python究竟要不要使用多线程
在总结concurrent.futures库之前先来弄明白三个问题:(1)python多线程究竟有没有用?
(2)python虚拟机机制如何控制代码的执行?
(3)python中多进程处理原理是怎么样的?
1. 先来看两个例子
(1)例1
分别用单线程、使用多线程、使用多进程三种方法对最大公约数进行计算
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
if __name__ == '__main__': # 不使用多线程和多进程 start = time.time() results = list(map(gcd,numbers)) end = time.time() print('未使用--timestamp:{:.3f} second'.format(end-start)) #使用多线程 start = time.time() pool = ThreadPoolExecutor(max_workers=3) results = list(pool.map(gcd,numbers)) end = time.time() print('使用多线程--timestamp:{:.3f} second'.format(end-start)) #使用多进程 start = time.time() pool = ProcessPoolExecutor(max_workers=3) results = list(pool.map(gcd,numbers)) end = time.time() print('使用多进程程--timestamp:{:.3f} second'.format(end-start))
输出:

之前线程数和进程说都为3,现在修改为4再测试

为了更能说明问题,将线程数和进程说继续增加为5

至于区别,大家自己感受,测试的条件(计算过于简单)、测试的环境都会影响测试结果
(2)例2
同样分别用单线程、使用多线程、使用多进程三种方法对网页进行爬虫,只是简单的返回status_code
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import time import requests def download(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'example.webscraping.com'} response = requests.get(url, headers=headers) return(response.status_code) if __name__ == '__main__': urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1', 'http://example.webscraping.com/places/default/view/Aland-Islands-2', 'http://example.webscraping.com/places/default/view/Albania-3', 'http://example.webscraping.com/places/default/view/Algeria-4', 'http://example.webscraping.com/places/default/view/American-Samoa-5'] start = time.time() result = list(map(download, urllist)) end = time.time() print('status_code:',result) print('未使用--timestamp:{:.3f}'.format(end-start)) pool = ThreadPoolExecutor(max_workers = 3) start = time.time() result = list(pool.map(download, urllist)) end = time.time() print('status_code:',result) print('使用多线程--timestamp:{:.3f}'.format(end-start)) pool = ProcessPoolExecutor(max_workers = 3) start = time.time() result = list(pool.map(download, urllist)) end = time.time() print('status_code:',result) print('使用多进程程--timestamp:{:.3f}'.format(end-start))
输出:
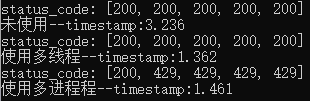
一下就看出了区别
2. python虚拟机机制如何控制代码执行?
对于python来说,作为解释型语言,Python的解释器必须做到既安全又高效。我们都知道多线程编程会遇到的问题,解释器要留意的是避免在不同的线程操作内部共享的数据,同时它还要保证在管理用户线程时保证总是有最大化的计算资源。python是通过使用全局解释器锁来保护数据的安全性。
python 代码的执行由python虚拟机来控制,即Python先把代码(.py文件)编译成字节码(字节码在Python虚拟机程序里对应的是 PyCodeObject对象,.pyc文件是字节码在磁盘上的表现形式),交给字节码虚拟机,然后虚拟机一条一条执行字节码指令,从而完成程序的执行。 python在设计的时候在虚拟机中,同时只能有一个线程执行。同样地,虽然python解释器中可以运行多个线程,但在任意时刻,只有一个线程在解释器 中运行。而对python虚拟机的访问由全局解释器锁来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程的环境中,python虚拟机按一下 方式执行:
(1)设置GIL(global interpreter lock)
(2)切换到一个线程执行
(3)运行:指定数量的字节码指令、线程主动让出控制(可以调用time.sleep(0))
(4)把线程设置为睡眠状态
(5)解锁GIL
(6)再次重复以上步骤。
GIL的特性,也就导致了python不能充分利用多核cpu。而 对面向I/O的(会调用内建操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其他线程在这个线程等待I/O的时候运行。如果线程 并未使用很多I/O操作,它会在自己的时间片一直占用处理器和GIL。
3. python多线程究竟有没有用?
通过前面的例子和python虚拟机制的理解对多线程的使用应该很清楚了,I/O密集型python程序比计算密集型的程序更能充分利用多线 程的好处。 总之,在计算密集型的程序中不要python多线程,使用python多进程进行并发编程,就不会有GIL这种问题存在,并且也能充分利用多核cpu。
(1)GIL不是bug,Guido也不是水平有限才留下这么个东西。龟叔曾经说过,尝试不用GIL而用其他的方式来做线程安全,结果python语言整体效率又下降了一倍,权衡利弊,GIL是最好的选择——不是去不掉,而是故意留着的
(2)想让python计算速度快起来,又不想写C,用pypy吧,这才是真正的大杀器
(3)可以使用协程来提高cpu的利用率,使用multiprocessing和gevent
4. python多进程执行原理
ProcessPoolExecutor类会利用multiprocessing模块所提供的底层机制,以例2作为例子描述下多进程执行流程:
(1)把urllist列表中的每一项输入数据都传给map
(2)用pickle模块对数据进行序列化,将其变成二进制形式
(3)通过本地套接字,将序列化之后的数据从解释器所在的进程发送到子解释器所在的进程
(4)在子进程中,用pickle对二进制数据进行反序列化,将其还原成python对象
(5)引入包含download函数的python模块
(6)各个子进程并行的对各自的输入数据进行计算
(7)对运行的结果进行序列化操作,将其转变成字节
(8)将这些字节通过socket复制到主进程之中
(9)主进程对这些字节执行反序列化操作,将其还原成python对象
(10)最后把每个子进程所求出的计算结果合并到一份列表之中,并返回给调用者。
multiprocessing开销比较大,原因就在于:主进程和子进程之间通信,必须进行序列化和反序列化的操作

