
Locust简单学习记录
locust性能测试框架
1、locust原理(感觉讲的很好,完全摘抄的,原地址:https://www.cnblogs.com/ywt798/p/16138472.html)

locust为什么能够识别写的代码和运行?
locust基于两个类,继承两个类才能实现模拟用户行为:
TaskSet类(模拟请求的行为,任务):locust里面的类,继承TaskSet类,写一个类继承TaskSet类之后locust才能识别它。
主要是为了模拟用户端请求信息信息,@task装饰器让locust识别到哪个是我们的任务,模拟用户的行为
HttpUser类(用户配置类):locust里的类继承HttpUser类,用户类,这个类主要写一些用户的配置信息,
比如Host主机地址,思考时间,等一系列信息,通过继承HttpUser类来实现。
这两个类他们之间怎么通信,有任务,有用户配置,需要桥梁。
这个桥梁,在用户类里有个tasks=[继承TaskSet的类],用户信息有哪些任务,指向任务类,两类就可以连通了
这两类又继承locust里面的类,所以locust命令也能去识别他们的信息。
2、Locust类详细讲解(感觉讲的很好,完全摘抄的,原地址:https://www.cnblogs.com/ywt798/p/16138472.html)
在Locust类中,具有一个client属性,它对应着虚拟用户作为客户端所具备的请求能力,
也就是我们常说的请求方法。 client模拟客户端请求
通常情况下,我们不会直接使用Locust类,因为其client属性没有绑定任何方法。
因此在使用Locust时,需要先继承Locust类,然后在继承子类中的client属性中绑定客户端的实现类。对于常见的HTTP(S)协议,
Locust已经实现了HttpUser(1.0之前使用HttpLocust)类,其client属性绑定了HttpSession类,
而HttpSession又继承自requests.Session。
因此在测试HTTP(S)的Locust脚本中,我们可以通过client属性来使用Python requests库的所有方法,
包括:GET/POST/HEAD/PUT/DELETE/PATCH等,调用方式也与requests完全一致。
另外,由于requests.Session的使用,因此client的方法调用之间就自动具有了状态记忆的功能。
常见的场景就是,在登录系统后可以维持登录状态的Session,从而后续HTTP请求操作都能带上登录态。
而对于HTTP(S)以外的协议,我们同样可以使用Locust进行测试,只是需要我们自行实现客户端。
在客户端的具体实现上,可通过注册事件的方式,在请求成功时触发events.request_success,
在请求失败时触发events.request_failure即可。
然后创建一个继承自Locust类的类,对其设置一个client属性并与我们实现的客户端进行绑定。后续,
我们就可以像使用HttpUser类一样,测试其它协议类型的系统;
client通过客户端请求服务器,捕获响应信息,设置一些断言信息;
HttpUser 配置一些用户信息
在Locust类中,除了client属性,还有几个属性需要关注下:
.tasks(1.0以下是task_set): task哪些任务,继承了任务类,才能去跑取locust请求,tasks =[WebsiteTasks]
# Collection of python callables and/or TaskSet classes that the Locust user(s) will run.
指向一个TaskSet类的列表,TaskSet类定义了用户的任务信息,该属性为必填;
max_wait/min_wait: 每个用户执行两个任务间隔时间的上下限(毫秒)
即:思考时间,具体数值在上下限中随机取值,不设置默认1s。
wait_time = between (3,25) 等价于max_wait=25/min_wait=2
·host:被测系统的host,当在终端中启动locust时没有指定--host参数时才会用到;主机地址或者域名
·weight:同时运行多个Locust类时会用到,用于控制不同类型任务的执行权重。
权重,权重越大跑的越多。在继承TaskSet类,对应的方法会使用@task装饰器,
后面可以录入数值,表示权重,数值越大,权重越大。
测试开始后,每个虚拟用户(Locust实例)的运行逻辑都会遵循如下规律:
继承taskset任务类里面有个on_start方法,和初始化一样,类似jmeter里setpu线程组,只执行一次,初始化数据;
1)先执行WebsiteTasks中的on_start(只执行一次),作为初始化;
2)从WebsiteTasks中随机挑选(如果定义了任务间的权重关系,那么就是按照权重关系随机挑选)一个任务执行;
3)根据Locust类中min_wait和max_wait定义的间隔时间范围(如果TaskSet类中也定义了min_wait
或者max_wait,以TaskSet中的优先),思考时间在时间范围内随机取一个值,休眠等待;
4)重复2~3步骤,直至测试任务终止。
TaskSet **类详细讲解**
脚本模拟用户行为发送请求,发送请求使用client属性。
性能测试工具要模拟用户的业务操作,就需要通过脚本模拟用户的行为。在前面的比喻中说到,TaskSet类好比蝗虫的大脑,
控制着蝗虫的具体行为。具体地,TaskSet类实现了虚拟用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、
挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)、中断控制(interrupt)等等。
在此基础上,我们就可以在TaskSet子类中采用非常简洁的方式来描述虚拟用户的业务测试场景,
对虚拟用户的所有行为(任务)进行组织和描述,并可以对不同任务的权重进行配置。
在TaskSet子类中除了定义任务信息,还有一个是经常用到的,那就是on_start函数。这个和jmeter里setup线程组一样,
在正式执行测试前执行一次,主要用于完成一些初始化的工作。
例如,当测试某个搜索功能,而该搜索功能又要求必须为登录态的时候,就可以先在on_start中进行登录操作;
前面也提到,HttpUser使用到了requests.Session,因此后续所有任务执行过程中就都具有登录态了。
3、locust安装
安装前提:前提本地已经有python运行环境,编译器推荐使用pycharm
windows环境:
1)ctrl+R,输入cmd,调出命令窗口,使用命令:pip3 install locust,进行locust的安装。;
2)校验是否安装成功:输入locust -V,出现如下图所示,表示安装成功;

linux环境:
1)待补充
4、示例解释
import os from locust import TaskSet,task,HttpUser,between,tag class WebBehaviour(TaskSet): """继承,定义任务类""" # on_start进行数据初始化,在task任务之前执行 def on_start(self): print("压测前置条件") def on_stop(self): print('结束') @tag('smoke') # -T 使用该标签的用例,-E 不使用该标签的用例 @task(1) def mytask_01(self): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'} url = '/' # 请求路径,除了主机地址后面的请求路径,主机地址可以在用户类里定义 # catch_response:为了使用response.success()与response.failure()这两个函数 # name:相当于为mytask_01对应的请求起了一个别名,用于在运行结果中的name列显示,方便阅读 with self.client.get(url=url,headers=headers,catch_response=True,name='百度访问') as response: if response.status_code == 200: response.success() else: response.failure('百度访问失败') class WebUser(HttpUser): """性能参数配置,继承用户配置类""" host = 'https://www.runoob.com' tasks = [WebBehaviour,] wait_time = between (3,25) # min_wait = 1000 ms # max_wait = 3000 ms if __name__ == '__main__': file_path = os.path.abspath(__file__) os.system(f"locust -f {file_path} --host=https://www.baidu.com -P=8088 --headless -u 10 -r 3 -t 20s")
5、运行命令(有界面及无界面)
通过在浏览器页面输入相关参数,进行脚本调试或压测;
1、在pycharm-terminal下,输入:locust -f 执行的py文件(py文件的相对路径或者绝对路径),回车键,py文件开始执行;

2、点击: http://localhost:8089或者在浏览器地址栏输入: http://localhost:8089,展示出以下页面:
其中,Number of users:用户并发数;Spawn rate:每秒钟启动多少并发;Host:进行测试的地址。
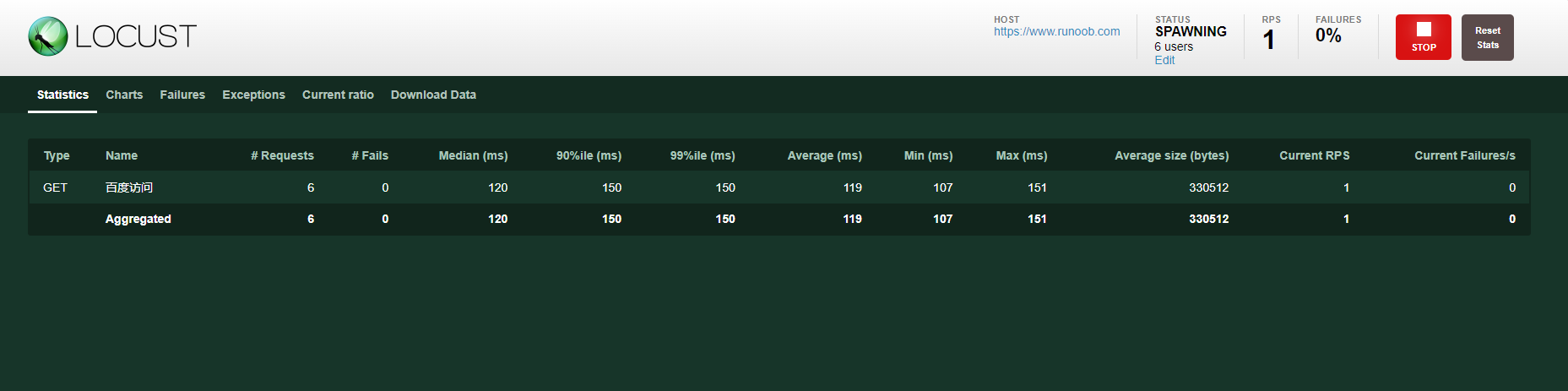
页面提供了,类似于AggregateReport的测试结果统计表;实时的统计图,鼠标光标悬浮可以查看具体信息;请求失败的数据统计表;测试结果数据的下载功能。 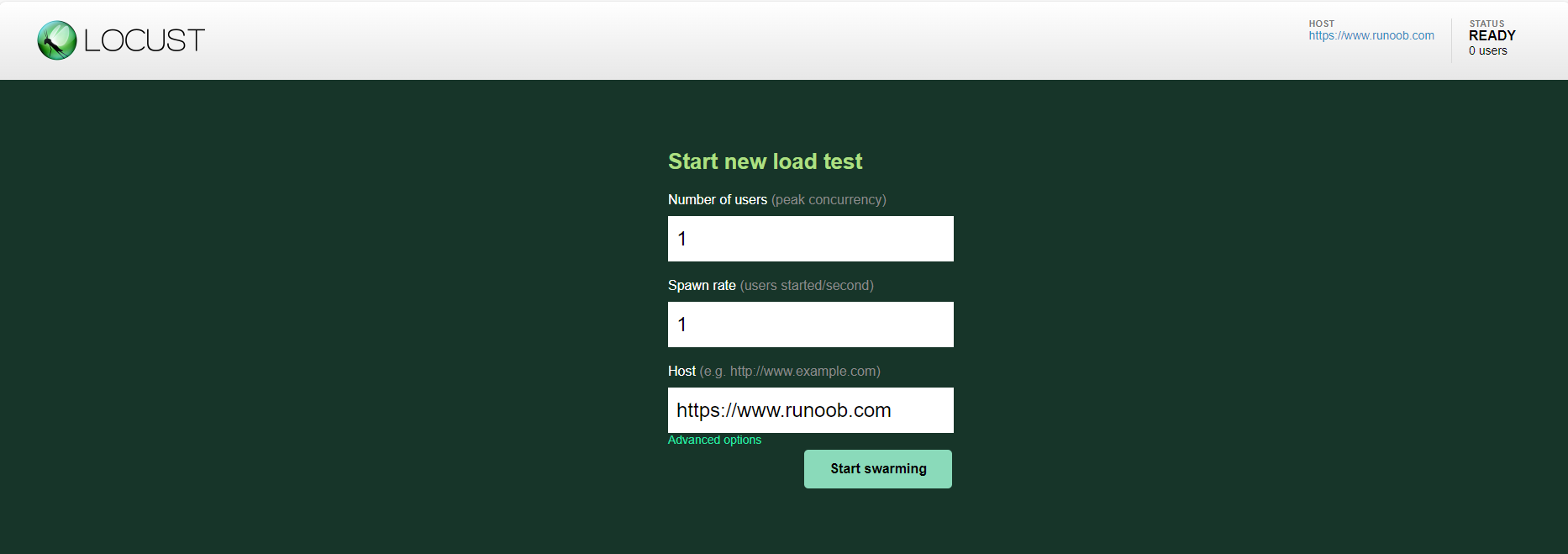
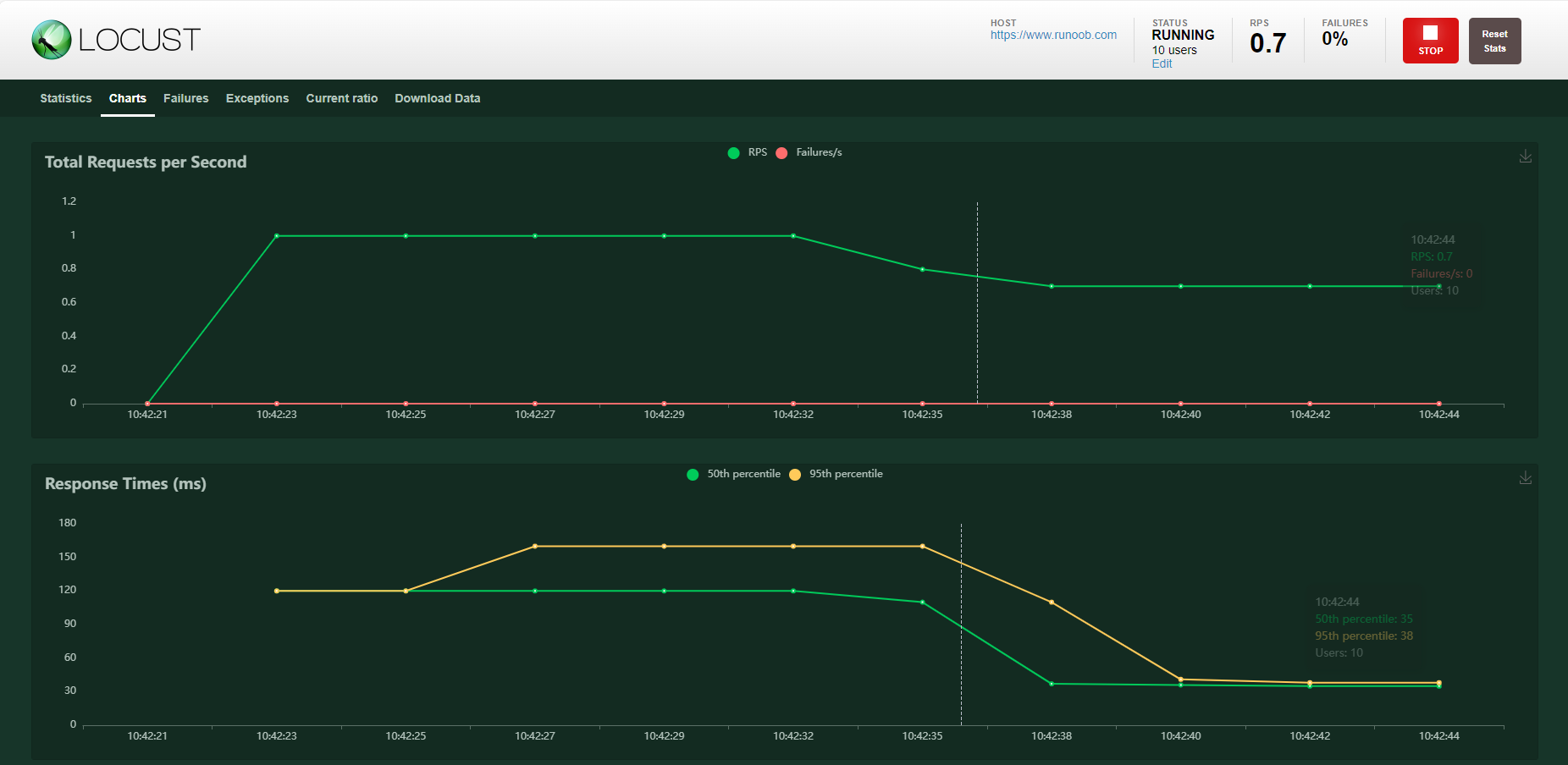
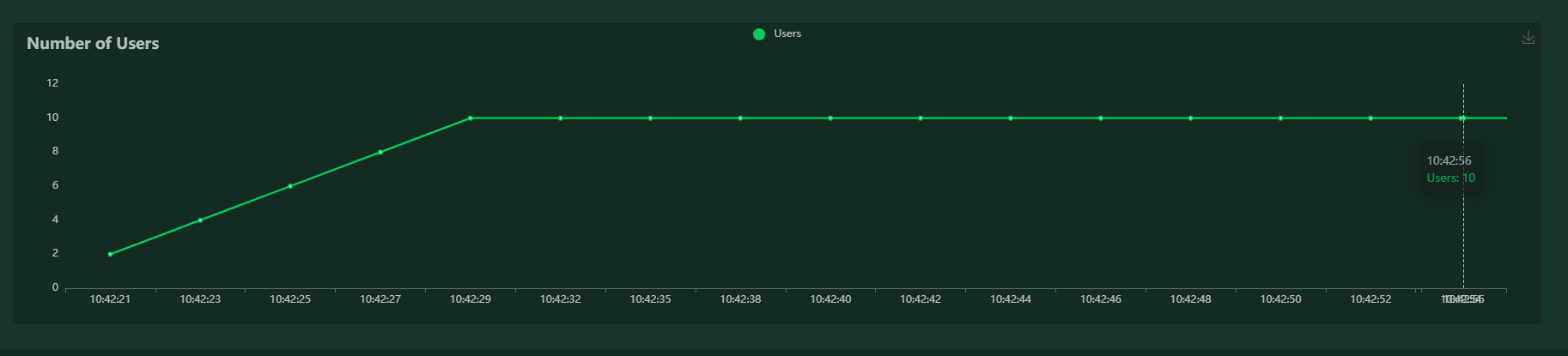
全部通过命令来完成压测及压测结果的收集
1、在pycharm-terminal下,输入:locust -f 执行的py文件(py文件的相对路径或者绝对路径) --host=https://www.baidu.com -P=8088 --headless -u 10 -r 3 -t 20s --csv=文件名,回车键,py文件开始执行;
其中,--headless,有这个参数时,代表无界面压测;
--host,压测地址(域名);
-P,可以指定端口号,不指定时,默认8089;
-u,用户并发数;
-r,每秒钟启动多少并发;
-t,本次压测持续多长时间;
--csv,输出本次压测的结果,文件为csv文件,在当前路径下会出现四个csv文件:TestData_exceptions.csv,TestData_failures.csv,TestData_stats.csv,TestData_stats_history.csv。
在pycharm-terminal下,输入:locust -h,可以查看更多参数。
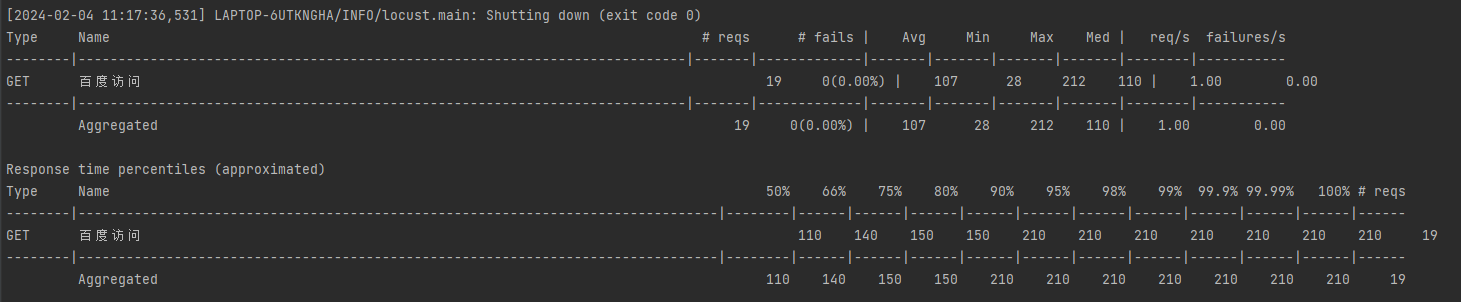
6、分布式性能测试介绍
分布式场景:
Locust分布式场景有两种:
1、单台机器设置Master和Slave
2、多台机器时,一台调度机(Master),其他机器设置执行机(Slave)
准备工作
1、主机(master)装好locust环境
2、从机(slave)装好locust环境
3、主机/从机上都要有执行的Python文件(你自己写的压测脚本)
分布式运行原理:
master节点不产生压力 控制机
多个slave节点,执行机,压力机,
master节点分发给每个压力机执行里面的脚本信息
locust分布式执行步骤:
一、master节点控制机:
1、master节点控制机命令行输入:locust -f 文件 --master
locust -f miaosha.py --master
2、输入:http://localhost:8089/ 登录locust的web页面
3、假设输入5个并发去跑,这时候暂时什么都不会运行,web界面多了了新的选择字段:Wrokers
现在这是主节点,不是工作节点,所以这个节点不会产生压力,需要分配slave从节点
二、salve节点执行机:
1、机器命令行打开输入:loucst -f 文件 --worker --master-host=ip地址
locust -f miaosha.py --worker 没有输入host地址默认本机
输入这个后,宿主机就能够和salve机通信,宿主机的web端页面的worker能找到这个执行机并且处于ready准备状态
这世界就可以在master控制机输入并发数执行脚本
需要加多个节点按照上面的命令在执行机输入命令执行locust就行


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?