


K8S(一)-搭建k8s集群
集群组成:
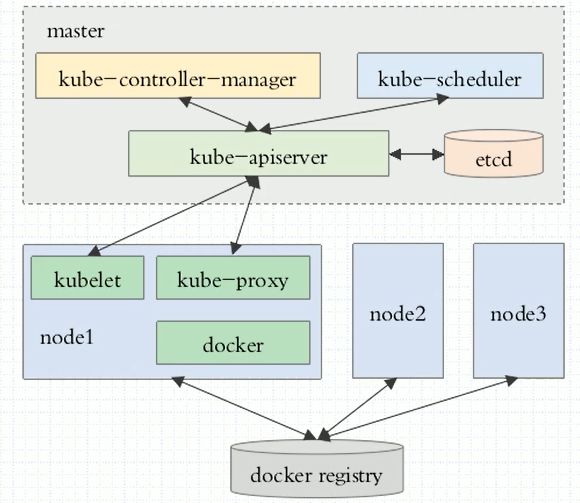
master 主节点,不需要太多,高可用
node 真正提供工作的节点,也叫worker节点,为了运行容器的节点
master节点主要由四个模块组成:
- APIServer 提供了资源操作的唯一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。kubectl就是对api server的调用。
- scheduler 负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- etcd k8s的DB。是一个kv类型的共享存储,Kubernetes使用它来存储各个资源的状态,支持Restful的API。
node节点主要由三个模块组成:
- Container runtime 容器运行环境,常用docker容器
- kubelet 负责维护容器的生命周期,管理pods和pods上面的容器
- kube-proxy 负责为Service提供cluster内部的服务发现和负载均衡,每一个service的变动都要靠kube-proxy来转换成对应的规则
网络:
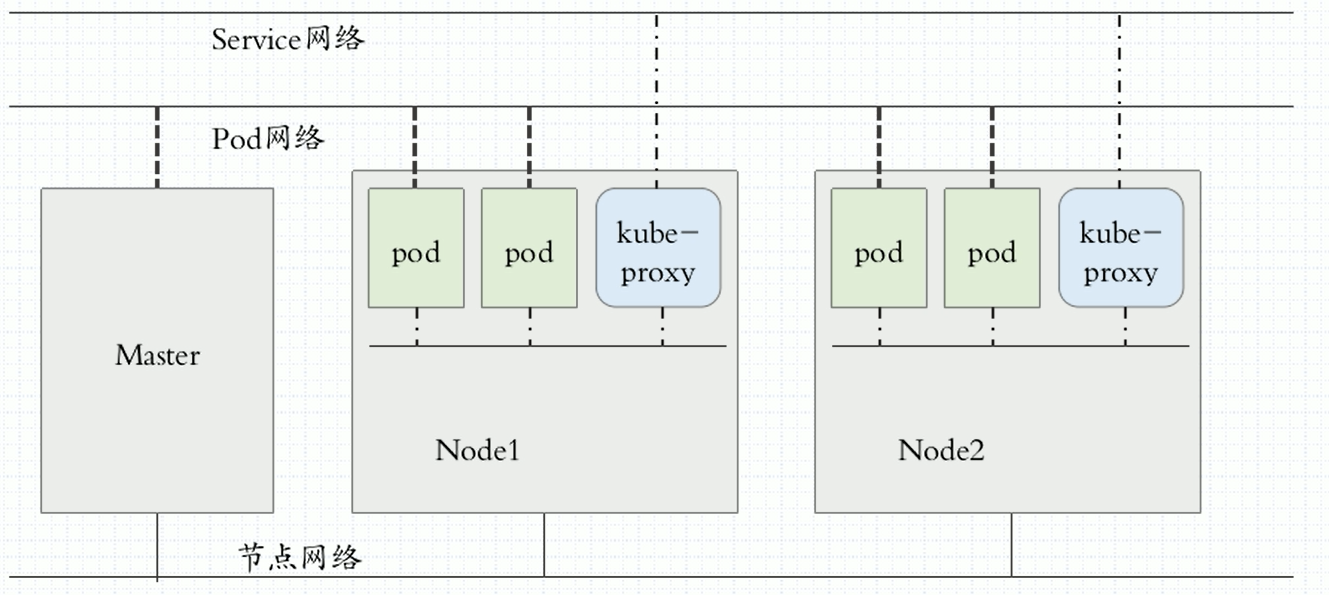
网络解决方案:
k8s本身内部不提供网络解决方案,通过插件CNI(容器网络接口)来提供, 这些网络解决方案可以作为附件运行,也可以作为节点上的守护进程来运行。常见的有:
flannel:只支持网络配置,不支持网络策略, 叠加网络实现(简单)
calico:既支持网络配置,又支持网络策略,于bgp协议来实现直接路由的通信,(复杂)
canel:用flannel来提供网络配置,用calico来支持网络策略
安装部署
方法1:将k8s所有组件都运行为系统级的守护进程,包括master节点上的4个组件和node节点上的3个组件。全部需要手动安装,包括证书等,安装过程较复杂。
方法2:使用kubeadm工具来部署,把k8s的组件运行为pod:master的4个组件全部运行为pod,node节点上的kube-proxy也运行为pod,需要注意这里的pod都是static pod。
这里采用方法2来安装, kubeadm https://github.com/kubernetes/kubeadm
master&slave: 安装kubeadm,docker, kubectl, flannel(支持pod间互相通信)
master : kubeadm init
slave: kubeadm join
1.时间同步,关闭防火墙。
2.安装docker。wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
2.配置kubernetes yum源
[kubernetes] name=kubernetes Repo baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
wget https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
rpm --import rpm-package-key.gpg
4.安装所需组件
yum install kubelet-1.14.3 kubeadm-1.14.3 kubectl-1.14.3 docker-ce-18.09*
vim /etc/docker/daemon.json { "registry-mirrors": ["https://3s01e0d2.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ] }
systemctl start docker
systemctl enable docker
echo 1 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
忽略swap
vim /etc/sysconfig/kubelet
[root@heaven00 ~]# cat /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
master节点
初始化master节点
# kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=swap [init] using Kubernetes version: v1.14.3 [preflight] running pre-flight checks [WARNING KubernetesVersion]: kubernetes version is greater than kubeadm version. Please consider to upgrade kubeadm. kubernetes version: beadm version: 1.11.x [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join 172.17.8.128:6443 --token 825yrh.qe2kpku40dwcwusb --discovery-token-ca-cert-hash sha256:02b158edd568a75523cb12a1561b65937bcf146319484fd86f88e9
执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# kubectl get cs
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady master 164m v1.11.2 #nodes处于NotReady状态,因为缺少网络组件
部署网络组件 flannel
# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds-amd64 created daemonset.apps/kube-flannel-ds-arm64 created daemonset.apps/kube-flannel-ds-arm created daemonset.apps/kube-flannel-ds-ppc64le created daemonset.apps/kube-flannel-ds-s390x created
等待一会儿
docker image ls 看到flannel镜像下载下来
kubectl get pods -n kube-system 查看pods运行在,
才说明flannel安装成功
# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-8686dcc4fd-qg5jz 1/1 Running 0 4m33s coredns-8686dcc4fd-vx64c 1/1 Running 0 4m33s etcd-master01 1/1 Running 0 3m46s kube-apiserver-master01 1/1 Running 0 3m42s kube-controller-manager-master01 1/1 Running 0 3m33s kube-flannel-ds-amd64-5sbrx 1/1 Running 1 2m49s kube-flannel-ds-amd64-wlr5x 1/1 Running 0 3m34s kube-proxy-d2pzd 1/1 Running 0 2m49s kube-proxy-gpwkg 1/1 Running 0 4m33s kube-scheduler-master01 1/1 Running 0 3m49s
再查看 kubectl get nodes 会看到已经ready
# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready master 5m52s v1.14.3
# kubelet get ns
node节点
安装组件
# yum install kubelet-1.14.3 kubeadm-1.14.3 kubectl-1.14.3
加入集群
# kubeadm join 172.17.8.128:6443 --token j1u40p.5is2liahibv1gwgk --discovery-token-ca-cert-hash sha256:51579863a2ff093f730c0552c13c44ea87e270064a7fc9ba5bac069ca47cf2cb [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Activating the kubelet service [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
node加入集群后 在master上面查看
]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready <none> 3d21h v1.14.3
master01 Ready master 3d21h v1.14.3
kubectl get pods -n kube-system -o wide 可以查看集群内所有的pods,包括node节点的
报错1:
启动docker时报错:Error starting daemon: Error initializing network controller: list bridge addresses failed: no available network


解决:需要手动添加下docker0网桥:,注意不要跟虚拟机在同一网段
brctl addbr docker0
ip addr add 172.17.0.1/16 dev docker0
ip link set dev docker0 up
systemctl restart docker
报错2:初始化kubeadm时
[preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/kube-apiserver-amd64:v1.14.3]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/kube-controller-manager-amd64:v1.14.3]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/kube-scheduler-amd64:v1.14.3]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/kube-proxy-amd64:v1.14.3]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/pause:3.1]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/etcd-amd64:3.2.18]: exit status 1
[ERROR ImagePull]: failed to pull image [k8s.gcr.io/coredns:1.1.3]: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
解决方法:
通过别的镜像仓库,先将镜像下载下来然后再修改成k8s.gcr.io对应的tag
docker pull mirrorgooglecontainers/kube-apiserver-amd64:v1.14.3
docker pull mirrorgooglecontainers/kube-controller-manager-amd64:v1.14.3
docker pull mirrorgooglecontainers/kube-scheduler-amd64:v1.14.3
docker pull mirrorgooglecontainers/kube-proxy-amd64:v1.14.3
docker pull mirrorgooglecontainers/pause:3.1
docker pull mirrorgooglecontainers/etcd-amd64:3.2.18
docker pull coredns/coredns:1.3.1
修改tag:
docker tag mirrorgooglecontainers/kube-apiserver-amd64:v1.14.3 k8s.gcr.io/kube-apiserver:v1.14.3
docker tag mirrorgooglecontainers/kube-controller-manager-amd64:v1.14.3 k8s.gcr.io/kube-controller-manager:v1.14.3
docker tag mirrorgooglecontainers/kube-scheduler-amd64:v1.14.3 k8s.gcr.io/kube-scheduler:v1.14.3
docker tag mirrorgooglecontainers/etcd-amd64:3.2.18 k8s.gcr.io/etcd:3.3.10
docker tag mirrorgooglecontainers/kube-proxy-amd64:v1.14.3 k8s.gcr.io/kube-proxy:v1.14.3
docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
报错3: node 执行 kubeadm join 加入集群时报错:
报错1:configmaps "kubelet-config-1.11" is forbidden: User "system:bootstrap:wdchig" cannot get resource "configmaps" in API group "" in the namespacetem"
原因:版本问题,当前版本为1.11.2 。需要升级kubelet和kubeadm。按照上面的安装步骤来,安装的时候指定版本即可。
报错2:couldn't validate the identity of the API Server: expected a 32 byte SHA-256 hash, found 29 bytes
原因:kubeadm init生成的token有效期只有1天
解决方法:
在master节点检查token是否有效
master # kubeadm token list 查看
master# kubeadm token create --print-join-command --ttl 0 生成新的token和命令。然后在node重新执行
--ttl 0 不过期
报错4: 重新执行初始化的时候报错: error marking master: timed out waiting for the condition
解决:
# kubeadm reset -f && rm -rf /etc/kubernetes/
清理集群数据 然后再 kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=Swap
报错5: master节点显示master状态为NotRedy。 coredns CrashLoopBackOff
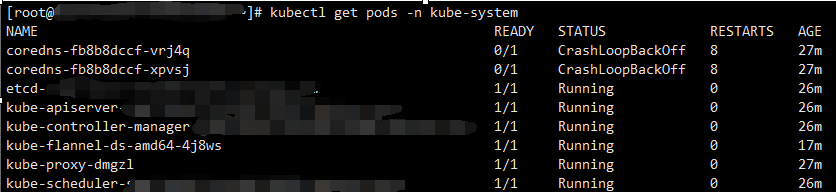
在网上找到方法, 说是CoreDNS启动后会通过宿主机的resolv.conf文件去获取上游DNS的信息,如果这个时候获取的DNS的服务器是本地地址的话,就会出现环路,从而被环路识别器识别出来。
解决 :查看机器 /etc/resolv.conf
nameserver 127.0.0.1 修改为 nameserver 114.114.114.114 ,重新初始化后解决
报错6: node节点join时正常,但是在master查看时node显示NotReady状态。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 NotReady <none> 3d20h v1.14.3
master01 Ready master 3d21h v1.14.3

# kubectl describe pod kube-proxy-l6pwk -n kube-system 查看pod详细信息
# kubectl -n kube-system logs kube-proxy-l6pwk 查看日志
Warning FailedCreatePodSandBox 60m (x1999 over 3d20h) kubelet, node01 Failed create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.1": Error response from daemon: Get https://k8s.gcr.io/v1/_ping: dial tcp 74.125.204.82:443: getsockopt: connection timed out
通过手动拉取镜像并打tag。解决。
报错7: 加入集群后node状态为NotReady
journalctl -f -u kubelet 可在节点机器查看kubelet的输出日志信息
E0528 18:56:54.890957 24778 kubelet.go:2170] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
docker pull quay.io/coreos/flannel:v0.12.0-amd64

