
Java实现布隆过滤器
布隆过滤器
布隆过滤器主要用于判断一个元素是否在一个集合中,它可以使用一个位数组简洁的表示一个数组。它的空间效率和查询时间远远超过一般的算法,但是它存在一定的误判的概率,适用于容忍误判的场景。如果布隆过滤器判断元素存在于一个集合中,那么大概率是存在在集合中,如果它判断元素不存在一个集合中,那么一定不存在于集合中。常常被用于大数据去重。
算法思想
布隆过滤器算法主要思想就是利用k个哈希函数计算得到不同的哈希值,然后映射到相应的位数组的索引上,将相应的索引位上的值设置为1。判断该元素是否出现在集合中,就是利用k个不同的哈希函数计算哈希值,看哈希值对应相应索引位置上面的值是否是1,如果有1个不是1,说明该元素不存在在集合中。但是也有可能判断元素在集合中,但是元素不在,这个元素所有索引位置上面的1都是别的元素设置的,这就导致一定的误判几率。布隆过滤的思想如下图所示:
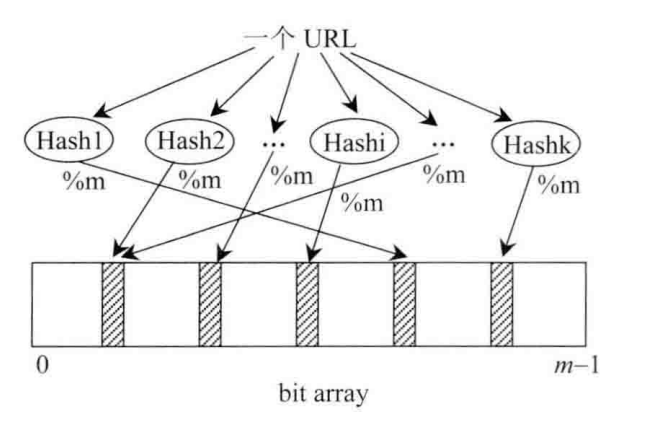
java实现简单布隆过滤器(hash+bitset):
import java.util.ArrayList;
import java.util.BitSet;
import java.util.List;
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
// 内部类,simpleHash
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
BloomFilter bf = new BloomFilter();
List<String> strs = new ArrayList<String>();
strs.add("123456");
strs.add("hello word");
strs.add("transDocId");
strs.add("123456");
strs.add("transDocId");
strs.add("hello word");
strs.add("test");
for (int i=0;i<strs.size();i++) {
String s = strs.get(i);
boolean bl = bf.contains(s);
if(bl){
System.out.println(i+","+s);
}else{
bf.add(s);
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号