编码问题
编码问题
字符编码:将字符映射到一个二进制字符串的过程,有各种映射规则,如最早的ASCII,国际通用的unicode等。
编码单位:最小是二进制位bit,8位是一个字节Byte(计算机存储信息的基本单位)
在硬盘和网络上传输的字符串都是bytes类型。
ASCII
存储统一码的低字节,每个字符占一个字节(8-1=7位)。
比如,"1"的统一码是0x0031,其ascii码是49。"2"的ascii码是是32,"a"的ascii码是97,"A"的ascii码是65。
文本文件写入字符“111”即写进3个49的二进制字符串,因为文件保存的是字符的编码。
后来发展为国际标准 ISO-646。
URL编码
url编码就是一个字符ascii码的十六进制
比如“”,它的ascii码是92,92的十六进制是5c,所以“”的url编码就是%5c。
那么汉字的url编码呢?很简单,看例子:“胡”的ascii码是17670,十六进制是BAFA,url编码是“%BA%FA”
对应字符举例:
? : %3F
& : %26
| : 4
十六进制值
1. + URL 中+号表示空格 %2B
2. 空格 URL中的空格可以用+号或者编码 %20
3. / 分隔目录和子目录 %2F
4. ? 分隔实际的 URL 和参数 %3F
5. % 指定特殊字符 %25
6. # 表示书签 %23
7. & URL 中指定的参数间的分隔符 %26
8. = URL 中指定参数的值 %3D
URLEncoder.encode("http://localhost:8080/user/token/03e6c681-bd8a-4478-a1f7-04ce03a15d7b", "UTF-8");
unicode编码 万国码(ISO-10646)
每个字符占用2个字节。
把properties中的所有unicode编码转为汉字
C:\Users\issuser>native2ascii -reverse
\u6d4d\u8bd5
浍试
\u64b\u8bd5
\u64b试
\u6d4b\u8bd5
测试
C:\Users\issuser>d:
D:\>native2ascii -reverse pkgs.properties pkgs2.properties
D:\>
https://zhidao.baidu.com/question/2203107954435944748.html
utf-8编码
1 个汉字字符存储需要3个字节,1 个英文字符存储需要 1 个字节。
如“学”对应 “-27, -83, -90” ,而英文字母 “J” 对应 “74” 。
汉字对应的字节值为负数,原因在于每个字节是 8 位,最大值不能超过 127(2的8次方-1),而汉字转换为字节后超过 了127(用了第8位),会溢出,以负数的形式显示。
gbk 编码 中国的
1 个汉字字符存储需要 2 个字节,1 个英文字符存储需要 1 个字节。如“学”对应 “-47 -89” ,而英文字母 “J” 对应 “74” 。
GB2312中文系统浏览器都默认用它解码。修改为其他解码方式,参考下图:
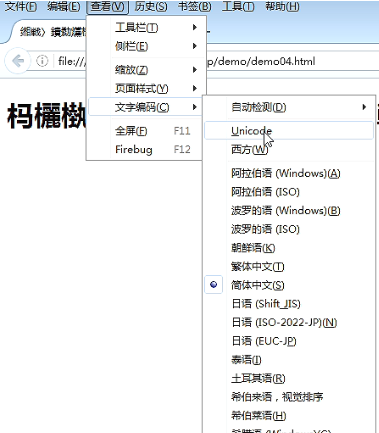
编辑器修改参考:
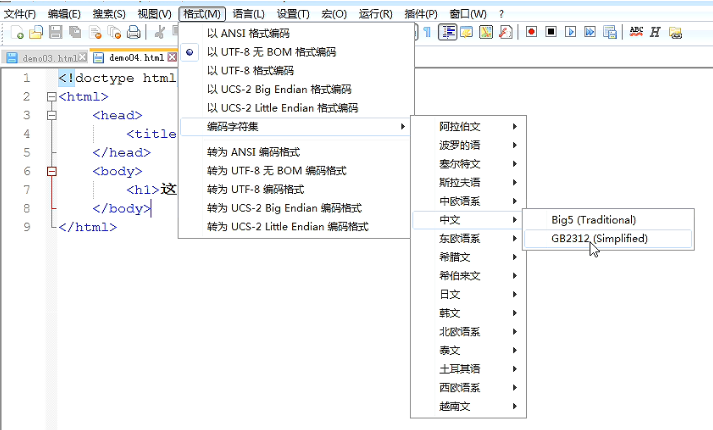
ISO-8859-1
通常叫做Latin-1,每个字符占一个字节。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符。
properties文件
ansi编码:
智能编码
在中文机器上,直接创建时的编码方式是GB2312,如下图:

从其他地方考来的,可以自动识别。

