mysql——单表查询——分组查询——示例
一、基本查询语句
select的基本语法格式如下:
select 属性列表 from 表名和视图列表
[ where 条件表达式1 ]
[ group by 属性名1 [ having 条件表达式2 ] ]
[ order by 属性名2 [ asc | desc ] ]
属性列表参数表示需要查询的字段名;
表名和视图列表参数表示从此处指定的表或者视图中查询数据,表和视图可以有多个;
条件表达式1参数指定查询条件;
属性名1参数指按照该字段的数据进行分组;
条件表达式2参数满足该表达式的数据才能输出;
属性名2参数指按照该字段中的数据进行排序;排序方式由asc和desc这两个参数指出;
asc参数表示升序,这是默认参数,desc表示降序;(升序表示从小到大)
对记录没有指定是asc或者desc,默认情况下是asc;
如果有where子句,就按照“条件表达式1”指定的条件进行查询;如果没有where子句,就查询所有记录;
如果有group by子句,就按照“属性名1”指定的字段进行分组,如果group by后面带having关键字,那么只有
满足“条件表达式2”中知道的条件才能输出。group by子句通常和count()、sum()等聚合函数一起使用;
如果有order by子句,就按照“属性名2”指定的字段进行排序,排序方式由asc和desc两个参数指出;默认情况下是asc;
================================================================================================
分组查询:
group by关键字可以将查询结果按照某个字段或多个字段进行分组,字段的值相等的为一组
语法格式:group by 属性名 [ having 条件表达式 ] [ with rollup ]
属性名参数是指按照该字段的值进行分组;
having 条件表达式 用来限制分组后的显示,满足条件表达式的结果将被显示;
with rollup关键字将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和;
注意:group by关键字一般和聚合函数一起使用,如果不一起使用,那么查询结果就是字段取值的分组情况;
字段中取值相同的记录为一组,但只显示该组的第一条记录。
=======================================================================================
基础:前提:

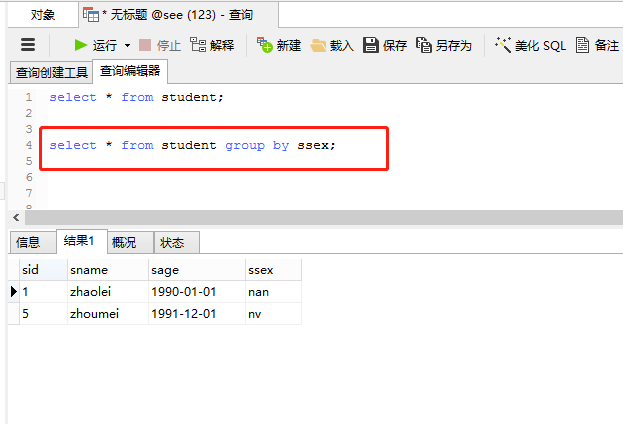
(1)单独使用group by关键字来分组
如果单独使用group by关键字,查询结果只显示一个分组的一条记录;
执行语句:
select * from student group by ssex;
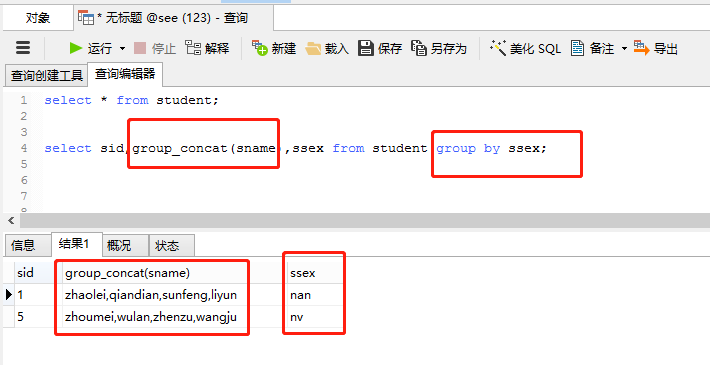
(2)group by关键字与group_concat()函数一起使用
group by关键字与group_concat()函数一起使用时,每个分组中指定字段值都显示出来;
执行语句:
select sid,group_concat(sname),ssex from student group by ssex;
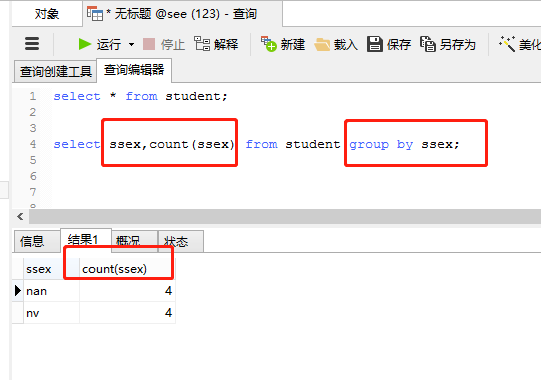
(3)group by关键字与集合函数一起使用
count()用来统计记录的条数;
sum()用来计算记录的值的总和;
avg()用来计算字段的值的平均值;
max()用来查询字段的最大值;
min()用来查询记录的最小值;
执行语句:
select ssex,count(ssex) from student group by ssex;
(4)group by关键字与having一起使用
如果加上having 条件表达式可以限制输出结果
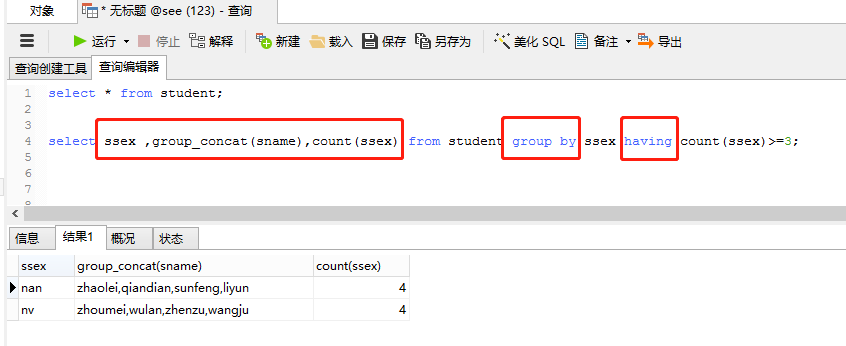
举例:select sex ,count(sex) from employee group by sex having count(sex)>=3;
注释:"having 条件表达式"与"where 条件表达式"都是用来限制显示的,但是两者起的作用又不相同,
"where 条件表达式"作用于表或者视图,是表和视图的查询条件;
"having 条件表达式"作用于分组后的记录,用于选择满足条件的组;
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex having count(ssex)>=3;
(5)group by关键字与rollup一起使用
使用rollup时,将会在所有记录的最后加上一条记录,这条记录是上面所有记录的总和;
举例:select sex,concat(name) from employee group by sex with rollup;
select ssex ,group_concat(sname),count(ssex) from student group by ssex with rollup;

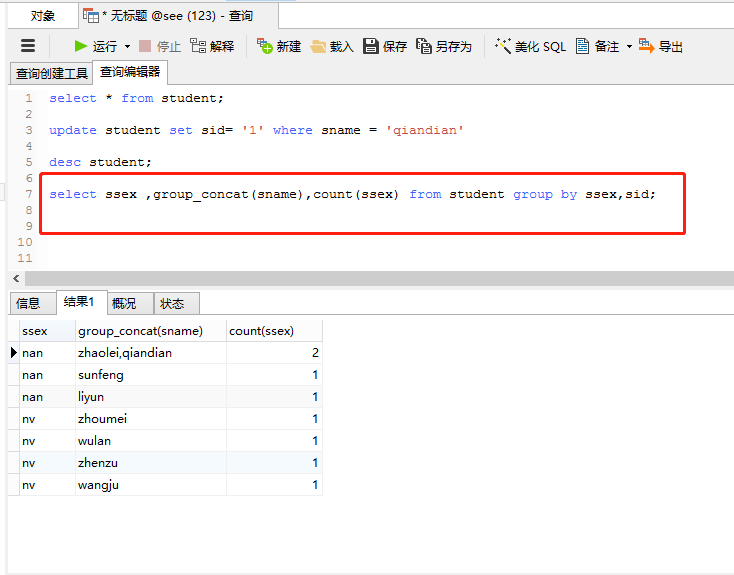
(5)按多个字段进行分组
举例:select * from employee group by d_id,sex;
查询结果显示,记录先按照d_id字段进行分组,因为有2条记录的d_id值为1001,所以这2条记录再按照sex字段的值进行分组。
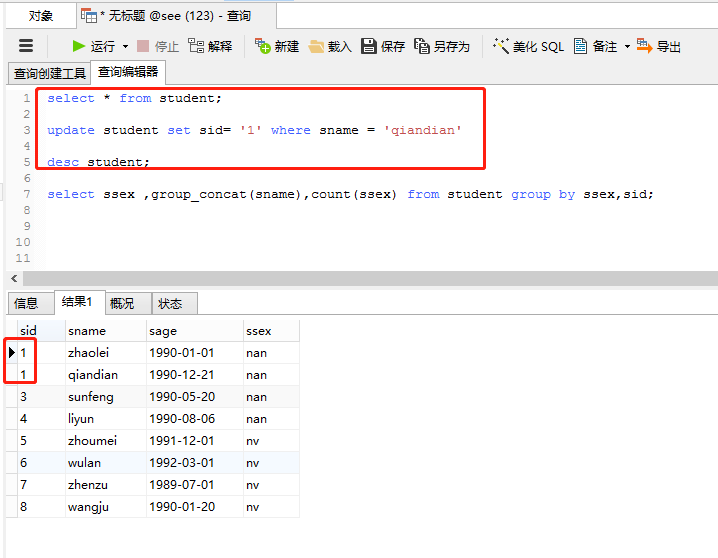
要修改一个sid,不然不好示例:
select * from student; update student set sid= '1' where sname = 'qiandian'
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex,sid;
(7)、为表和字段取别名
为表和字段取别名
1、语法:表名 表的别名
select * from department d where d.d_id = 1001;
2、语法:属性名 [as] 别名
示例:select d_id as department_id,d_name department_name from department;
数据库中,可以同时为表和字段取别名
示例:select d_id as department_id,d_name department_name,d.functione,d.address from department d where d.d_id = 1001;
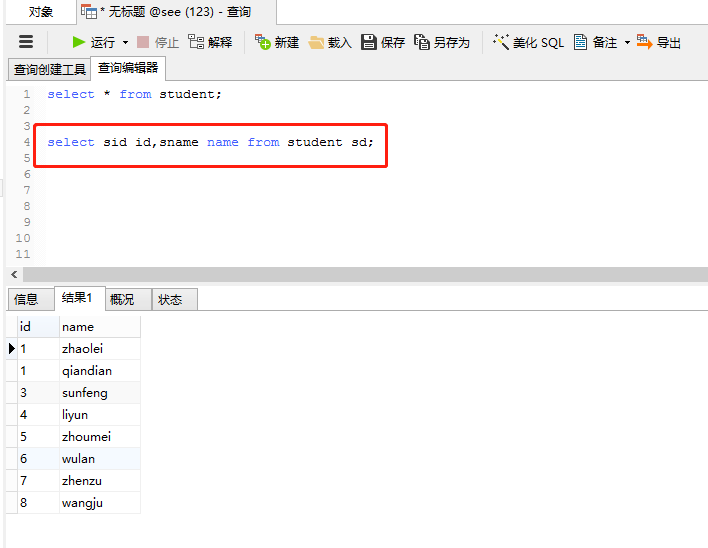
执行语句:
select sid id,sname name from student sd;