机器学习之数据预处理
在sklearn之数据分析中总结了数据分析常用方法,接下来对数据预处理进行总结
当我们拿到数据集后一般需要进行以下步骤:
- (1)明确有数据集有多少特征,哪些是连续的,哪些是类别的
- (2)检查有没有缺失值,对缺失的特征选择恰当的方式进行弥补,使数据完整
- (3)对连续的数值型特征进行标准化
- (4)对类别型的特征进行编码
- (5)根据实际问题分析是否需要对特征进行相应的函数转换
依然以房价数据为例,依次进行上述操作
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
housing = pd.read_csv('./datasets/housing/housing.csv')
1. 明确数据集有多少特征,哪些是连续的,哪些是类别的
print(housing.shape)
(20640, 10)
print(housing.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
None
2. 检查有没有缺失值,对缺失的特征选择恰当的方式进行弥补,使数据完整
通过info()发现除了:
- ocean_proximity属性类别为object外,其余都为float64类型,则判断ocean_proximity为标签,其余为特征值
- total_bedrooms存在缺失值
2.1 缺失值处理方式
(1) 放弃缺失值所在的行
(2) 放弃缺失值所在的属性,即列
(3) 将缺失值设置为某个值(0,平均值、中位数或使用频率高的值)
print(housing[housing.isnull().T.any().T][:5]) #打印有NaN的行的前5行
longitude latitude housing_median_age total_rooms total_bedrooms \
290 -122.16 37.77 47.0 1256.0 NaN
341 -122.17 37.75 38.0 992.0 NaN
538 -122.28 37.78 29.0 5154.0 NaN
563 -122.24 37.75 45.0 891.0 NaN
696 -122.10 37.69 41.0 746.0 NaN
population households median_income median_house_value ocean_proximity
290 570.0 218.0 4.3750 161900.0 NEAR BAY
341 732.0 259.0 1.6196 85100.0 NEAR BAY
538 3741.0 1273.0 2.5762 173400.0 NEAR BAY
563 384.0 146.0 4.9489 247100.0 NEAR BAY
696 387.0 161.0 3.9063 178400.0 NEAR BAY
2.1.1 删除缺失值所在的行
# 删除行
housing1 = housing.dropna(subset=['total_bedrooms'])
print(housing1.info())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 20433 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20433 non-null float64
latitude 20433 non-null float64
housing_median_age 20433 non-null float64
total_rooms 20433 non-null float64
total_bedrooms 20433 non-null float64
population 20433 non-null float64
households 20433 non-null float64
median_income 20433 non-null float64
median_house_value 20433 non-null float64
ocean_proximity 20433 non-null object
dtypes: float64(9), object(1)
memory usage: 1.7+ MB
None
2.1.2 删除缺失值所在的列
# 删除列
housing2 = housing.drop(['total_bedrooms',],axis=1)
print(housing2.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 9 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(8), object(1)
memory usage: 1.4+ MB
None
2.1.3 替换缺失值
# 使用平均值替换
mean = housing['total_bedrooms'].mean()
print('mean:',mean)
housing3 = housing.fillna({'total_bedrooms':mean})
print(housing3[290:291])
mean: 537.8705525375618
longitude latitude housing_median_age total_rooms total_bedrooms \
290 -122.16 37.77 47.0 1256.0 537.870553
population households median_income median_house_value ocean_proximity
290 570.0 218.0 4.375 161900.0 NEAR BAY
3. 对连续的数值型特征进行标准化
当数据集的数值属性具有非常大的比例差异,往往导致机器学习的算法表现不佳,当然也有极少数特例。在实际应用中,通过梯度下降法求解的模型通常需要归一化,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树不使用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征X的信息增益比,而信息增益比跟特征是否经过归一化是无关的
数据标准化常用方法有:
- 最小-最大缩放(又加归一化),将值重新缩放使其最终范围在0-1之间,(current - min)/ (max - min)
- 标准化,(current - mean) / var,使得得到的结果分布具备单位方差,相比最小-最大缩放,标准化的方法受异常值的影响更小
4. 对类别型的特征进行编码
4.1 为什么要进行编码
在监督学习中,除了决策树等少数模型外都需要将预测值与实际值(也就是说标签)进行比较,然后通过算法优化损失函数,这就需要将标签转换为数值类型用于计算
4.2 如何编码
常用的编码方式有:序号编码,独热编码,二进制编码
4.2.1 序号编码
序号编码通常用于处理类别间具有大小感谢的数据,例如成绩,可以分为低、中、高三档,并且存在‘高>中>低’的排列顺序,序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示3,中表示2,低表示1
4.2.2 独热编码
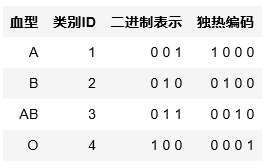
独热编码通常用于处理类别间不具有大小关系的特征。例如血血型,一共有4个取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示(1,0,0,0),B型血表示(0,1,0,0),C型血表示(0,0,1,0),D型血表示(0,0,0,1)
对于类别取值较多的情况下使用独热编码需要注意以下问题:
(1) 使用稀疏向量来节省空间
在独热编码下,特征向量只有某一维取1,其他位置均为0,因此可以利用向量的稀疏性表示有效地节省空间,并且目前大部分的算法均接受稀疏向量形式的输入
(2) 配合特征选择来降低维度
4.2.3 二进制编码
二进制编码本质上就是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间
5. 根据实际问题分析是否需要对特征进行相应的函数转换
当我们对数据集进行一定程度的分析之后,可能会发现不同属性之间的某些有趣的联系,特别是跟目标属性相关的联系,在准备给机器学习算法输入数据之前,应该尝试各种属性的组合
以上面的房价数据集为例,如果你不知道一个地区有多少个家庭,那么知道一个地区的房间总数也没什么用,你真正想知道是的一个家庭的房间数量,同样的,但看卧室总数这个属性本身,也没有什么意义,你可能想拿它和房间总数来对比,或者拿来通每个家庭的人口数这个属性结合
5.1 查看原数据集属性与房间中位数的相关性
corr_martrix = housing.corr()
print(corr_martrix['median_house_value'].sort_values(ascending=False))
median_house_value 1.000000
median_income 0.688075
total_rooms 0.134153
housing_median_age 0.105623
households 0.065843
total_bedrooms 0.049686
population -0.024650
longitude -0.045967
latitude -0.144160
Name: median_house_value, dtype: float64
5.2 查看属性组合后与房间中位数的相关性
housing4 = housing.copy()
housing4['rooms_per_household'] = housing4['total_rooms'] / housing4['households']
housing4['bedrooms_per_room'] = housing4['total_bedrooms'] / housing4['total_rooms']
housing4['population_per_household'] = housing4['population'] / housing4['households']
corr_martrix1 = housing.corr()
print(corr_martrix1['median_house_value'].sort_values(ascending=False))
median_house_value 1.000000
median_income 0.688075
total_rooms 0.134153
housing_median_age 0.105623
households 0.065843
total_bedrooms 0.049686
population -0.024650
longitude -0.045967
latitude -0.144160
Name: median_house_value, dtype: float64
可以看出bedrooms_per_room较房间总数或是卧室总数与房价中位数的相关性要高的多,所以在进行属性组合时可以多多尝试
6. 使用Sklearn.pipeline实现数据预处理
6.1 代码实现
from sklearn.preprocessing import Imputer,LabelEncoder,OneHotEncoder,StandardScaler
from sklearn.base import BaseEstimator,TransformerMixin
from sklearn.pipeline import Pipeline,FeatureUnion
class DaraFrameSelector(BaseEstimator,TransformerMixin):
def __init__(self,attr_name):
self.attr_name = attr_name
def fit(self,X,Y=None):
return self
def transform(self,X,Y=None):
return X[self.attr_name].values
features_attr = list(housing.columns[:-1])
labels_attr = [housing.columns[-1]]
feature_pipeline = Pipeline([('selector',DaraFrameSelector(features_attr)),
('imputer',Imputer(strategy='mean')),
('scaler',StandardScaler()),])
label_pipeline = Pipeline([('selector',DaraFrameSelector(labels_attr)),
('encoder',OneHotEncoder()),])
full_pipeline = FeatureUnion(transformer_list=[('feature_pipeline',feature_pipeline),
('label_pipeline',label_pipeline),])
C:\Anaconda3\lib\site-packages\sklearn\utils\deprecation.py:58: DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead.
warnings.warn(msg, category=DeprecationWarning)
housing_prepared = full_pipeline.fit_transform(housing)
print(housing_prepared.shape)
(20640, 14)
参考资料:
- (1) 《机器学习实战基于Scikit-Learn和TensorFlow》
- (2) 《白面机器学习》

