

201871030110-何飞 实验二 个人项目—《个人软件项目》项目报告
201871030110-何飞 实验二 个人项目—《个人软件项目》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 班级博客地址 |
| 这个作业要求 | 作业要求 |
| 我的课程学习目标 | 1.使用Github进行项目托管。 2.掌握Github发布软件项目的操作方法。 3.掌握个人软件项目的开发步骤。 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.熟练使用Github进行项目托管。 2.规范软件项目的开发步骤。 |
| 项目Github的仓库链接地址 | 本次项目Github仓库地址 |
写在前沿
我的本次项目不能使用eclipse打开,必须使用idea打开,eclipse打开是错的。
任务1
点评班级博客
任务2
阅读《构建之法》一书,学习PSP流程。
PSP流程益处:
- PSP流程是一种模型,使得软件开发过程不局限于编程语言,而注重软件开发。
- PSP流程通过计划和目标的方式,规定了每一部分时间应当完成什么样的任务,从而开启下一阶段的任务。
- PSP流程在一定程度上干预和指导软件项目开发人员开发软件项目趋于成功,将环境因素导致的项目失败的原因缩小。
多余的不予赘述,在《构建之法》一书中详细论述了PSP流程,读者可自行翻阅查看。
任务3
3.1 需求分析
-
0-1背包问题是经典的NP Complete问题,在现实生活中有着广泛的应用。例如:对于大学生而言,假期回家总要带许多的东西,现在有一个皮箱,我要装入一些生活必须品和其它的物品,现在假设装入生活必须品后皮箱还有许多的空间可以存放其它的物品,那么如何装其它的物品,使得能够发挥背包的最大价值,这就是一个典型的背包的问题(可忽略,这是我以自身经验的举例,虽然不是很贴切)。
-
现代社会的繁荣,企业为了获得最大得利润,经常出现各种各样得折扣销售,刺激人们进行消费。这一过程中,企业经常通过折扣销售、捆绑销售等各种手段获得最大得利益,如何做才能获得最大利益呢?由此,引出今天的主题 D{0-1}KP问题。D{0-1}KP数据集由一组项集组成,每个项集有3项物品可供背包装入选择,其中第三项价值是前两项之和,第三项的重量小于其他两项之和,算法求解过程中,如果选择了某个项集,则需要确定选择项集的哪个物品,每个项集的三个项中至多有一个可以被选择装入背包,D{0-1} KP问题要求计算在不超过背包载重量 的条件下,从给定的一组项集中选择满足要求装入背包的项,使得装入背包所有项的价值系数之和达到最大;D{0-1}KP instances数据集是研究D{0-1}背包问题时,用于评测和观察设计算法性能的标准数据集。
-
为了研究各项数据之间的关系,并为了获取最大利益,由此,开始今天的实验。
3.2 功能设计
基本主要功能有以下几部分:
- 读取存有实验数据的文件,并对实验的数据进行解析,获得有效的D{0-1}KP数据。
- 在第一步的基础上,绘制任意一组以重量为横轴、以价值为纵轴的数据散点图。
- 在第一步的基础上,通过计算,对D{0-1}KP数据按照第三项的价值:重量比进行非递增排序。
- 在第一步的基础上,用户选择使用动态规划法或者回溯法对D{0-1}KP问题进行求最有解,并显示求解时间。
- 在上一步骤的基础上,对D{0-1}KP问题的最有解、求解时间和解向量保存为txt文件或者导出为EXCEL文件。
附加功能:
- 实现容错机制,如果数据量过大,提供异步读取数据并进行算法计算(数据量过大,会出现界面卡顿,本功能用于解决此问题)。
- 数据存储于数据库中,从数据库中读取数据,并将结果写回数据库。
说明:由于基本功能的实现过程中,出现了没有预期到的问题,耽搁了程序设计的进度,故没有实现附加功能。
3.3 设计实现
- 启动程序,开辟线程,运行swing的主程序。
- 选择打开文件按钮,选择项目中附带的文件,解析文件(主要功能是选择文件)。
- 点击显示数据按钮,提示刷线数据,根据复选框,选择某一文件的某一组,进行数据显示(主要功能是显示数据)。
- 点击绘制散点图。根据选择的组数,进行散点图的绘制,并显示(主要功能是绘制散点图)。
- 点击非递增排序。根据选择的组数,计算各个数据的比值,进行非递增排序(主要功能是排序)。
- 点击动态规划算法处理。根据选择的组数,进行动态规划算法处理解决问题(主要功能是动态规划处理模块数据)。
- 点击回溯法处理。根据选择的组数,进行回溯法处理解决问题(主要功能是回溯法处理模块数据)。
- 保存数据,通过选择的组数,根据动态规划或者回溯法,创建文件,并保存数据(主要功能是保存数据)。
3.4 测试运行
以下是我实现的一些功能。
- 读取文件,解析数据,将任意一组数据显示于显示屏。
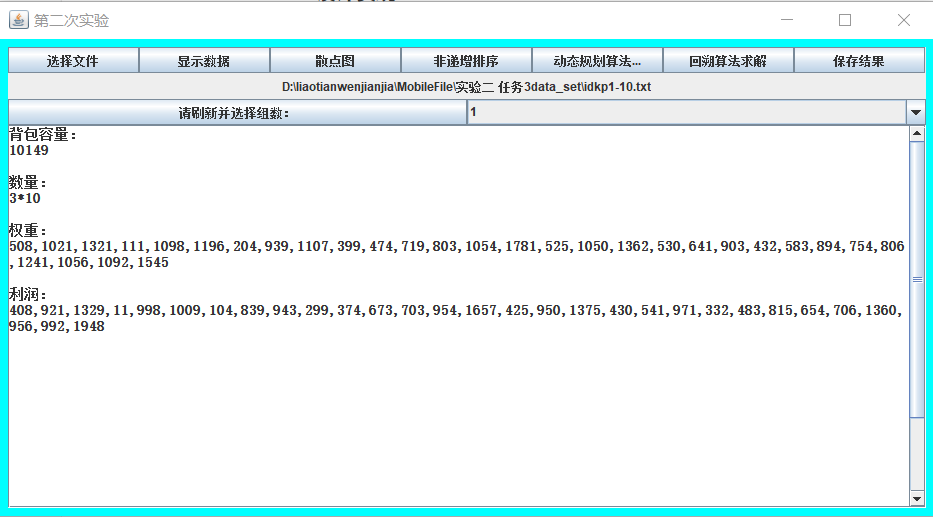
- 根据读取的组数,绘制散点图。

- 根据读取的组数,进行非递增排序。
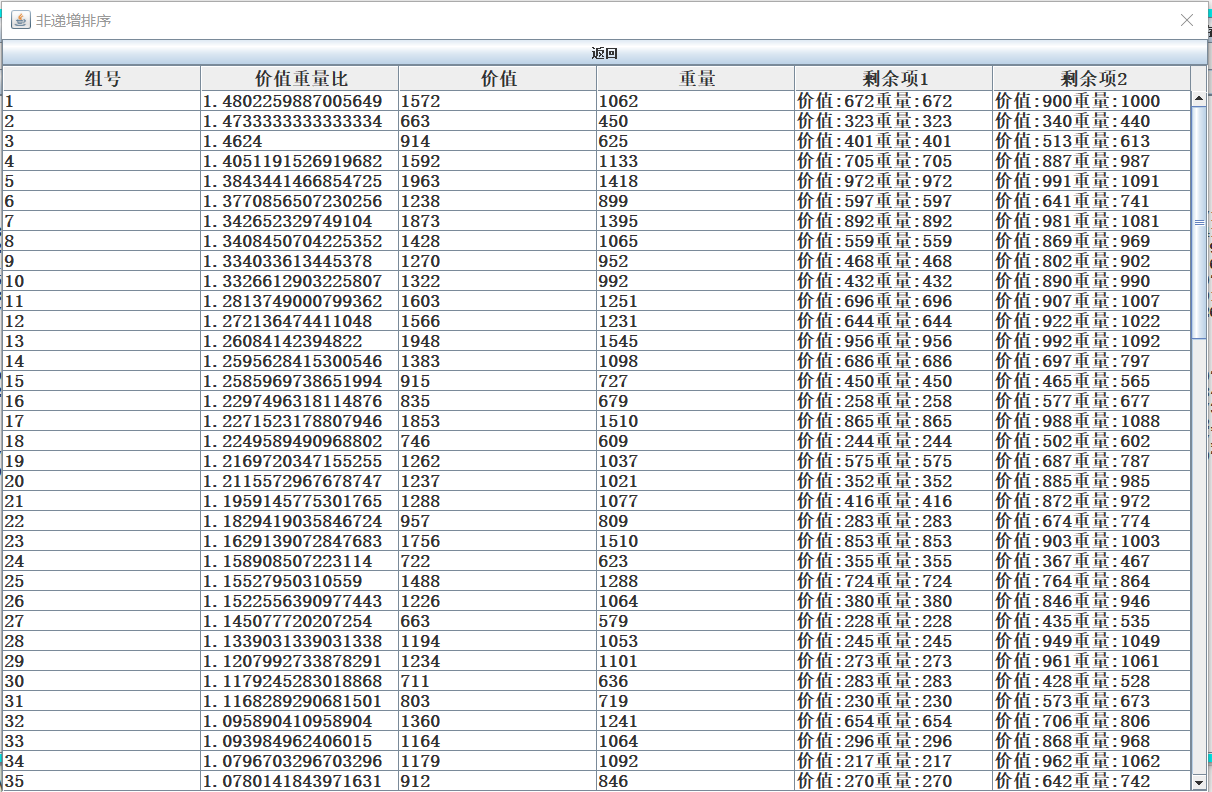
- 根据读取的组数,进行动态规划求解。
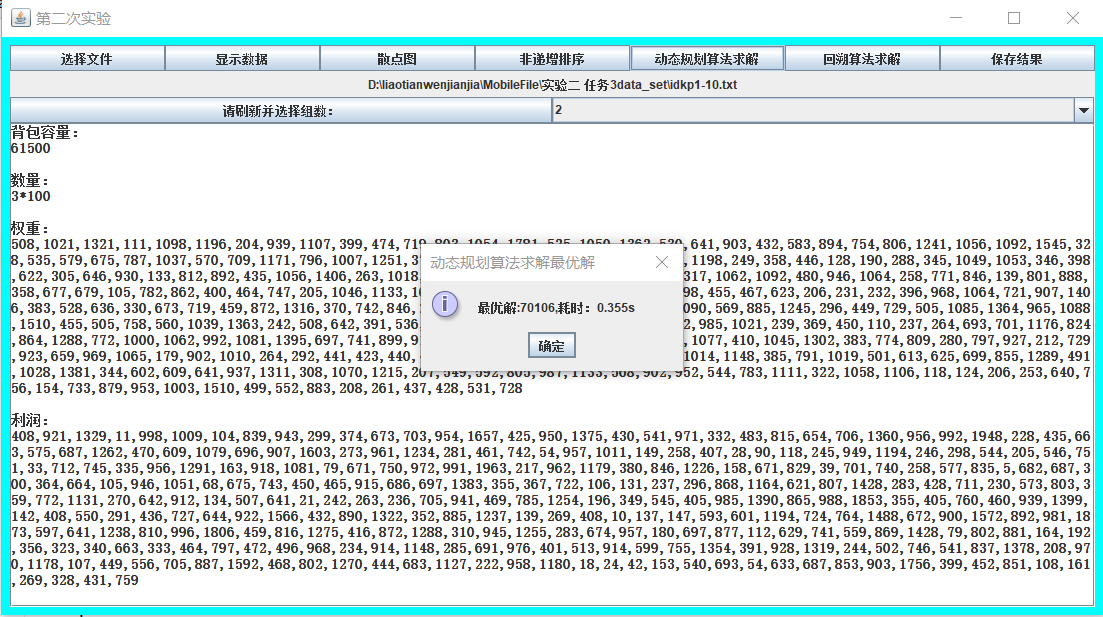
- 根据读取的组数,将结果保存于文件中。
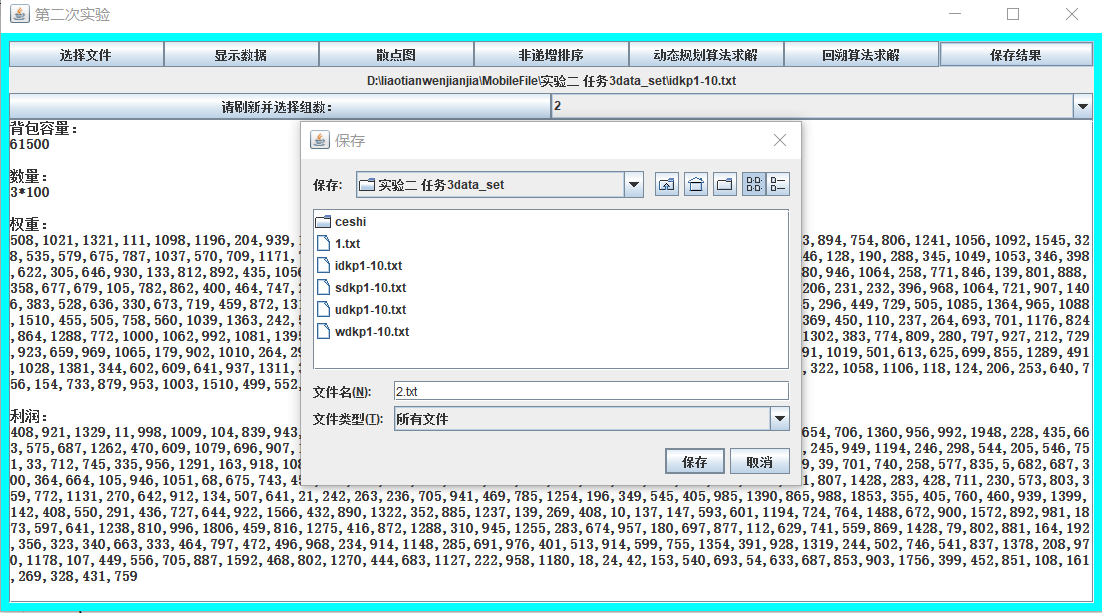
3.5 核心代码
第一部分核心代码(解析文件):
//初步格式化件
String getTextByDeleteWhiteSpace=StringUtils.deleteWhitespace(data);//删除所有的空格
int getFirstDKPIndex=getTextByDeleteWhiteSpace.indexOf("DKP");//获得首次出现DKP的位置
String formatPrefixText=getTextByDeleteWhiteSpace.substring(getFirstDKPIndex+3);//删除冒号以前的字符
int getLastFullIndex=formatPrefixText.lastIndexOf('.');//获得最后一次出现.的位置
int getLastCommaIndex=formatPrefixText.lastIndexOf(',');//获得最后一次出现,的位置
int index=getLastFullIndex>getLastCommaIndex?getLastFullIndex:getLastCommaIndex;//获得格式化后的文本
String formatSuffixText=formatPrefixText.substring(0,index);
getProfitAndWeight(formatSuffixText);//获取profit和weight
注:这是读取文件内容后进行规整的部分
String[] getSplitByDKP = text.split("DKP");//初步通过DKP剪切,获得各个模块
for (String modular : getSplitByDKP)
{
String[] getSplitByColon=modular.split(":");//二次剪切,每个模块划分为四个子模块,第一个子模块不使用
//处理第二个小模块
String[] getDimensionAndCubage=getSplitByColon[1].split(",");//通过逗号切割
String dimension=getNumberByString(getDimensionAndCubage[0]);
String cubage=getNumberByString(getDimensionAndCubage[1]);
//处理第三个小模块
int getLastCommaIndex1=getSplitByColon[2].lastIndexOf(',');//获得逗号的位置
String profit=getSplitByColon[2].substring(0,getLastCommaIndex1);
//处理第四个小模块
int getLastCommaIndex2=getSplitByColon[3].lastIndexOf(',');
String weight=getSplitByColon[3].substring(0,getLastCommaIndex2);
//数据存入链表
list.add(new ProfitWeight(dimension,cubage,profit,weight));
}
注:这是读取文件内容规整后进行切割的部分
-
为什么说这一块很重要呢?请听我慢慢道来
-
文件的解析我试了很久,发现数据不是高度的规整的,有些数据在空格换行等方面存在着很重要的问题,为此,我花了好长时间对数据之间存在的规律进行了研究,发现,文本中的数据存在着一定的规律。
-
在解析数据时,调用第三方的jar包直接读入文件的字符于字符串中,调用第三方jar包直接删除所有空格。上述两步极为重要,本次实验的数据读取的核心问题就在空格上面。接下来就是删除文件开始的所有的星号和文件结束的星号,通过打印,现在的数据已经高度规整了。剩下的就是基本的剪切了。
第二部分核心代码(非递增排序):
//排序
Collections.sort(indexs,(ProfitWeightRatio o1, ProfitWeightRatio o2) -> {
if(o1.getRatio()> o2.getRatio()) return -1;
else if(o1.getRatio()== o2.getRatio()) return 0;
else return 1;
});
注:这是排序的核心代码
- 不要小看这几行代码,也许您可能在基本功能模块提出排序时脑海中已经浮现各种各样的排序算法(选排 插排 冒泡排序等)。但是,java中已经有了关于排序的接口或函数,为什么你还是要多此一举呢(java的jdk中自带的代码肯定考虑到了很多很多的因素,既然有,就直接使用,它的实现肯定比我们自己写的好的多)?简单的几行排序就已经实现了非递增排序。
3.6 总结
-
通过本次实验中,首先通过模块化分解,将系统划分为读文件解析数据、显示数据、非递增排序、散点图等模块,模块之间通过get于set方法进行数据的交流,实现了不同模块之间的数据传递。
-
美中不足的是,有些时候的数据传递并没有处理好,由于本身编程能力很差,所以程序之间的耦合性很高,程序代码的重复利用率很低,模块之间的数据交流有些频繁。
3.7 我的PSP
| PSP2.1 | 任务内容 | 计划共完成需要的时间(h) | 实际完成需要的时间(h) |
|---|---|---|---|
| Planning | 计划 | 1 | 0.5 |
| · Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 1 | 0.5 |
| Development | 开发 | 38 | 49 |
| ·· Analysis | 需求分析 (包括学习新技术) | 1 | 1 |
| · Design Spec | 生成设计文档 | 2 | 1 |
| · Design Review | 设计复审 (和同事审核设计文档) | 1 | 1 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 1 | 1 |
| · Design | 具体设计 | 2 | 3 |
| · Coding | 具体编码 | 25 | 30 |
| · Code Review | 代码复审 | 1 | 5 |
| · Test | 测试(自我测试,修改代码,提交修改) | 5 | 6 |
| Reporting | 报告 | 3 | 6 |
| ·· Test Report | · 测试报告 | 1 | 2 |
| · Size Measurement | 计算工作量 | 1 | 1 |
| · Postmortem & Process Improvement Plan | · 事后总结 ,并提出过程改进计划 | 1 | 3 |
任务4
- 程序代码已上传至我的GitHub仓库中,点击链接,即可查看;
实验感想
- 本次实验,是一次较为综合的个人项目,本次实验,虽然虽然时间较短、项目较为复杂,但是通过这几天的努力,基本上完成了一些较为重要的任务。同时,也发现了自己在学习上存在的一些不足之处。
本次实验最为重要的一个结论
- 一般情况下,我认为大家可以告别eclipse了。原因如下:我在读取文件时,由于文件比较大,eclipse中对于读出来的数据在字符串中存储不了,但是idea却可以。我百度了一下,String的存储最大可在400多M,可能eclipse的缓存有些问题,或者缓存较小的缘故,使得eclipse中String存储不了超过100KB的字符。
注:(重要的事情说三遍)
-
推荐使用idea
-
推荐使用idea
-
推荐使用idea

