
【原创】海量数据处理问题(一) ---- 外排,堆排,K查找的应用
这篇博客源自对一个内存无法处理的词频统计问题的思考,最后给出的解决办法是自己想的,可以肯定这不是最好的解法。但是通过和同学的讨论,仍然感觉这是一个有意义及有意思的问题,所以和大家分享与探讨。
如果有误,请大家指正。如果有更好的方法,望不吝赐教。
1、提出问题
实际问题:
当前有10T中文关键词数据,需要统计出词频最高的1000个词。可用的只有1G内存和磁盘。那么如何提取?
大概估算一下这个问题,设中文词汇平均长度2.3,每次汉字用utf-8编码是3B,那么10T数据大概有 10T/7B ~ 1.4 * 2^40 条词汇。
1G内存即便对词汇一 一对应,再加上4B的整形记录词频,那么1G内存可以最多纪录 1G/4B * 2^8 ~ 2^36 条词汇。所以即便最理想的hash(一 一对应)也无法将所有词汇对应到1G内存中。
抽象问题:
假设当前内存只能存放1000个词,但是一共有100w词汇需要处理,问如何返回前100个高频词汇?(只能使用单机内存和磁盘)
下面我们以抽象的问题为基础进行分析。
2、提炼解决办法
这个问题大的方向有两步,1 、 统计词频(重点思考) ; 2 、返回topK。
如果这两步中涉及的数据都能放入内存中,那么最不济 O(N^2) 便可以解决。不过由于内存无法承受,这两步的解决都出现了问题。
2.1 统计词频
2.1.1 压缩数据(不可行)
由上所诉,如果能压缩放入内存便可以解决问题。所以先考虑能否找到一种压缩数据的办法。但是通过上面的分析,即使转换为hash也无法存入内存,所以需要换一种思路。
2.1.2 归并统计(不可行)
既然hash不能把所有数据放入内存,那么至少可以放一部分。再加上利用磁盘的存储,把hash值在一定范围内的词存放到第 i 个文件中。这样每个文件直接互不相交,而且每个文件都能在内存中处理,一个一个文件的进行统计,那么统计词频的问题自然可以解决了。
这个想法看似可行,其实不然。
对于抽象问题所述,100w/1000 = 1000,所以至少需要1000个文件存放互不相交的词。但是这里有两个问题,1 是如何寻找这个hash函数,保证100w个词在hash后能平均分配到1000个文件中。 2 是需要保证这个hash函数不会产生冲突,不然的话会导致不同的词的统计到一起。
因此这个hash函数是比较难找的。(如果大家知道分享下啊)
2.1.3 仍然是归并(可行的解决办法)
上述2中的归并,是需要人为的把词分到不同的桶里。但是hash函数太难设计了。
不过受《数据结构》书中对数值外排序的启发,我想到了类似归并排序的解决办法。
即对于抽象问题所述,首先按内存大小,把100w数据顺序分词1000份,这1000份是均匀大小的桶,上述2.1.2中难以实现的均分桶在这里可以很简单的实现。对于每个桶中的数据,因为每个词在内存中对应了一个2进制数值,可以通过移位比较两两词之间的数值大小。这样,词直接可以进行比较了,因此就可以进行排序了。再利用外排序的方法,就可以构成一个归并的解,因此可以将所有词汇进行词频统计。
时间复杂度为 O(M/N * log(N) + M *log(M/N) ) 。(M是所有数据量,N是每个桶中的数据量)
具体到抽象问题,即 O( 100w/100 * log(1000) (排序) + 100w * log(100w/1000) (归并) ) 。
2.2 返回topK
topK的方法有两种,一是 堆排序。 二是 K查找。
二者对比:
堆排序 K查找
时间复杂度 O(logN) O(N)
空间复杂度 O(K) O(N) (K就是topK的K)
topK结果 有序 无序
2.2.1 堆排序(适合本题)
对于提到的抽象数据,使用堆排序更合适。首先拿出第一个文件中的1000条数据构造一个 top100的堆树。然后剩下的999个文件,每次从每个文件取500条数据放入内存,和top100的堆树重新构造堆。那么需要一遍文件读取就能得到top100的词。所以对于文件读取为主要时间消耗的外排来说,堆排序无疑更合适。
本题时间复杂度 100*log100 + 100w * log100 + 1000 read file time
2.2.2 K查找(不可行)
似乎关于K查找相关文章不多,这里提一下。
K查找类似快排,因为快排的每一趟处理,都会得到枢纽值得位置,如果这个位置正好为所求的K,便可以返回topK的结果。
算法大概思想:一个头指针,一个尾指针。选择某值作为平衡点,调整平衡点两边数值位置(到这里和快排一致)。然后根据平衡点和K值的关系,选择头一半或尾一半进行上述递归的查找(快排是两边都查找)。直到平衡点和K相等退出。可见K值只是划分了两个边界,每一个边界内的数据并不是有序的。
因此K查找的时间复杂度: N + N/2 + N/4 ... 1 ~ 2N ,为 O(N)
K查找代码如下:
1 int Kfind(int array[], int lowPos, int highPos, int K){ 2 int first = lowPos; 3 int last = highPos; 4 int key = array[first]; 5 while(first < last){ 6 while(first<last && array[last]>=key) 7 last--; 8 array[first] = array[last]; 9 while(first<last && array[first]<=key) 10 first++; 11 array[last] = array[first]; 12 } 13 array[first] = key; 14 if(first == K-1) 15 return first+1; 16 if(lowPos < first && first > K-1) 17 return Kfind(array, lowPos, first-1, K); 18 if(first < highPos && first < K-1) 19 return Kfind(array, first+1, highPos, K); 20 }
测试样例及结果:
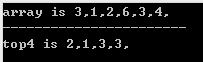
可见,topK内的数据并不一定有序。
但是对于本题,如果强行在文件中直接进行K查找,那么时间消耗会非常大。因此不适合。
3、扩展
如果本题不限制完成条件,使用hadoop的MapReduce框架很适合解决本问题,词之间没有联系,分治是很好的选择。
当然,即使对于单机环境来说,词频统计也已经不算大数据量了,但是作为一个问题思考还是有意义的。
转载请注明出处,谢谢~ http://www.cnblogs.com/xiaoboCSer/p/4202394.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号