Jmeter 参数化方式、提取上个接口的参数、函数助手常用的函数(用户定义的变量、CSV数据文件设置、用户参数、JSON提取器、正则表达式提取器)
一、在测试过程中一般的几种参数化方式
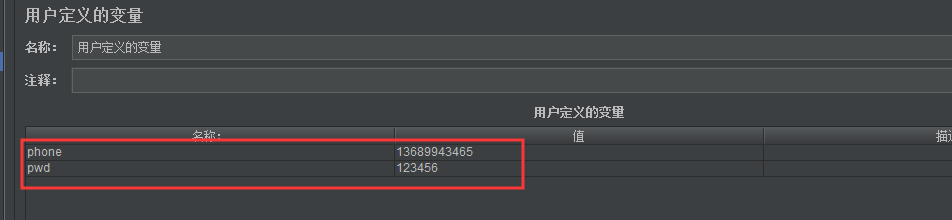
1、用户定义的变量
当我们每次去调用接口都要手动修改手机号码,并且注册和登录接口都要同步修改,这样操作相当繁琐,针对这个问题我们使用用户定义的变量的工具进行优化
添加:在线程组上:右键—>添加—>配置元件—>用户定义的变量
-
- 用户自定义变量是固定的,与下面的“用户参数”有点不同(比如:${__Random(1000,9999,)},多个虚拟用户请求时,生成的四位数都是固定同一个)

我们把注册和登录的手机号和密码都提取出来放到这里
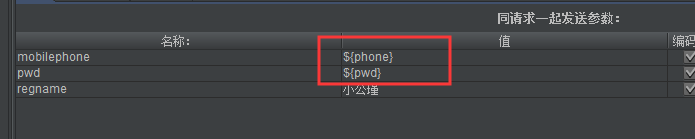
定义了之后,我们需要调用该参数,调用方式是在对应的取样器里,使用${key}的格式替换取样器请求体里的值,这样我们就可以每次只修改一次就可以在所有的接口上通用了
虽然在此基础上已经得到了相应的优化,我们能不能做到每次运行的时候都不用去修改用户定义的变量里面的值呢?答案是可以的,这时候我们要使用到函数助手,构造相应的随机函数

对于函数的各种用法,这里不做说明,可以通过函数助手的帮助去查看各个函数的使用方法

我们通过函数助手来构造一个生成随机手机号的方法来替换用户定义的变量的值

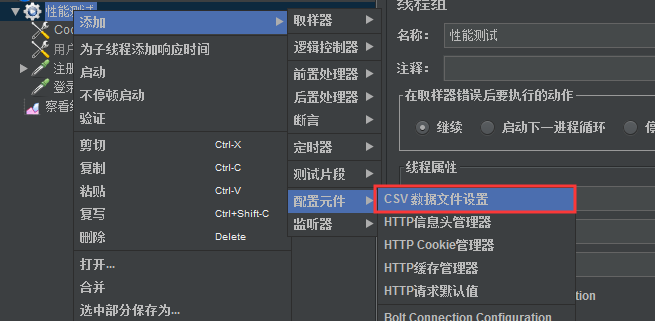
2、CSV数据文件设置
该方法也是参数化的一种场景,我们可以提前使用csv文件或者其它文本文件(txt、log、xml、json...)构造大量数据,然后再读取文件里面的内容引用到对应的接口当中去,这里要注意的是在国内csv我们使用excel编辑器保存后遇到中文会出现乱码的情况,因此需要进行转码后才能正常使用!
在线程组上:右键—>添加—>配置元件—>CSV 数据文件设置
我们先构造测试数据

然后配置CSV数据文件设置:

此时我们可以直接替换接口参数的值为该变量名称,但是不可以替换用户定义的变量的值,会引用不到

执行结果如下:
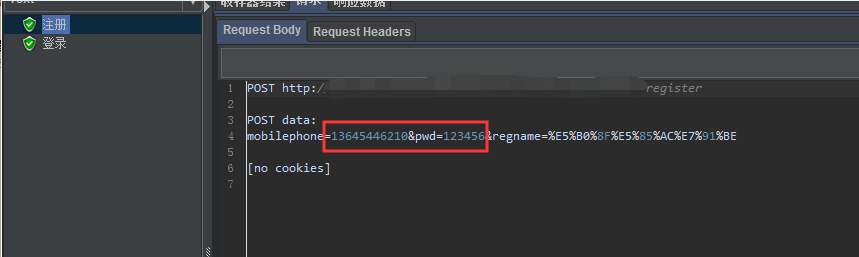
我们如果设置并发量为5,则会依次读取每一行数据
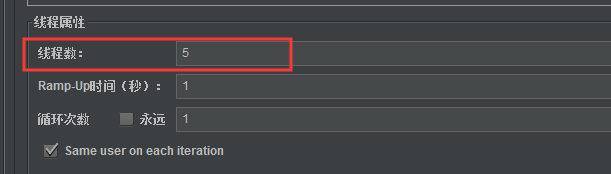
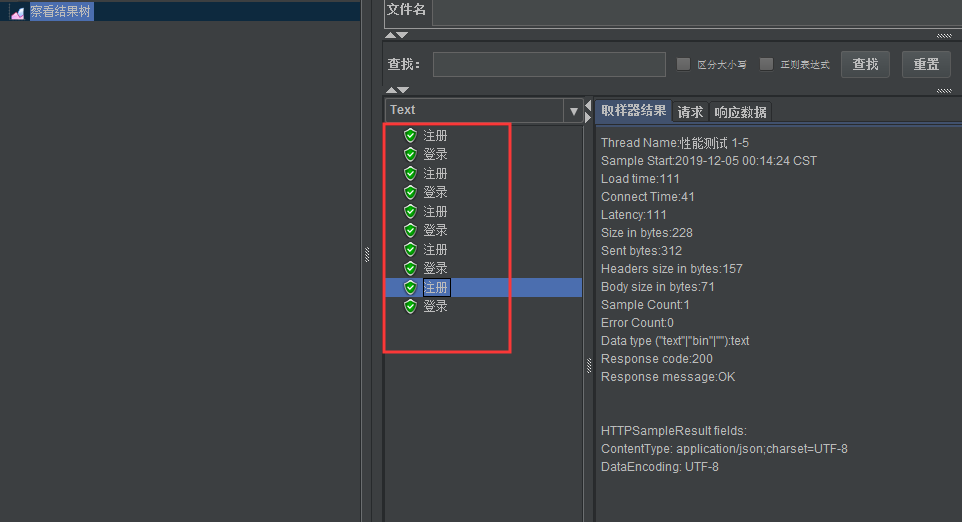
3、用户参数
在用户定义的变量中使用随机生成手机号的方式执行,它的执行原理是在整个线程组执行会话之前创建一次后,执行过程中的所有线程都会去使用这个值,并不是每个线程组使用时都会随机生成不一样的值,所以在并发测试中,遇到这种情况就不行了,因此我们可以用户参数的工具来使得每个线程组调用的时候都能随机生成一个随机数
- 用户参数是随机生成的,于上面的 “用户自定义变量” 有点不同(比如:${__Random(1000,9999,)},多个虚拟用户请求时,生成的四位数都是随机生成的)
- 使用 ${名称} 进行调用参数
在线程组上:右键—>添加—>前置处理器—>用户参数
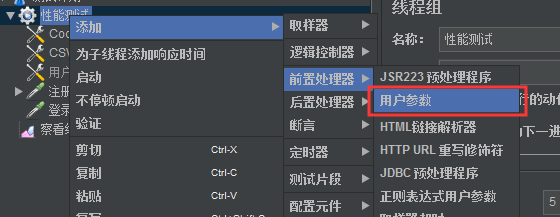
我们可以将上面用户定义的变量中由函数助手生成的函数拿到用即可

我们将接口参数化替换

设置并发为10,查看结果:
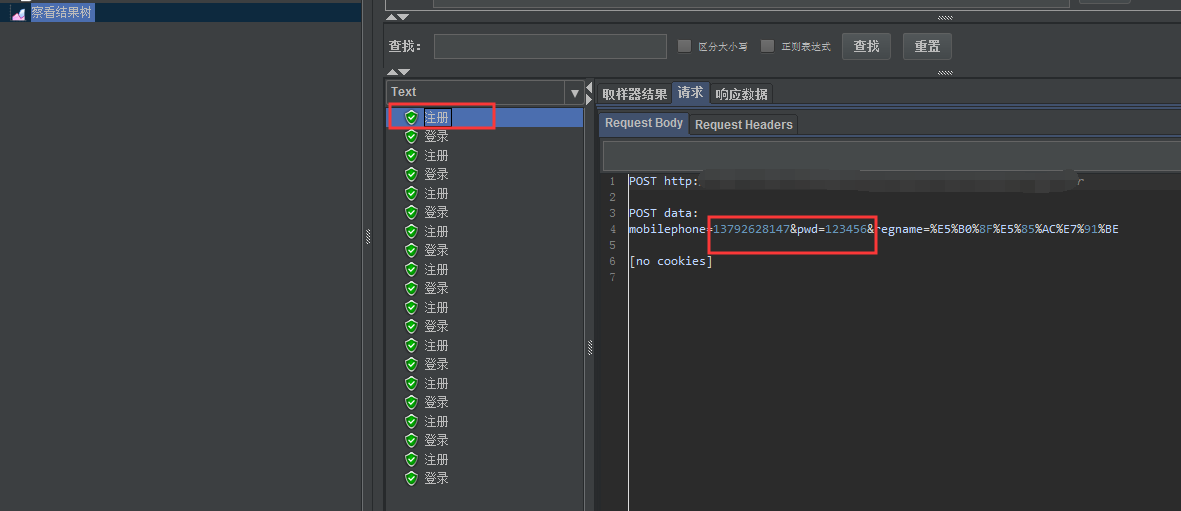
二、正则提取
上面我们处理的是随机数,这里我们则要通过一些方法将下个接口要使用的参数用上个接口的请求体、响应头或者响应体中提取出来,以此来处理接口依赖的问题,因为暂时没有好的实例,这里只讲使用方法
1.JSON提取器
- json 格式参数
- 格式:{"key":"vale":"名称":"值"}
- value值为string 要用双引号""
- value值为int 不要双引号""
- value值为 double 不要双引号""
- 多个key-value 对,使用用逗号分开
- 最后一个key-value 对后面没有逗号
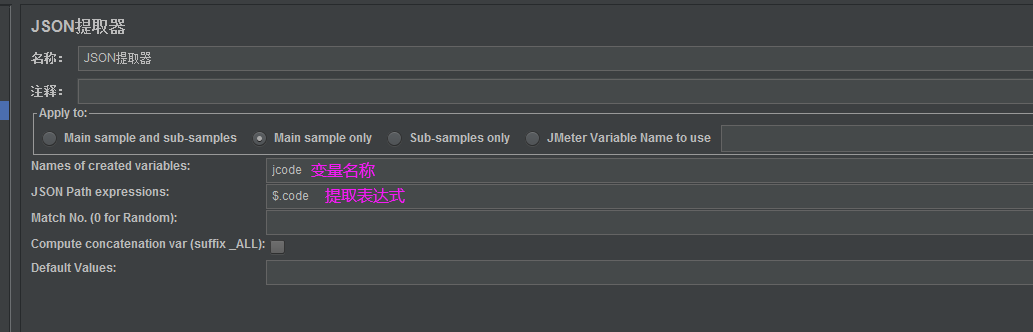
在指定的接口取样器上:右键—添加—后置处理器—JSON提取器
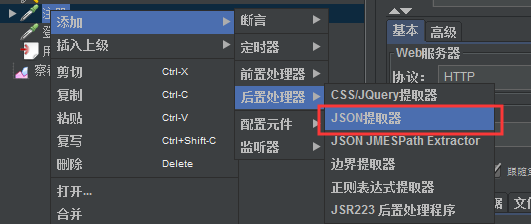
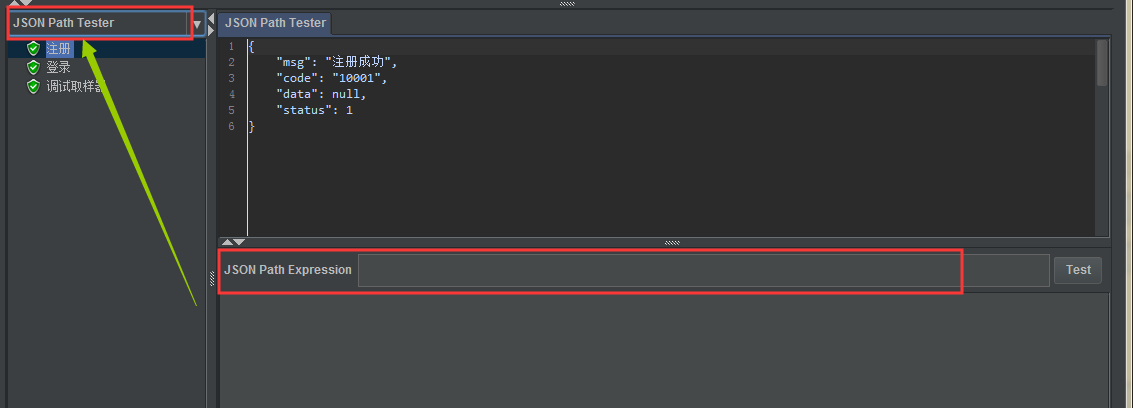
我们在查看结果树里面将JSON Path Tester调出来,可以进行编写表达式进行测试验证表达式是否正确,注意该提取器只适用于接口的json响应体
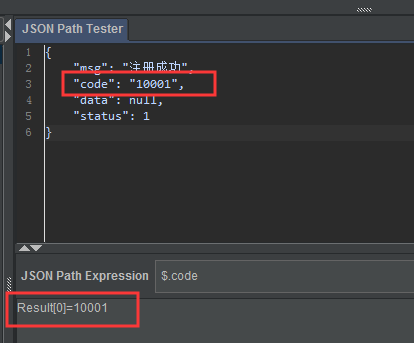
JSON提取器的表达式语法格式为:$.key的格式
如果响应体遇到嵌套列表的形式,如:
{"domain":
[
{"id": "sdfhhsdfafvgg"},
{"name": "Tom"}
]
}
如果要提取name的值,表达式为:$.domain[1].name

{
"tenant": "admin",
"domain": [
{"id": "sdfhhsdfafvgg", "name": "Tom"},
{"id": "234gdgdh45h", "name": "Jerry"}
]
}
如果要提取所有name的值,表达式为:$..name 返回结果为一个列表
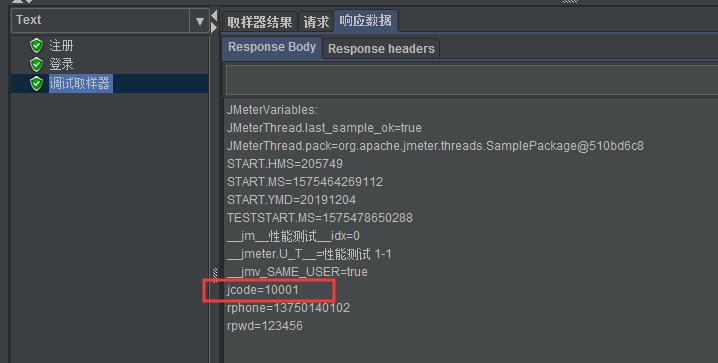
我们将正确的表达式填入到JSON提取器的配置当中,后面的接口就可以通过${变量名称}的方式调用该参数
2.正则表达式提取器
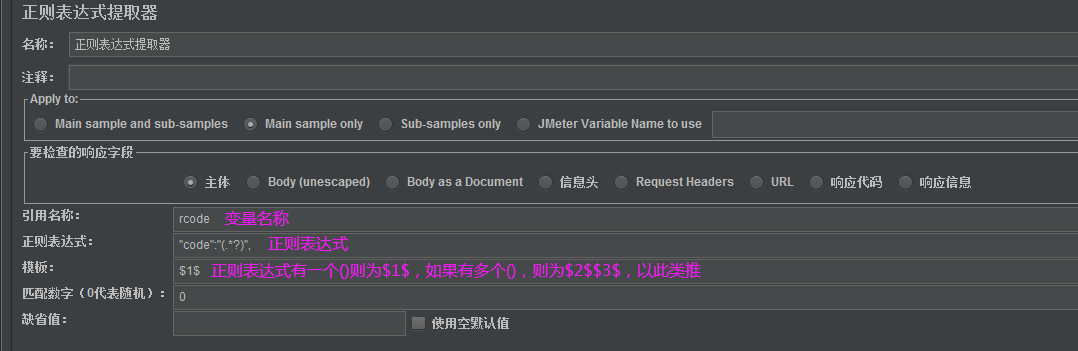
在指定的接口取样器上:右键—添加—后置处理器—正则表达式提取器

正则表达式的格式:左边界(.*?)右边界 以code为例:
- 0:随机
- -1:匹配所有
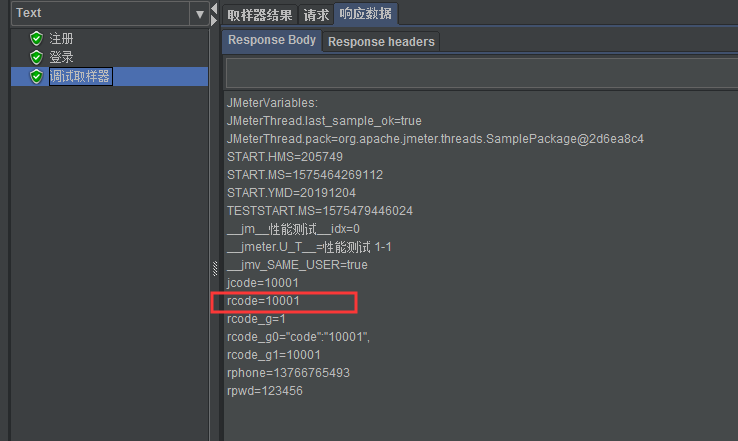
我们执行一次查看提取结果:
正则表达式提取器 》页面
Apply to 应用范围
-
- Main sample and sub-samples
- 当前请求的结果和当前请求的子请求的结果,两方面去匹配
- Main sample only
- 当前的请求
- Sub-samples only
- JMeter Variable
- jmeter 二次提取
- Main sample and sub-samples
引用名称
-
- 其他地方引用时的变量名称,我这里写的phone,可自定义设置,引用方法:${引用名称}
正则表达式
-
- 数据提取器,()括号里为你要获取的的值。"mobilephone":"( 相当于LR左边界, )","leaveamount"相当于LR右边界。而括号里\d+为正则表达式,用来匹配所需要获取的数据,何谓正则表达式文章末尾会附上说明
模板
-
- $$对应正则表达式提取器类型。-1全部,0 随机,1第一个2第二个,以此类推,若只有一个正则一般就填写$1$
匹配数字
-
- 正则表达式匹配数据的所有结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。-1表示全部,0随机,1第一个,2第二个,以此类推。若只要获取到匹配的第一个值,则填写1
缺省值
-
- 匹配失败时的默认值。可以不写。若需用于后续逻辑判断,可简单写为 ERROR。
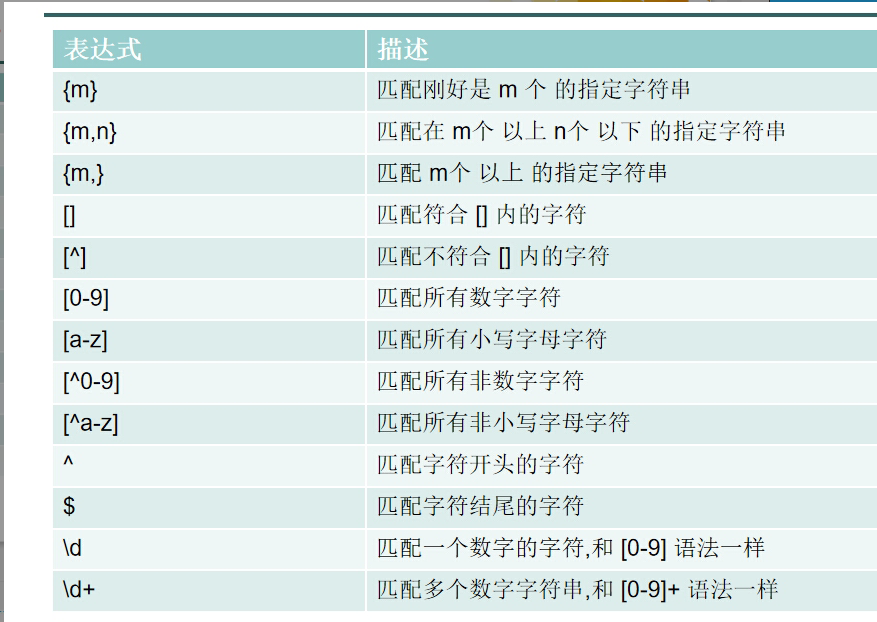
常用正则表达式:
- ():表达式的开始结束
- .*:匹配 0次或者 多次的任何字符
- \d+:匹配多个数字字符串,和 [0-9]+ 语法一样
- \w+:英文字母或 数字 的字符串,和 [a-zA-Z0-9]+ 语法一样
- 用 $$ 引用起来,只想用第一个用 $1$ ,如果在正则表达式中有多个正则表达式,则可以是 $2$ $3$ 等等;
更多关于正则表达式的语句请跳转到此博客地址:https://www.cnblogs.com/shouhu/p/12165289.html
三、函数助手常用的函数
- 位置打开:Tools > 函数助手
- 常用函数random.、time.、v函数
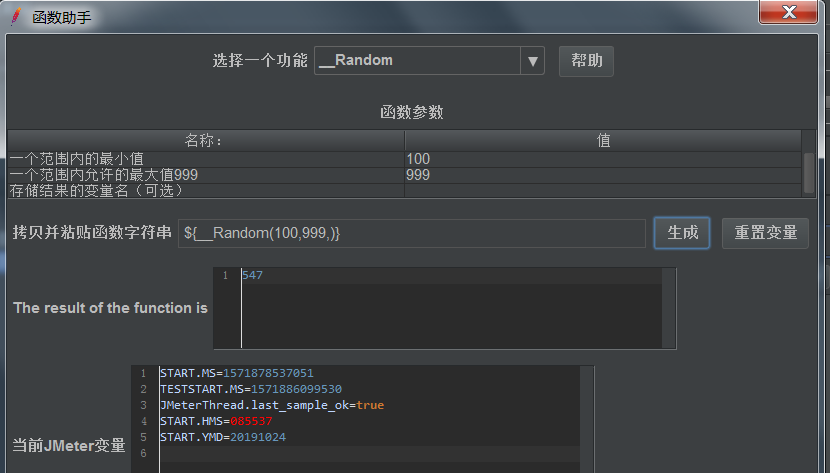
__Random:随机动态生成数(译:瑞德姆)
设置最小值,最大值 > 生成 > 复制后添加到用户定义的变量或者用户参数中
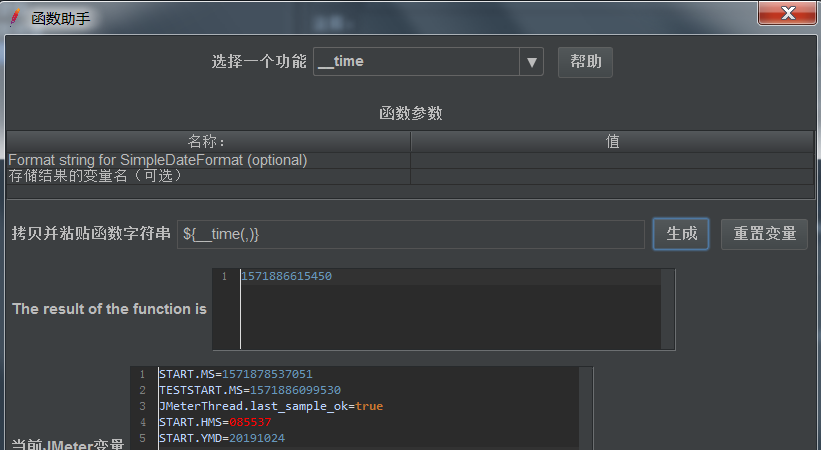
__time:当前时间函数
- 如果参数需要为当前日期,那公式为: ${__ time(yyy-MM-dd,)} 或者${__ time(YMDHMS.,)}
- ${__ time/yyyy-MM-dd HH:mm:ss:SSS,time)} :格式化生成时间格式2018-06-01 11:08:23:635
- ${__ _time()}: 默认该公式精确到毫秒级别,13位数 1527822855323
- ${__ _time(1000.)}: 该公式精确到秒级别,10位数 1527822871
三种时间格式:
- YMD = yyyyMMdd
- HMS = HHmmss
- YMDHMS = yyyyMMdd-HHmmss
- 时间格式:yyyy-MM-dd HH:mm:ss.SSS >> 生成格式:2019-10-22 21:51:17.456
1、默认生产为时间戳
2、添加时间格式:yyyy-MM-dd HH-mm-ss
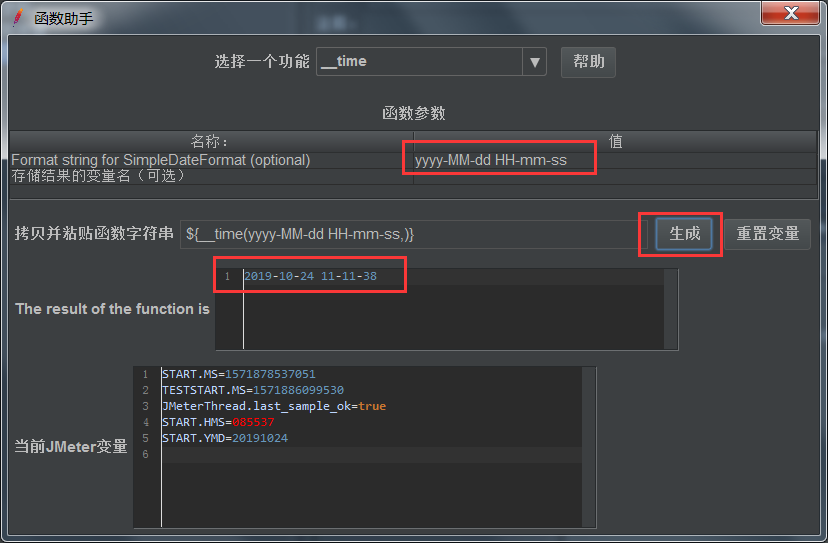
以上可以作为开始时间,那么结束时间呢?
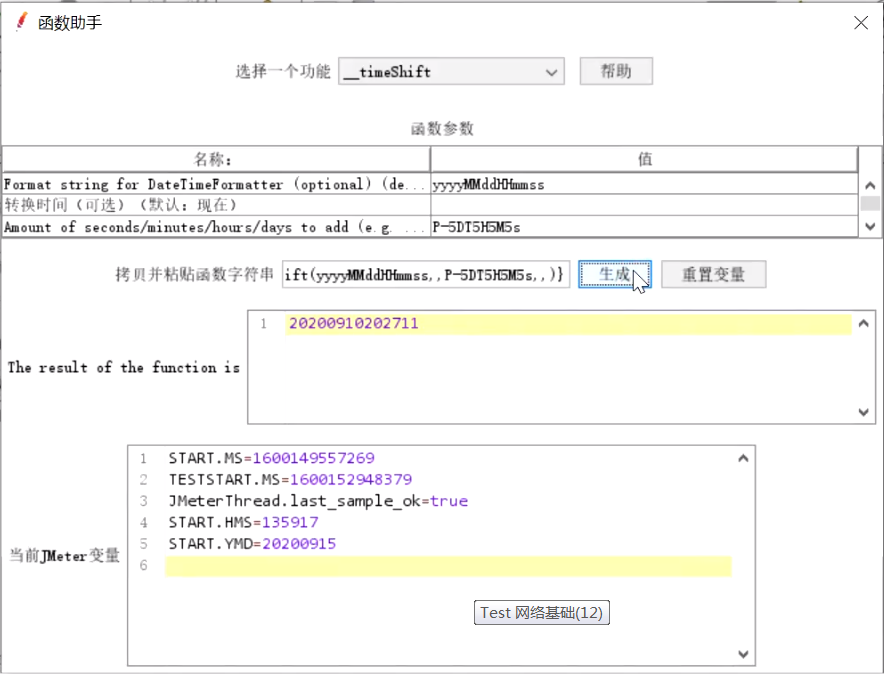
怎么在开始时间上增加 2天 == 时间位移函数:__timeShift
__timeShift():时间位移函数
格式:yyyy-MM-dd HH-mm-ss
-P5D5:负号后面都进行减时间
PT5h5m5s.89s:只转换时间,日期不变

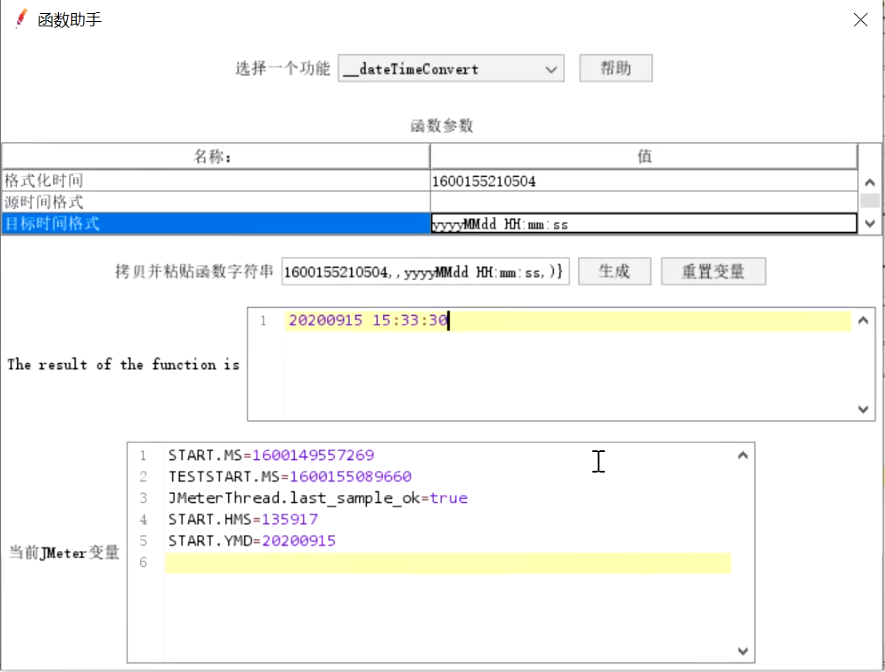
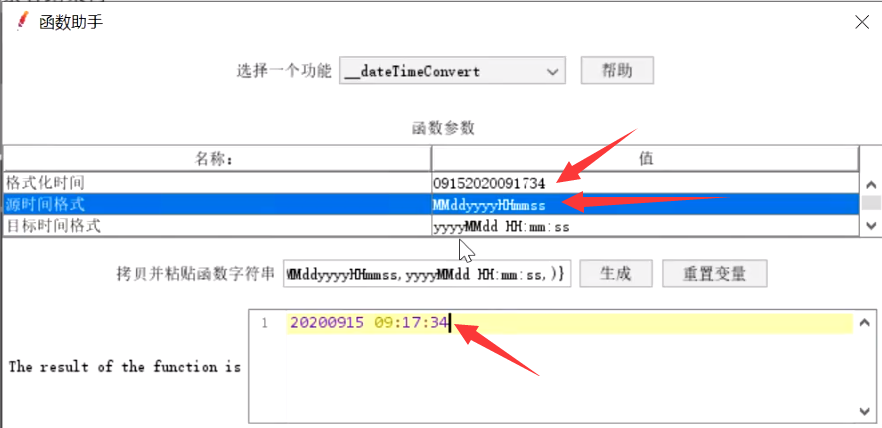
--dataTimeConvert:时间戳转换为时间


__V:嵌套函数
已经定义了一个变量A要再在这个变量名后面加一个变量(如递增数字)N不能直接用${A${N}},必须用嵌套函数
-
- __ V: ${_ _V(A,${N}}脚本调优
__setProperty():设置jmeter 属性

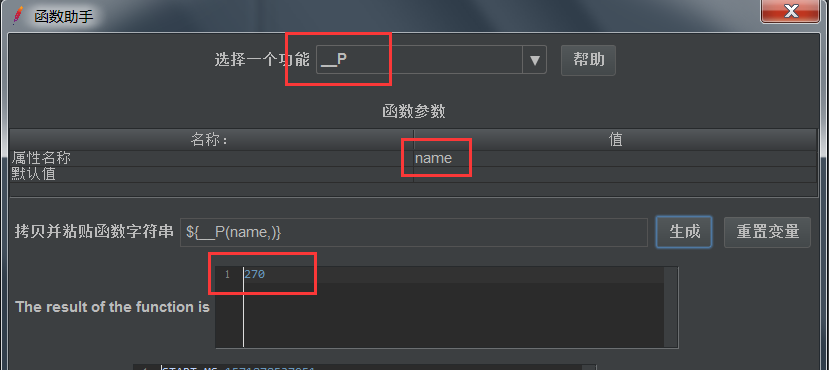
__P:获取属性-----获取 __setProperty()函数的属性值
跨线程组的时候可以用
MD5:密码加密

可以查看函数助手的帮助文档,建议用谷歌浏览器


 浙公网安备 33010602011771号
浙公网安备 33010602011771号