibd(包含数据和索引信息)
联合索引:对多个字段同时建立的索引
很多都是看诸葛老师的视频学到的:https://www.bilibili.com/video/av73372462


 浙公网安备 33010602011771号
浙公网安备 33010602011771号