爬虫学习项目:爬取豆瓣电影 TOP250 榜单
该项目使用正则表达式获取豆瓣排行榜信息,将获取到的信息存放在当前目录下的 data.csv 文件中。
一、输出内容
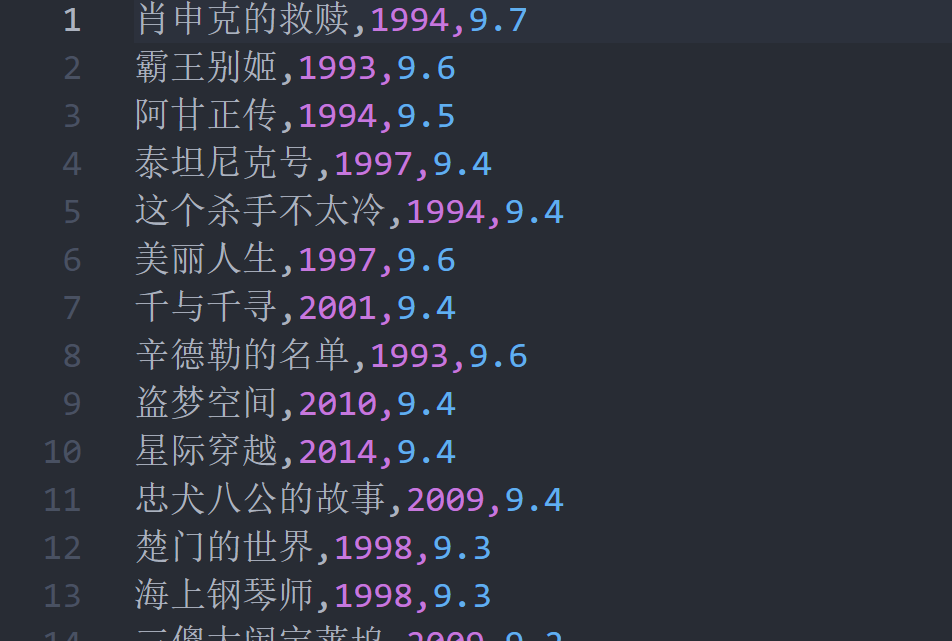
二、代码
import requests # pip install requests
import re
import csv
# 获取数据
def gain_data(url, header):
response = requests.get(url=url, headers=header)
data = response.text
response.close()
return data
# 创建文件
def create_file(data):
# 解析数据
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<br>(?P<year>.*?) .*?"v:average">(?P<score>.*?)</span>', re.S)
result = obj.finditer(data)
# 保存文件
file = open("data.csv", mode='a', encoding='utf-8', newline='')
csv_write = csv.writer(file)
for j in result:
dic = j.groupdict()
dic["year"] = dic["year"].strip()
csv_write.writerow(dic.values())
file.close() # 关闭文件系统
# 主程序
if __name__ == '__main__':
pages = [0, 25, 50, 75, 100, 125, 150, 175, 200, 225]
for page in pages:
web_url = f'https://movie.douban.com/top250?start={page}&filter='
web_header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
web_data = gain_data(web_url, web_header) # 获取数据
create_file(web_data) # 生成文件
print(f"第{int(page/25+1)}页打印完成!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号