python 爬虫案例-1爬取百度贴吧适合小白
import urllib.request
import urllib.parse
class ABC():
def __init__(self):
# 伪装
self.hede={
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
}
# 头
self.base_url='https://tieba.baidu.com/f?'
def A(self,url):
# 对拼接好的网站进行处理
# 请求头。防止反扒
req = urllib.request.Request(url, headers=self.hede)
# 访问urlopen
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
def B(self,filennaem,html):
# 写入
with open(filennaem, 'w', encoding='utf_8') as f:
f.write(html)
# def C(self):
# pass
def main(self):
name = input('输入查询内容')
begin = int(input('输入开始页数'))
end = int(input('输入结束页'))
kw = {'kw': name}
resule = urllib.parse.urlencode(kw)
for i in range(begin, end + 1):
pn = (i - 1) * 50
# print(pn)
# base_url = 'https://tieba.baidu.com/f?'
url = self.base_url + resule + '&pn=' + str(pn)
html=self.A(url)
filennaem = '第' + str(i) + '页.html'
self.B(filennaem,html)
if __name__ == '__main__':
ss=ABC()
ss.mai
运行过程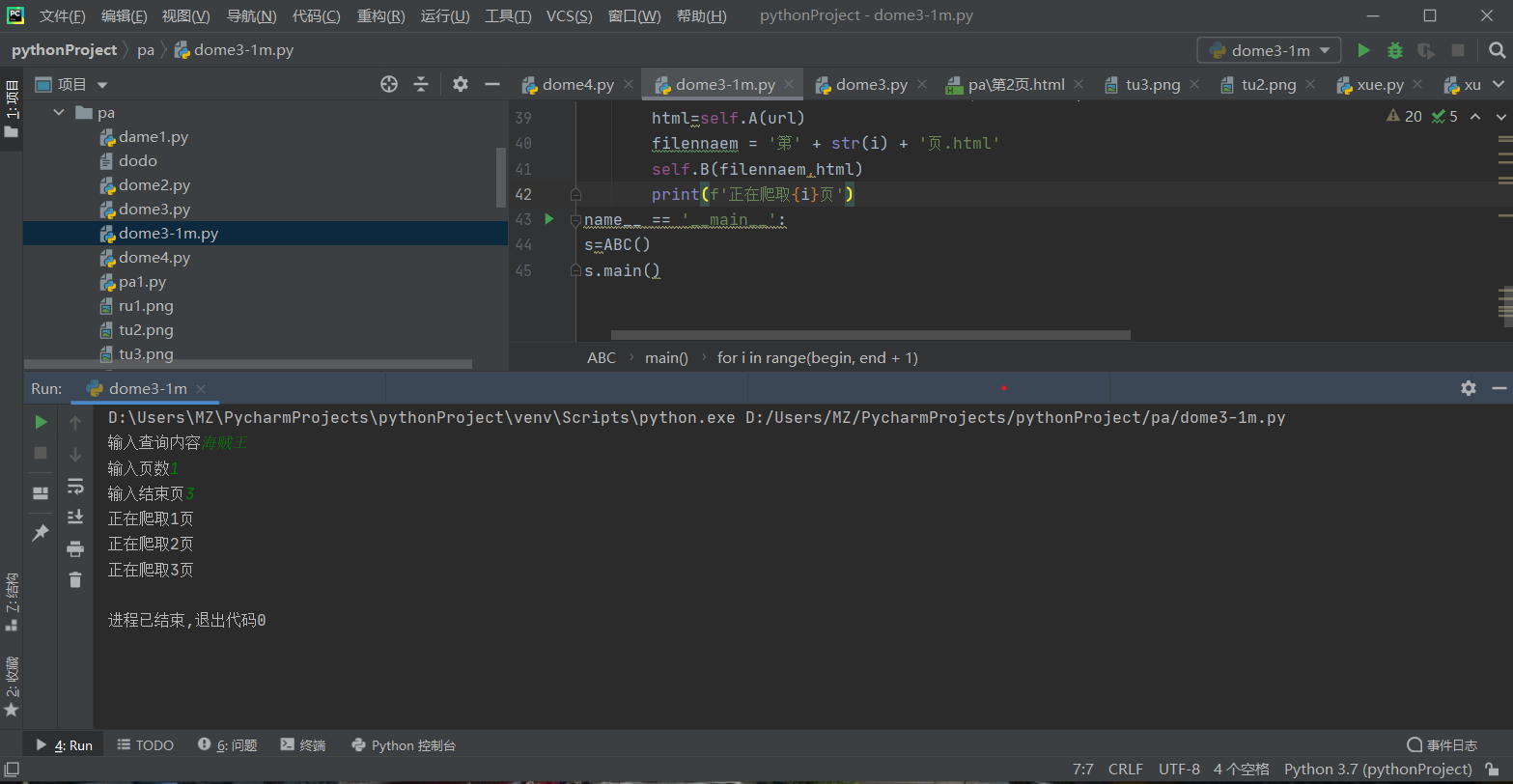
运行的结果