LL(1)文法-------python实现
废话不多说直接开干!
对文法G的句子进行确定的自顶向下语法分析的充分必要条件是,G的任意两个具有相同左部的
产生式A—>α|β 满足下列条件:
(1)如果α、β均不能推导出ε,则 FIRST(α) ∩ FIRST(β) = ∅。
(2)α 和 β 至多有一个能推导出 ε。
(3)如果 β *═> ε,则 FIRST(α) ∩ FOLLOW(A) = ∅。
将满足上述条件的文法称为LL(1)文法。
概要
第一个L代表从左向右扫描输入符号串,第二个L代表产生最左推导,1代表在分析过程中执行每一步推导都要向前查看一个输入符号——当前正在处理的输入符号。
LL(1)文法既不是二义性的,也不含左递归,对LL(1)文法的所有句子均可进行确定的自顶向下语法分析。
需要注意的是,并不是所有的语言都可以用LL(1)文法来描述,而且不存在判定某语言是否是LL(1)文法的算法。也就是说,确定的自顶向下分析只能实现一部分上下文无关语言的分析,这就是LL(1)文法所产生的语言。另外,在上述LL(1)文法的条件中,要求:ε ∈ FIRST(α1),ε ∈ FIRST(α2),…ε ∈ FIRST(αn) 中至多有一个成立。——————来自百度百科
直接代码开搞,首先举个栗子!
处理好之后的文法:
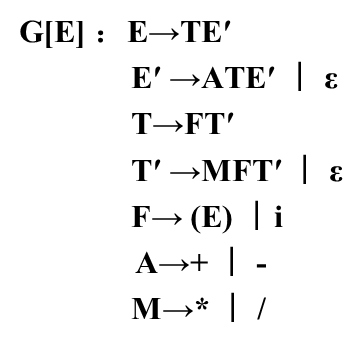
然后经过各种推到最后得到

上面那个分析表
万事具备,开始制造东风
直接来个代码
1 import copy 2 3 strs = ['#', 'E'] # 当做栈来使用,栈是先进后出那我就从-1开始 4 list1 = [['E->TE\'', '', '', '', '', 'E->TE\'', '', ''], 5 ['', 'E\'->ATE\'', 'E\'->ATE\'', '', '', '', 'E\'->ε', 'E\'->ε'], 6 ['T->FT\'', '', '', '', '', 'T->FT\'', '', ''], 7 ['', 'T\'->ε', 'T\'->ε', 'T\'->MFT\'', 'T\'->MFT\'', '', 'T\'->ε', 'T\'->ε'], 8 ['F->i', '', '', '', '', 'F->(E)', '', ''], 9 ['', 'A->+', 'A->-', '', '', '', '', ''], 10 ['', '', '', 'M->*', 'M->/', '', '', ''] 11 ] 12 list2 = ['E', 'E\'', 'T', 'T\'', 'F', 'A', 'M'] 13 list3 = ['i', '+', '-', '*', '/', '(', ')', '#'] 14 s1 = '' # 全局变量s1 15 16 17 def out1(): 18 print("分析栈\t\t余留输入串\t\t分析表中产生式") 19 20 21 def out2(str1, str2, str3, str4): 22 print("%s\t\t%s\t\t%s %s" % (str1, str2, str3, str4)) 23 24 25 str1 = [] 26 str2 = [] 27 str3 = '' 28 str4 = '' 29 s1 = input("请输入要分析的字符串:") 30 s1 += '#' 31 for i in s1: 32 str2.append(i) 33 out1() 34 35 for i in s1: 36 37 while True: 38 str1 = copy.copy(strs) 39 40 sout = strs.pop() # 取出最后一个元素 41 42 str3 = 'M[' + sout + ',' + i + ']' 43 try: 44 45 num1 = list2.index(sout) 46 num2 = list3.index(i) 47 if list1[num1][num2] != '': 48 schan = list1[num1][num2] 49 if schan[-1] == 'ε': 50 # strs.pop() 51 strs.append(sout) 52 str1 = copy.copy(strs) 53 num1 = list2.index(strs[-1]) 54 num2 = list3.index(i) 55 schan = list1[num1][num2] 56 str4 = schan 57 stop1 = 1 58 sums = '' 59 for j in schan[::-1]: 60 if j == '>': 61 break 62 elif j == '\'': 63 sums += j 64 stop1 = 2 65 else: 66 if stop1 == 1: 67 strs.append(j) 68 else: 69 sums = j + '\'' 70 strs.append(sums) 71 sums = '' 72 stop1 = 1 73 else: 74 str4 = schan 75 stop1 = 1 76 sums = '' 77 for j in schan[::-1]: 78 if j == '>': 79 break 80 elif j == '\'': 81 sums += j 82 stop1 = 2 83 else: 84 if stop1 == 1: 85 strs.append(j) 86 else: 87 sums = j + '\'' 88 89 strs.append(sums) 90 sums = '' 91 stop1 = 1 92 except: 93 if False: 94 str3 = '' 95 str4 = '成功' 96 out2(str1, str2, str3, str4) 97 break 98 else: 99 str3 = 'Pop' 100 str4 = 'Nextsym' 101 strs.pop() 102 if str1[-1] != 'ε': 103 out2(str1, str2, str3, str4) 104 str1.pop() 105 strs = copy.copy(str1) 106 107 break 108 else: 109 str1.pop() 110 str1.pop() 111 strs = copy.copy(str1) 112 if str2[-1] == '#': 113 if str1[-1] == '#': 114 str3 = '' 115 str4 = '成功' 116 out2(str1, str2, str3, str4) 117 break 118 elif str1[-1] != '#': 119 str3 = '' 120 str4 = '失败' 121 out2(str1, str2, str3, str4) 122 break 123 else: 124 str3 = '' 125 if str4 != 'Nextsym': 126 out2(str1, str2, str3, str4) 127 else: 128 out2(str1, str2, str3, str4) 129 130 str2.pop(0) # 移除第一个元素
运行结果:

输出格式有需要的朋友可以自行修改一下!
里面使用了浅拷贝,为什么要使用浅拷贝呢?原因就是我使用深拷贝错了,关于python的深拷贝和浅拷贝,首先来个官方的介绍:

反正我看的不咋明白,来个实例解释一下吧!开干!!!!
import copy a = ['a','b','c','d'] # 首先我们定义了一个我们用于操作的数组 b = a # 此时进行深拷贝 print("这是a的地址" + str(id(a))) print("这是b的地址" + str(id(b))) print("a的地址是否和b一样呢?" + str(id(a) == id(b))) c = copy.copy(a) #此时进行浅拷贝 print("这是a的地址" + str(id(a))) print("这是c的地址" + str(id(c))) print("a的地址是否和c一样呢?" + str(id(a) == id(c))) #然并软貌似看不出啥东西来,你以为这就结束了?醒醒快开学了 #下面来个我的验证方法,网上有好多将这个深拷贝和浅拷贝的但是我没看懂 #进入正题 a.pop()#现在我移除一下a中的最后一个元素 print("a中的元素:"+str(a)) print("深拷贝b中的元素:"+str(b)) print("浅拷贝c中的元素:"+str(c))
运行结果:

网上有些资料说copy方式复制的是浅拷贝,我也没有去看官方的文档,所以我从定夺,有资料的小伙伴可以发给我一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号