Scrapy常用命令
scrapy全局命令
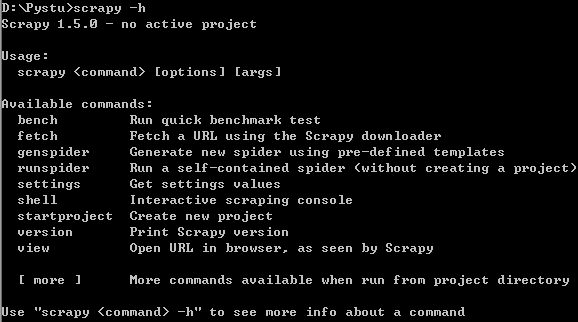
要想了解在scrapy中由哪些全局命令,可以在不进入scrapy爬虫项目目录的情况下运行scrapy -h
(1) fetch命令
fetch命令主要用来显示爬虫爬取的过程,如果在scrapy项目目录之外使用该命令,则会调用scrapy默认的爬虫来进行网页的爬取,如果在scrapy的某个项目目录内使用该命令,则会调用该项目中的爬虫来进行网页的爬取
--headers 控制显示对象的爬虫爬取网站的头信息
--nolog 控制不显示日志信息
--logfile==FILE 存储日志文字信息
--spider=SPIDER 控制使用哪个爬虫
--loglevel=LEVEL控制日志级别
日志等级常见值:
CRITICAL 发生严重的错误
ERROR 发生了必须立即处理的错误
WARNING 出现一些警告信息
INFO 输出一些提示信息
DEBUG 输出一些调试信息,常用于开发阶段
(2)runspider命令
可以实现不依托scrapy的爬虫项目,直接运行一个爬虫文件
该命令还没有理解,没看到parse()函数的打印信息
(3)setting命令
查看scrapy对应的配置信息,如果在项目目录内使用,查看的是对应项目的配置信息,如果在项目外使用查看的是scrapy默认配置信息
(4)shell命令
shell命令可以启动scrapy的交互终端,scrapy的交互终端经常在开发以及跳水的时候用到,使用scrapy的交互终端可以实现在不启动scrapy爬虫的情况下,对网站响应进行调试
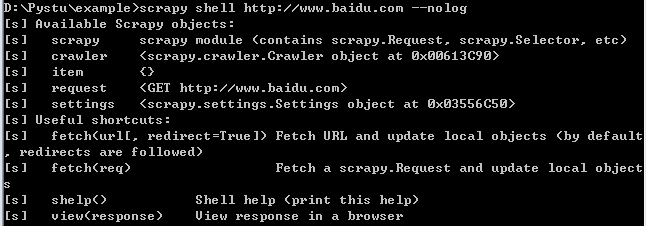
可以看到在执行命令后会出现可以使用的scarpy对象及快捷命令
(5)startproject命令
用于创建项目
scrapy startproject firstspider [parm]
(6)version命令
通过version命令可以直接显示scrapy的版本相关信息
(7)view命令
实现下载某个网页并用浏览器查看的功能
scrapy项目命令
(1)bench命令
使用bench命令可以测试本地硬件的性能,当我们允许scrapy bench的时候,会创建一个本地服务器并且会以最大的速度爬行,再次为了测试本地硬件的性能,避免过多的因素的影响,所有仅进行连接跟进,不进行内容的处理
单纯就硬件性能来说,显示每分钟大约能爬2400个网页,这是一个参考标准,在实际运行爬虫项目的时候,会由于各种因素导致速度不同,一般来说,可以根据实际运行的速度与该参考速度进行对比结果,从而对爬虫项目进行优化与改进
(2)genspider命令
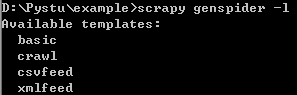
创建爬虫文件,可以使用该命令的-l参数来查看当前可以使用的爬虫模板
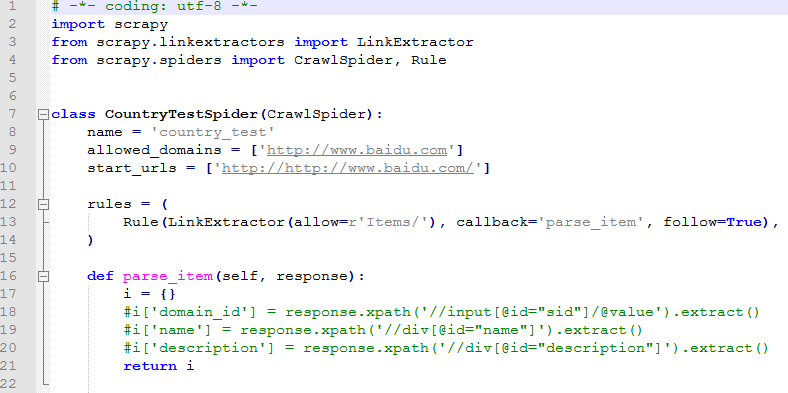
使用-t可以基于其中任意一个爬虫模板来生成一个爬虫文件

这样会在example/spiders/country_test目录下生成country_test.py文件
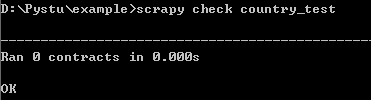
(3)check命令
在scrapy中使用check命令实现对某个爬虫文件进行合同(contract)检查
(4)crawl命令
启动某个爬虫
scrapy crawl country_test --loglevel=DEBUG
(5)list命令
列出当前可以使用的爬虫文件
(6)edit命令
直接打开对应编辑器对爬虫文件进行编辑

