

hbase
适用场景
HBase支持海量数据存储。适合写密集型应用,每天写入量巨大,而相对读数量较小的应用
不需要复杂查询条件来查询数据的应用,HBase只支持基于rowkey的查询
对性能和可靠性要求非常高的应用,由于HBase本身没有单点故障,可用性非常高
HBASE与关系型数据库
MySQL:关系型数据库,行式存储,主要面向OLTP,支持事务,支持二级索引,支持SQL,支持主从。
Hbase:基于HDFS,支持海量数据读写(尤其是写),面向列的分布式NoSql数据库,适合OLAP业务。天然分布式,主从架构,不支持事务,不支持二级索引,不支持sql。不能支持条件查询,只支持按照Row key来查询。
HBASE与Hive
Hive和Hbase是两种基于Hadoop的不同技术–Hive是一种类SQL的引擎,并且运行MapReduce任务,HBASE是一种面向列的、在HDFS之上的NoSQL 的Key-value数据库。Hive适合用来对一段时间内的数据进行分析查询。表在HBase中是物理表,而不是逻辑表,提供一个超大的内存hash表,搜索引擎使用它來存储索引,以满足查询的实时性需求,Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑,Hive不应该用来进行实时的查询。Hive和Hbase有各自不同的特征:Hive是高延迟、结构化和面向分析的,Hbase是低延迟、非结构化和面向编程的。
HBASE表结构

HBASE表结构:建表时,不需要限定表中的字段,只需要指定若干个列族。插入数据时,列族中可以存储任意多个列(k-v,列名-列值)。HBASE去更改一个字段的时候,不会把原来的值给删除掉,而是通过版本号去区分。要查询某一具体字段的值,需要指定表名->行键->列族(ColumnFamily):列名(Qualifier)->版本。
与nosql数据库一样,row key是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1)通过单个row key访问
2)通过row key的range
3)全表扫描
在HBASE内部,row key保存为字节数组。存储时,数据按照row key的字典序(byte order)排序存储。设计key时,要充分利用排序存储这个特性,将经常一起读取的行存储放到一起。
Cell是由(row key,columnFamily,version)唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。每个cell中都保存着同一份数据的多个版本。版本通过时间戳来索引。每个cell中,不同版本的数据按照时间戳排序,即最新的数据排在最前面。为了避免数据存在过多版本造成的管理(包括存贮和索引)负担,HBASE提供了两种数据版本回收方式,一是保存数据的最后n个版本,二是保存最近一段时间内的版本。
HBASE集群架构及表存储机制HBASE将一个用户的数据分为很多的Region,Region是分布式存储的,存放在不同的Region Server上。Region Server会把Region中的数据形成一些文件HFile,存在HDFS中。Region Server物理上通常跟DataNode在一台机器上,可以免除网络传输。
HBASE表的若干行就是一个region,每个region有一个起始行键、终止行键。还有一个系统表(META表)不需要我们建,META表的行键:表-行键范围,value:主机(192.168.1.35)。然后还会有一个Root表,存在region server上(凡是表都存在region server上),在zookeeper中存放root表的信息。HBASE依赖Zookeeper保存Hmaster的地址和backup-master地址。保存表-ROOT-的地址。HMaster用于管理HregionServer;做增删该查表的节点;管理HregionServer中的表分配。
如果要查询table_1第10020010行数据,先去Zookeeper上找到/hbase/ROOT,然后找到ROOT表里的某一行,就能定位到META表的Region,定义到Region再从META表的行键找到某一行,找到某一台主机,再找某一个Region,再找Region Server就可以把某一行拿到。这个就是它的寻址——三级机制。寻址的过程,客户端去查数据之后,并不用每次都去找,客户端会把找过一次的路径缓存起来,如果下次找的还是同样的region则直接找region server,因为查数据经常会查一些连续的数据。
Hlog记录了一些对表的最新操作。一个region在region server中存成很多store,一个store对应一个列族。每一个store不光存了文件,还有一个MemStore,会把访问频次较高或最热的数据放在MemStore中。这样查询的时候就不用读取磁盘文件,在内存中就可以。关键是把大量的hot数据放在MemStore中,所以它才能支持高速的随机访问。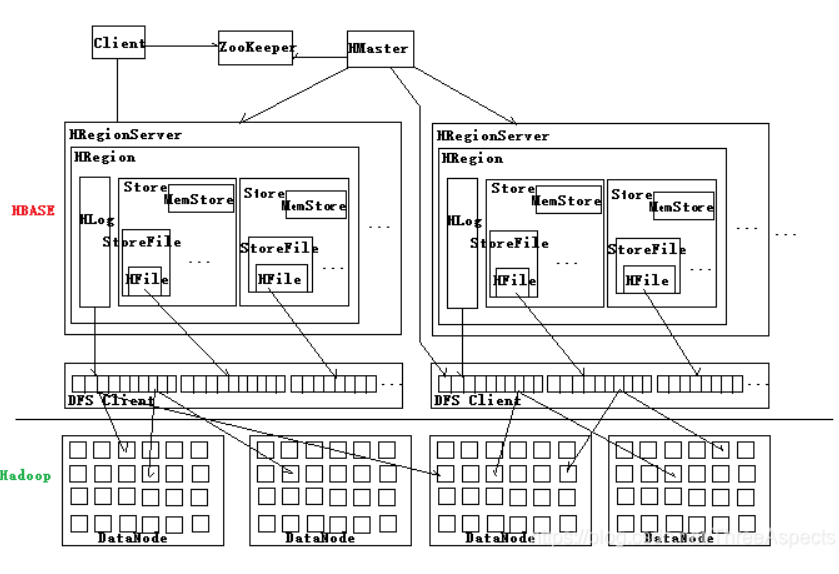
写流程:
1、client向HRegionserver发送写请求
2、HRegionserver将数据写到HBlog(write ahead log)。为了数据的持久化和恢复
3、HRegionserver将数据写到内存(Memstore)
4、反馈client写成功
数据更新过程:
1、当Memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据,并将数据存储到HDFS中
2、在HLog中做标记点
数据合并过程:
1、当数据快达到4块,HMaster将数据块加载到本地,进行合并
2、当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的HRegionServer管理
3、当HRegionServer宕机后,将HRegionServer上的HLog拆分,然后分配给不同的HRegionServer加载,修改_META_
4、注意:HLog会同步到HDFS
HBASE的读流程
1、通过ZooKeeper和_ROOT_,_META_表定位HRegionServer
2、数据从内存和硬盘合并后返回给client
3、数据块会缓存
HMaster的职责是管理用户对Table的增、删、改、查操作;记录region在哪台HRegionServer上;在Region Split后,负责新Region的分配;新机器加入时,管理HRegionServer的负载均衡,调整Regions分布;在HRegionServer宕机后,负责失效HRegionServer上的迁移。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。HRegionServer管理了很多table的分区,也就是region。HBASE client使用HBASE的RPC机制与HMaster和RegionServer进行通信。管理类操作——client与HMaster进行RPC;数据读写类操作:client与HRegionServer进行RPC。
HFile存储格式
HFile是HBase存储数据的文件组织形式。HFile文件的特点:
1)HFile由DataBlock、Meta信息(Index、BloomFilter)、Info等信息组成
2)整个DataBlock由一个或者多个KeyValue组成
3)在文件内按照Key排序
HFile V1的数据组织格式:
HFile内容是按照从上到下的顺序写入的(Data Block、Meta Block、File Info、Data Block Index、Meta Block Index、Fixed File Trailer)。如下图所示: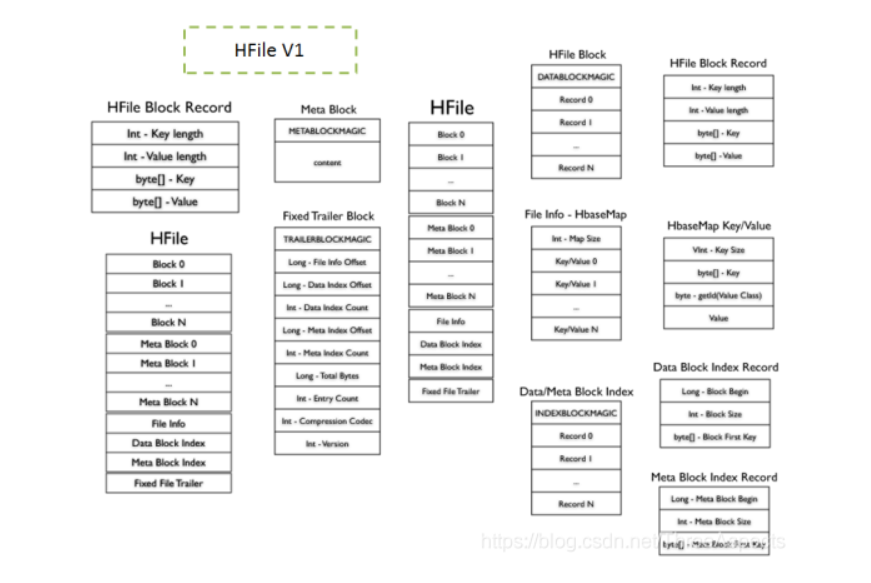
HFile V1的数据格式在0.92版本升级到V2版本,HFile V2的数据组织格式如下图所示: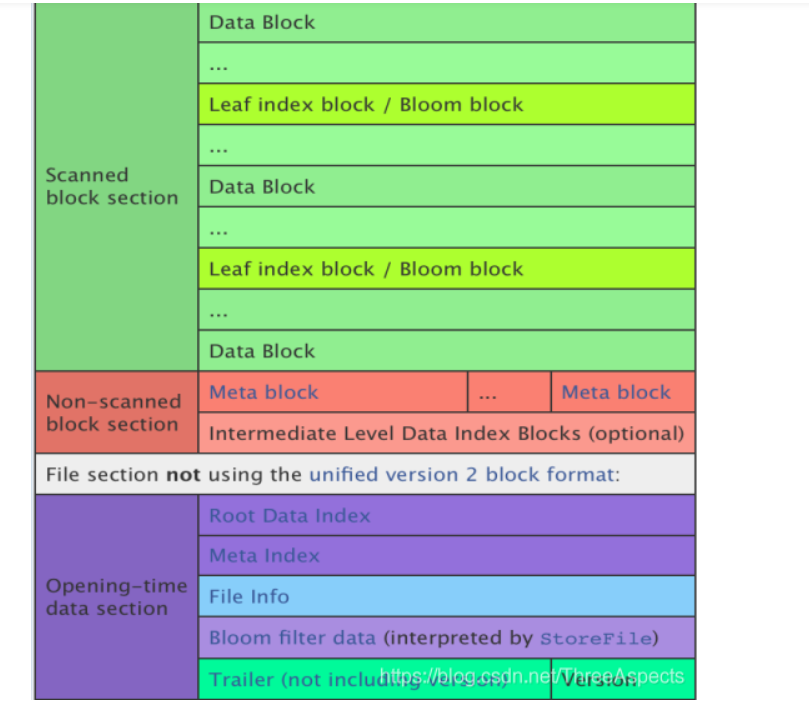
与V1版本的相比,它的区别在于
1)文件分为三部分:Scanned block section,Non-scanned block section以及Opening-time data section
2) 为DataBlockIndex建立多层索引。DataBlockIndex分为Leaf Index Block、Root Data Index,Leaf index block具体存储了DataBlock的offset、length、以及firstkey的信息。RootDataIndex 存储的是每个Leaf index block的offset、length、Leaf index Block记录的第一个key以及截至到该Leaf Index Block记录的DataBlock的个数。假定DataBlock的个数足够多,HFile文件又足够大的情况下,默认的128KB的长度的ROOTDataIndex仍然存在超过chunk大小的情况时,会分成更多的层次。这样最终的可能是ROOT INDEX –> IntermediateLevel ROOT INDEX(可以是多层) —〉Leaf index block
在ROOT INDEX中会记录Mid Key所对应的信息,帮助在做File Split或者折半查询时快速定位中间Row的信息。

